pytorch学习笔记:task01-task04
pytorch学习笔记
- Task01 pytorch安装
- Task02 PyTorch基础知识
-
- 1、张量
-
- (1)简介
- (2)常见的构造Tensor的函数
- (3)常见操作
- (4)广播机制
- 2、自动求导
-
- (1)autograd简介
- (2)梯度
- 3、并行计算
-
- why
- cuda
- how
- Task03 PyTorch的主要组成模块
-
- 1 深度学习流程
- 2 基本配置
-
- (1)导入包
- (2)参数设置
- 3 数据读入
-
- (1)主要函数
- (2)构建Dataset--例子1
- (3)构建Dataset--例子2
- (4)借助DataLoader按批读入数据
- 4 模型构建
-
- (1)神经网络的构造
- (2)神经网络中常见的层
- (3) 模型示例
-
- LeNet
- AlexNet
- 5 损失函数
- 6 优化器
- 7 训练与评估
- 8 可视化
- Task04
Task01 pytorch安装
1、安装注意:
电脑已配置anaconda,为了方便安装pycharm,并配置好环境。
按照教程配置cuda、pytorch等
Task02 PyTorch基础知识
1、张量
(1)简介
- 0维张量又称标量 ,是一个数字
- 1维张量又称向量
- 2维张量又称矩阵
- 3维张量 包括时间序列数据 股价 文本数据 彩色图片(RGB)等
(2)常见的构造Tensor的函数
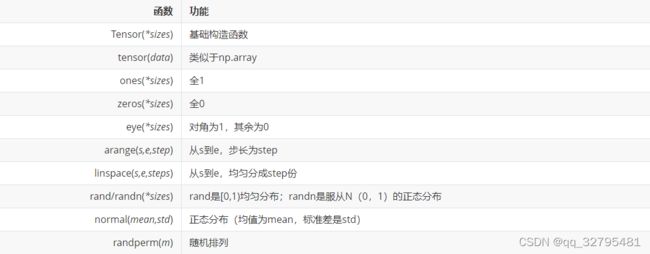
(3)常见操作
-
加法操作:torch.add(x, y)
-
索引操作:(类似于numpy)
注意: 索引出来的结果与原数据共享内存,也即修改一个,另一个会跟着修改 -
改变大小: torch.view、reshape
- view:** view()返回的新tenso与源tensor共享内存(其实是同一个tensor),也即更改其中的一个,另 外一个也会跟着改变。(顾名思义,view仅仅是改变了对这个张量的观察⻆度)
- reshape:如果我们想返回一个真正新的副本(即不共享内存)该怎么办呢?Pytorch还提供了一 个 reshape() 可以改变形状,但是此函数并不能保证返回的是其拷贝,所以不推荐使用。推荐先用 clone 创造一个副本然后再使用 view。
除此之外,使用 clone 还有一个好处是会被记录在计算图中,即梯度回传到副本时也会传到源 Tensor
-
获得元素值:x.item() 来获得x的value
-
Tensor 支持超过一百种操作,转置、索引、切片、数学运算、线性代数、随机数等等,详见官方文档
**
(4)广播机制
当对两个形状不同的 Tensor 按元素运算时,可能会触发广播(broadcasting)机制:先适当复制元素使这两个 Tensor 形状相同后再按元素运算
x = torch.arange(1, 3).view(1, 2)
print(x)
y = torch.arange(1, 4).view(3, 1)
print(y)
print(x + y)
由于 x 和 y 分别是1行2列和3行1列的矩阵,如果要计算 x + y ,那么 x 中第一行的2个元素被广播 (复制)到了第二行和第三行,⽽ y 中第⼀列的3个元素被广播(复制)到了第二列。如此,就可以对2 个3行2列的矩阵按元素相加。
2、自动求导
(1)autograd简介
PyTorch 中,所有神经网络的核心是 autograd 包。autograd包为张量上的所有操作提供了自动求导机制。它是一个在运行时定义 ( define-by-run )的框架,这意味着反向传播是根据代码如何运行来决定的,并且每次迭代可以是不同的。
torch.Tensor是这个包的核心类。如果设置它的属性**.requires_grad** 为 True,那么它将会追踪对于该张量的所有操作。当完成计算后可以通过调用** .backward(),来自动计算所有的梯度。这个张量的所有梯度将会自动累加到.grad**属性。
注意:在 y.backward() 时,如果 y 是标量,则不需要为 backward() 传入任何参数;否则,需要传入一个与 y 同形的Tensor,指定一个gradient参数,该参数是形状匹配的张量。
