【SLAM十四讲】一到十四讲内容大致速通(更新至第二讲)
关于开学了决定不能再摆烂而开始写blog这件事
- 前言 简单的事前提醒
- 第一讲 预备知识
- 第二讲 初识SLAM
-
- 2.1 SLAM框架模块
- 2.2 SLAM问题的数学表述
- 2.3 编程基础
- 第三讲 三维空间刚体运动与Eigen3库
- 第四讲 李群与李代数与Sophus库
- 第五讲 相机与图像与OpenCV库
- 第六讲 非线性优化与Ceres与g2o库
- 第七讲 视觉里程计VO1
-
- 7.1 视觉里程计任务概述
- 7.2 ORB特征的提取与匹配
-
- 7.2.1 Orient FAST角点
- 7.2.2 Rotated BRIEF描述子
前言 简单的事前提醒
由于本文作者也只是在这个领域刚刚起步。所以对本文中的观点,读者应辩证地有思考地看待,并且评论区欢迎不同的意见进行讨论与指正。如果本文对于读者过于简单了,那么CSDN上还有不少大佬的专栏文章可以阅读。比如《视觉SLAM从入门到放弃》(悲)
第一讲 预备知识
我觉得不重要,除非你是在通过自学来决定要不要选择SLAM这个方向。
SLAM是Simultaneous Localization and Mapping的缩写,即同步定位与建图。广义上讲,SLAM任务是指,搭载了传感器的主体,在没有先验信息的环境(即陌生环境)下,于运动过程中建立环境地图,同时估计自己运动(也就是后文中会提到的位姿,代表物体相对于世界坐标系的旋转与位移)。而《SLAM十四讲》中的SLAM,特指视觉SLAM,即只使用相机(camera)作为传感器的SLAM方法。
SLAM方法在《SLAM十四讲》中,程序部分可以分为几个模块:视觉里程计、后端优化、建图以及回环检测。并且会提到一些库的使用代码,其中大部分在现在视觉SLAM的baseline(ORBSLAM3)中仍有使用,Eigen(矩阵计算库)、OpenCV(非常热门的图像处理库)、PCL(点云处理库)、g2o与Ceres(后端优化库)、Pangolin(可视化库)。
关于《SLAM十四讲》的所有源代码都托管在了Github上边,建议在开始的时候将其clone到本地,并且使用Git的submodule功能完成版本控制,保证第三方库可以正常地在代码上运行。
第二讲 初识SLAM
本讲要做以下几件事
1.理解视觉SLAM框架的几个模块,并且了解每个模块的功能。
2.搭建编程环境,为开发做准备。(大概就是准备一下虚拟机和ubuntu,以及一些非常常见的插件(如git和pip之类)
3.理解如何在linux环境下编译并运行一个程序。并且在程序出问题后如何调试它。(因为本书要用cmake做编译,并且一些IDE在对代码进行编译时需要配置非常多东西。)
4.掌握cmake的基本使用方法。(本书的代码都用这个编译)
2.1 SLAM框架模块
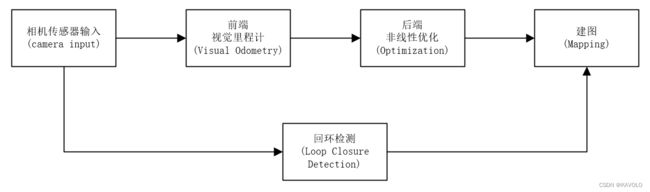
相机输入(camera input)。视觉SLAM中使用的相机大致可分为单目相机(Monocular)、双目相机(Stereo)、深度相机(RGB-D)。Stereo通过对比左右相机的图像来估计物体与相机之间的距离,而RGB-D则可以使用红外结构光(Structured Light)或者飞行时间(Time-of-Flight,ToF)的原理来直接读取每个像素的深度。视觉SLAM中主要使用这两者完成输入任务,因为图像的深度是必要信息,前者计算量复杂,后者则价格昂贵并且体积较大。当然,也有通过深度学习技术,来使得单目相机估计像素深度的研究,但仍有许多问题需要解决。
前端视觉里程计(Visual Odometry,VO)。VO任务要完成相机位姿的估计。在VO部分,SLAM系统会考量多张时间序列上的图片,并且估计每张之间位置的变化,来估计相机的运动,从而得出位姿,即相机坐标系相对于世界坐标系的旋转与位移。但是我们都知道对现实世界的测量往往都会带有误差。在估计位姿时,误差被称为漂移(Drift),并且多次估计后的累计漂移(Accumulating Drift)将会造成严重的误判。这时候就需要后边的两种技术(后端优化与回环检测)来进行解决。