要阻止一个张量被跟踪历史,可以调用**.detach() **方法将其与计算历史分离,并阻止它未来的计算记录被跟踪。为了防止跟踪历史记录(和使用内存),可以将代码块包装在 **with torch.no_grad()*中。在评估模型时特别有用,因为模型可能具有 requires_grad = True 的可训练的参数,但是我们不需要在此过程中对他们进行梯度计算。
还有一个类对于autograd的实现非常重要:Function。Tensor和Function 互相连接生成了一个无环图 (acyclic graph),它编码了完整的计算历史。每个张量都有一个** .grad_fn属性,该属性引用了创建 Tensor自身的Function**(除非这个张量是用户手动创建的,即这个张量的** grad_fn是None** )。下面给出的例子中,张量由用户手动创建,因此grad_fn返回结果是None。
(2)梯度

3、并行计算
why
在利用PyTorch做深度学习的过程中,可能会遇到数据量较大无法在单块GPU上完成,或者需要提升计算速度的场景,这时就需要用到并行计算。本节让我们来简单地了解一下并行计算的基本概念和主要实现方式,具体的内容会在课程的第二部分详细介绍
目的就是编写我们自己的框架,来完成特定的任务。可以说,在深度学习时代,GPU的出现让我们可以训练的更快,更好。所以,如何充分利用GPU的性能来提高我们模型学习的效果,这一技能是我们必须要学习的。这一节,我们主要讲的就是PyTorch的并行计算。PyTorch可以在编写完模型之后,让多个GPU来参与训练
cuda
CUDA是我们使用GPU的提供商——NVIDIA提供的GPU并行计算框架。对于GPU本身的编程,使用的是CUDA语言来实现的。但是,在我们使用PyTorch编写深度学习代码时,使用的CUDA又是另一个意思。在PyTorch使用 CUDA表示要开始要求我们的模型或者数据开始使用GPU了。
在编写程序中,当我们使用了 cuda() 时,其功能是让我们的模型或者数据迁移到GPU当中,通过GPU开始计算
how
- 网络结构分布到不同的设备中(Network partitioning)
将一个模型的各个部分拆分,然后将不同的部分放入到GPU来做不同任务的计算: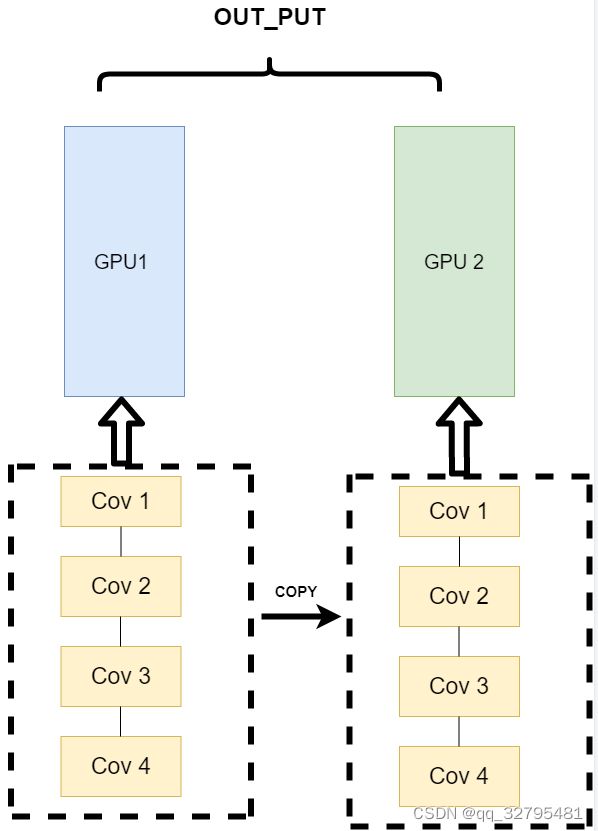
- 同一层的任务分布到不同数据中(Layer-wise partitioning)

- 不同的数据分布到不同的设备中,执行相同的任务(Data parallelism)
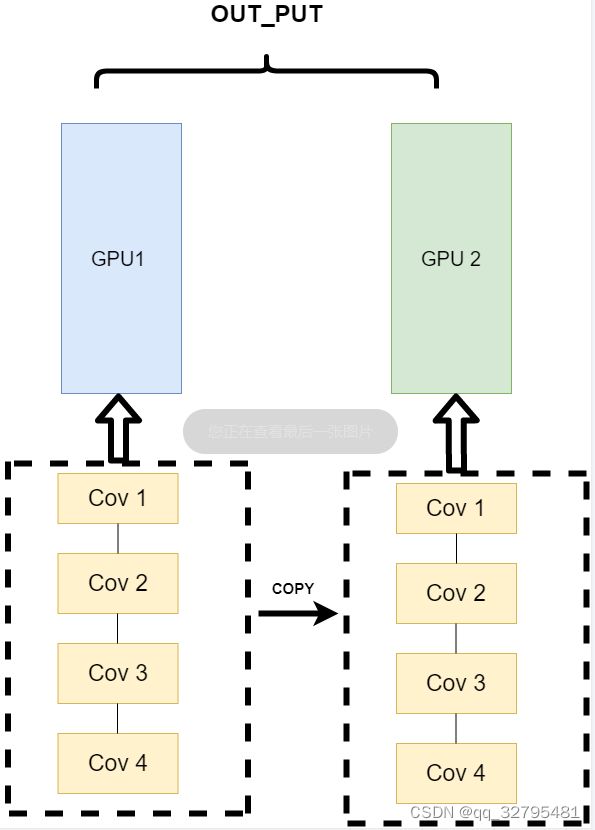
PS:现在的主流方式是数据并行的方式(Data parallelism)
Task03 PyTorch的主要组成模块
1 深度学习流程
机器学习任务时的步骤,首先需要对数据进行预处理,其中重要的步骤包括数据格式的统一和必要的数据变换,同时划分训练集和测试集。接下来选择模型,并设定损失函数和优化函数,以及对应的超参数(当然可以使用sklearn这样的机器学习库中模型自带的损失函数和优化器)。最后用模型去拟合训练集数据,并在验证集/测试集上计算模型表现。
深度学习和机器学习在流程上类似,但在代码实现上有较大的差异。首先,由于深度学习所需的样本量很大,一次加载全部数据运行可能会超出内存容量而无法实现;同时还有批(batch)训练等提高模型表现的策略,需要每次训练读取固定数量的样本送入模型中训练,因此深度学习在数据加载上需要有专门的设计。
在模型实现上,深度学习和机器学习也有很大差异。由于深度神经网络层数往往较多,同时会有一些用于实现特定功能的层(如卷积层、池化层、批正则化层、LSTM层等),因此深度神经网络往往需要“逐层”搭建,或者预先定义好可以实现特定功能的模块,再把这些模块组装起来。这种“定制化”的模型构建方式能够充分保证模型的灵活性,也对代码实现提出了新的要求。
接下来是损失函数和优化器的设定。这部分和经典机器学习的实现是类似的。但由于模型设定的灵活性,因此损失函数和优化器要能够保证反向传播能够在用户自行定义的模型结构上实现。
上述步骤完成后就可以开始训练了。我们前面介绍了GPU的概念和GPU用于并行计算加速的功能,不过程序默认是在CPU上运行的,因此在代码实现中,需要把模型和数据“放到”GPU上去做运算,同时还需要保证损失函数和优化器能够在GPU上工作。如果使用多张GPU进行训练,还需要考虑模型和数据分配、整合的问题。此外,后续计算一些指标还需要把数据“放回”CPU。这里涉及到了一系列有关于GPU的配置和操作。
深度学习中训练和验证过程最大的特点在于读入数据是按批的,每次读入一个批次的数据,放入GPU中训练,然后将损失函数反向传播回网络最前面的层,同时使用优化器调整网络参数。这里会涉及到各个模块配合的问题。训练/验证后还需要根据设定好的指标计算模型表现。
经过以上步骤,一个深度学习任务就完成了。我们在详细讲解每个部分之前,先梳理了完成各个部分所需的功能,下面我们就去进一步了解一下PyTorch是如何实现各个部分的,以及PyTorch作为一个深度学习框架拥有的模块化特点
2 基本配置
(1)导入包
对于一个PyTorch项目,我们需要导入一些Python常用的包来帮助我们快速实现功能。常见的包有os、numpy等,此外还需要调用PyTorch自身一些模块便于灵活使用,比如torch、torch.nn、torch.utils.data.Dataset、torch.utils.data.DataLoader、torch.optimizer等等。
涉及到表格信息的读入很可能用到pandas,对于不同的项目可能还需要导入一些更上层的包如cv2等。如果涉及可视化还会用到matplotlib、seaborn等。涉及到下游分析和指标计算也常用到sklearn。
import os
import numpy as np
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader
import torch.optim as optimizer
(2)参数设置
根据前面我们对深度学习任务的梳理,有如下几个超参数可以统一设置,方便后续调试时修改:
- batch size
- 初始学习率(初始)
- 训练次数(max_epochs)
- GPU配置:有两种方式:os.environ;device
# 方案一:使用os.environ,这种情况如果使用GPU不需要设置
os.environ['CUDA_VISIBLE_DEVICES'] = '0,1'
# 方案二:使用“device”,后续对要使用GPU的变量用.to(device)即可
device = torch.device("cuda:1" if torch.cuda.is_available() else "cpu")
其他模块或用户自定义模块会用到的参数,有需要也可以在一开始进行设置。
3 数据读入
(1)主要函数
PyTorch数据读入是通过Dataset+DataLoader的方式完成的,Dataset定义好数据的格式和数据变换形式,DataLoader用iterative的方式不断读入批次数据。
我们可以定义自己的Dataset类来实现灵活的数据读取,定义的类需要继承PyTorch自身的Dataset类。主要包含三个函数:
- init: 用于向类中传入外部参数,同时定义样本集
- getitem: 用于逐个读取样本集合中的元素,可以进行一定的变换,并将返回训练/验证所需的数据
- len: 用于返回数据集的样本数
(2)构建Dataset–例子1
以cifar10数据集为例给出构建Dataset类的方式:
train_data = datasets.ImageFolder(train_path, transform=data_transform)
val_data = datasets.ImageFolder(val_path, transform=data_transform)
这里使用了PyTorch自带的ImageFolder类的用于读取按一定结构存储的图片数据(path对应图片存放的目录,目录下包含若干子目录,每个子目录对应属于同一个类的图片)。
其中“data_transform”可以对图像进行一定的变换,如翻转、裁剪等操作,可自己定义。这里我们会在下一章通过实战加以介绍。
(3)构建Dataset–例子2
给出一个例子,其中图片存放在一个文件夹,另外有一个csv文件给出了图片名称对应的标签。这种情况下需要自己来定义Dataset类
class MyDataset(Dataset):
def __init__(self, data_dir, info_csv, image_list, transform=None):
"""
Args:
data_dir: path to image directory.