后端非线性优化(Optimization)。笼统的来讲,Optimization主要指处理SLAM过程中产生的噪声,也可以理解为上文中提到的漂移(Drift)。后端要考虑两个主要问题,①如何从带噪声数据中估计整个系统的状态;②这个状态估计的不确定性有多大,即最大后验概率估计(Maximum-a-Posteriori,MAP),这里的状态即包括相机的位姿,也包括地图。也因为这个原因,Optimization在SLAM系统中也被成为后端,相对于前端VO。前端为后端提供预处理过但是仍待优化的数据。后端负责整体的优化,不必关心数据来自什么传感器,也不需要去计算像素深度。在目前视觉SLAM的研究中,前端与计算机视觉研究领域更为相关,比如图像的特征提取与匹配以及图像像素深度的计算与估计。后端任务则是根据状态估计理论,把定位和建图的不确定性量化,再使用滤波与非线性优化算法、来估计状态的均值和不确定性(方差),以这些方法来处理噪声。
回环检测(Loop Closure Detection)。回环检测主要解决位置估计随时间漂移的问题。与后端优化任务目标相同,但是使用的方法有所差异。
我们知道,实际情况下,机器人一般会在经过一段时间的运动后回到了某一个已经经过的点。但是由于漂移(Drift)的影响,此时的位置估计值却没有回到那个点。此时如果有一种手段,让机器人知道“回到了曾经的位置”这件事,或者把“经过点”识别出来,我们再把位置估计值“拉”过去,就可以消除漂移了。这就是所谓的回环检测。
为了让机器人知道自己回到了原点,实现手段有很多,其本质都是让机器人可以识别到过的场景。最简单的便是在环境中设置传感器,但这一方案会对应用场景做出较大的限制。我们更希望机器人能够使用自身携带的传感器就完成这一任务,即使用图像识别这一方法,即让机器人判断两张图像中,两个物体的相似性来实现回环检测。当然这一方案对计算与存储也是一种挑战。
检测到回环后,将“A点与B点是同一点”这一的信息传递给后端优化算法。然后后端会根据这些信息来对轨迹与地图进行调整,以此消除累计漂移,最终得到全局一致的轨迹和地图。
建图(Mapping)。建图是构建地图的过程,地图是对环境的描述。但是在各种SLAM框架中,这个描述并不是固定的,需要视SLAM的应用而定。对于家用扫地机器人这种主要在低矮平面内运动的应用,只需要一个二维地图标记可通过路径与障碍物便足够进行导航。而对于相机,它有6自由度的运动(位移与旋转),我们至少需要一张三维地图。如果想要一个漂亮的重建结果,不仅是一组空间点,还需要带纹理的三角面片。而在自动驾驶领域,甚至可以不需要进行建图,因为可以使用已经绘制好的当地地图。相比于之前提到的VO、Optimization以及回环检测,Mapping并没有一个固定的形式与算法。但大体上仍可以分为度量地图与拓扑地图两种。度量地图又可以分为稀疏Sparse地图(只重构路标Landmark,主要用于定位)与稠密Dense地图(看到的所有都重构,主要用于导航)。拓扑地图则强调地图元素之间的关系,也是图论中一般所指的地图,对地图进行切割,形成节点与边,从而进行导航与路径规划。
2.2 SLAM问题的数学表述
对于SLAM问题,有两个基本方程:

其中(1)式被称为SLAM系统的运动方程,而(2)式被称为观测方程。
对于(1)式, x k x_k xk表示当前位置, x k − 1 x_{k-1} xk−1表示上一位置,而 u k u_k uk表示运动传感器的读数, w k w_k wk为运动过程中加入的噪声。
对于(2)式, z k , j z_{k,j} zk,j表示机器人在位置 x k x_k xk上看到某个路标点 y j y_j yj时视觉传感器产生的观测数据, v k , j v_{k,j} vk,j表示这次观测里的噪声。 O O O表示一个集合,记录了哪个时刻观察到了哪个路标。
这两个方程可以联合起来理解SLAM问题,当我们知道运动读数 u u u以及视觉读数 z z z时,如何求解定位问题(估计 x x x)和建图问题(估计 y y y)?此时SLAM问题就被建模为了一个状态估计问题:如何通过带噪声的测量数据,估计内部的,隐藏着的状态变量?