info_csv: path to the csv file containing image indexes
with corresponding labels.
image_list: path to the txt file contains image names to training/validation set
transform: optional transform to be applied on a sample.
"""
label_info = pd.read_csv(info_csv)
image_file = open(image_list).readlines()
self.data_dir = data_dir
self.image_file = image_file
self.label_info = label_info
self.transform = transform
def __getitem__(self, index):
"""
Args:
index: the index of item
Returns:
image and its labels
"""
image_name = self.image_file[index].strip('\n')
raw_label = self.label_info.loc[self.label_info['Image_index'] == image_name]
label = raw_label.iloc[:,0]
image_name = os.path.join(self.data_dir, image_name)
image = Image.open(image_name).convert('RGB')
if self.transform is not None:
image = self.transform(image)
return image, label
def __len__(self):
return len(self.image_file)
(4)借助DataLoader按批读入数据
构建好Dataset后,就可以使用DataLoader来按批次读入数据了,实现代码如下:
train_loader = torch.utils.data.DataLoader(train_data, batch_size=batch_size, num_workers=4, shuffle=True, drop_last=True)
val_loader = torch.utils.data.DataLoader(val_data, batch_size=batch_size, num_workers=4, shuffle=False)
其中:
- batch_size:样本是按“批”读入的,batch_size就是每次读入的样本数
- num_workers:有多少个进程用于读取数据
- shuffle:是否将读入的数据打乱
- drop_last:对于样本最后一部分没有达到批次数的样本,使其不再参与训练
这里可以看一下我们的加载的数据。PyTorch中的DataLoader的读取可以使用next和iter来完成
import matplotlib.pyplot as plt
images, labels = next(iter(val_loader))
print(images.shape)
plt.imshow(images[0].transpose(1,2,0))
plt.show()
4 模型构建
(1)神经网络的构造
PyTorch中神经网络构造一般是基于 Module 类的模型来完成的,它让模型构造更加灵活。
Module 类是 nn 模块里提供的一个模型构造类,是所有神经⽹网络模块的基类,我们可以继承它来定义我们想要的模型。下面继承 Module 类构造多层感知机。这里定义的 MLP 类重载了 Module 类的 init 函数和 forward 函数。它们分别用于创建模型参数和定义前向计算。前向计算也即正向传播。
import torch
from torch import nn
class MLP(nn.Module):
# 声明带有模型参数的层,这里声明了两个全连接层
def __init__(self, **kwargs):
# 调用MLP父类Block的构造函数来进行必要的初始化。这样在构造实例时还可以指定其他函数
super(MLP, self).__init__(**kwargs)