2.3 编程基础
2.3.1第一部分,Linux系统的安装,略。注意一下版本控制即可,slambook2以Ubuntu18.04为操作平台,并且为其分配至少4GB内存。推荐将其安装在固态硬盘上,并且在按照完成后换成国内的软件源,再将本书的内容clone下来并使用submodule完成第三方库的版本控制。
2.3.2第二部分,使用g++直接编译,略。后边最少都是直接上cmake
2.3.3第三部分,cmake的基本使用。这个简单,照着书抄一下,然后mkdir build,cd build,cmake …,make -j4就完事了。
**2.3.4,cmake中库的使用。**待补充。
**2.3.5,使用IDE进行编译。**待补充。
第三讲 三维空间刚体运动与Eigen3库
主要目标
1.理解三维刚体运动的几种描述方式:旋转矩阵(rotation matrix)、变换矩阵(transformed matrix)、四元数(quaternion)和欧拉角(Euler Angle)。以及这几种描述方式的约束问题。
2.掌握Eigen库的矩阵、几何模块使用方法。
3.了解可视化库pangolin的使用方法。
第四讲 李群与李代数与Sophus库
主要目标
1.理解李群(Lie Group)与李代数(Lie Algebra)的概念,掌握SO(3)、SE(3)与对应李代数的表示方法。
2.理解BCH近似的意义,并了解其在SLAM优化中的作用。
3.学会在李代数上的胶东模型
4.使用Sophus对李代数进行计算
第五讲 相机与图像与OpenCV库
主要目标
1.理解针孔相机模型、内参与径向畸变参数。以及在已知参数的情况下如何使用程序进行去畸变。
2.理解一个空间点是如何投影到相机成像平面的。
3.掌握OpenCV常用的图像存储与表达方式。
4.学会基本的摄像头标定方法。
5.在已知相机内外参,以及像素深度的情况下,建立一张点云地图。
第六讲 非线性优化与Ceres与g2o库
主要目标
1.理解最小二乘法的含义和处理方式。
2.理解高斯牛顿法(Gauss-Newton`s method)、列文伯格-马夸尔特方法(Levenburg-Marquadt`s method)等下降策略。
3.学习Ceres库和g2o库的基本使用方法。
第七讲 视觉里程计VO1
主要目标
1.掌握ORB特征的提取与匹配。
2.了解对极约束(2d-2d点对)恢复相机位姿。
3.了解PnP任务(2d-3d点对)恢复相机位姿。
4.了解ICP任务(3d-3d点对)恢复相机位姿。
5.了解三角测距方法,单目相机通过多视角几何获取物体深度。
7.1 视觉里程计任务概述
视觉里程计VIO在SLAM框架中属于前端部分,主要完成的任务是根据相机的图像输入,完成对相机位姿的初步估计。
其任务的整体流程为,根据相机在多视角下的图像,先提取图像中的特征点(ORB特征关键点提取),然后对不同图像的特征点进行匹配(ORB特征描述子匹配),从而得到同一特征点代表的物体在不同图像下的坐标(2d-2d点对/2d-3d点对/3d-3d点对),最后根据这些坐标来恢复相机位姿(对极约束/PnP/ICP)。
7.2 ORB特征的提取与匹配
在SLAM任务中,ORB(Orient FAST and Rotated BRIEF)特征作为三大经典特征(另外两者是SIFT和SURF)中对于视觉SLAM任务作为广泛应用的特征,其关键点为改良过的FAST角点,描述子为添加了旋转属性的BREIF描述子。
7.2.1 Orient FAST角点
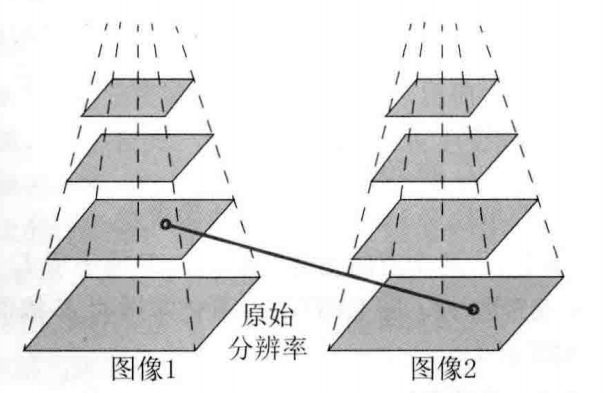
原版的FAST角点以其速度快著称,只关注局部像素灰度变化明显的地方,换句话说,它只关注图像中有明显亮度变化的地方,并且使用预测试和非极大值抑制的方法来加速角点检测速度和避免角点集中的问题。而ORB特征改良的Orient FAST角点则增添了对尺度和旋转的描述。尺度不变性通过构造图像金字塔,并在金字塔的每一层上检测角点来实现。而旋转性质则通过使用矩计算图像灰度质心,再将几何质心与图像质心相连来得到特征点的方向。
7.2.2 Rotated BRIEF描述子
BRIEF是一种二进制描述子,其描述向量由许多个0和1组成,这里的0和1代表取关键点附近的一对随机像素(比如p和q),如果p比q大,则取1,反之就取0。如果想建立一个128维(128bit)的BRIEF描述子,那么就会在关键点附近随机地取128对像素点进行大小比较。因为ORB特征在提取阶段计算了关键点方向,可以利用方向信息来计算旋转后的“Steer BRIEF”特征,使得ORB的描述子具有良好的旋转不变性。