self.hidden = nn.Linear(784, 256)
self.act = nn.ReLU()
self.output = nn.Linear(256,10)
# 定义模型的前向计算,即如何根据输入x计算返回所需要的模型输出
def forward(self, x):
o = self.act(self.hidden(x))
return self.output(o)
以上的 MLP 类中⽆须定义反向传播函数。系统将通过⾃动求梯度⽽自动⽣成反向传播所需的 backward 函数。
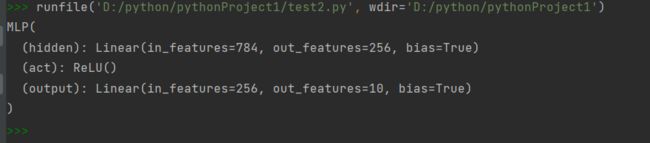
我们可以实例化 MLP 类得到模型变量 net 。下⾯的代码初始化 net 并传入输⼊数据 X 做一次前向计算。其中, net(X) 会调用 MLP 继承⾃自 Module 类的 call 函数,这个函数将调⽤用 MLP 类定义的forward 函数来完成前向计算
X = torch.rand(2,784)
net = MLP()
print(net)
net(X)
注意,这里并没有将 Module 类命名为 Layer (层)或者 Model (模型)之类的名字,这是因为该类是一个可供⾃由组建的部件。它的子类既可以是⼀个层(如PyTorch提供的 Linear 类),⼜可以是一个模型(如这里定义的 MLP 类),或者是模型的⼀个部分
(2)神经网络中常见的层
深度学习的一个魅力在于神经网络中各式各样的层,例如全连接层、卷积层、池化层与循环层等等。虽然PyTorch提供了⼤量常用的层,但有时候我们依然希望⾃定义层。这里我们会介绍如何使用 Module 来自定义层,从而可以被反复调用
- 不含模型参数的层
定义一个不含模型参数的自定义层。下⾯构造的 MyLayer 类通过继承 Module 类自定义了一个将输入减掉均值后输出的层,并将层的计算定义在了 forward 函数里。这个层里不含模型参数
import torch
from torch import nn
class MyLayer(nn.Module):
def __init__(self, **kwargs):
super(MyLayer, self).__init__(**kwargs)
def forward(self, x):
return x - x.mean()
测试,实例化该层,然后做前向计算
layer = MyLayer()
layer(torch.tensor([1, 2, 3, 4, 5], dtype=torch.float))
- 含模型参数的层
我们还可以自定义含模型参数的自定义层。其中的模型参数可以通过训练学出。
Parameter 类其实是 Tensor 的子类,如果一 个 Tensor 是 Parameter ,那么它会⾃动被添加到模型的参数列表里。所以在⾃定义含模型参数的层时,我们应该将参数定义成 Parameter ,除了直接定义成 Parameter 类外,还可以使⽤ ParameterList 和 ParameterDict 分别定义参数的列表和字典
class MyListDense(nn.Module):
def __init__(self):
super(MyListDense, self).__init__()
self.params = nn.ParameterList([nn.Parameter(torch.randn(4, 4)) for i in range(3)])
self.params.append(nn.Parameter(torch.randn(4, 1)))
def forward(self, x):
for i in range(len(self.params)):
x = torch.mm(x, self.params[i])
return x
net = MyListDense()
print(net)
class MyDictDense(nn.Module):
def __init__(self):
super(MyDictDense, self).__init__()
self.params = nn.ParameterDict({
'linear1': nn.Parameter(torch.randn(4, 4)),
'linear2': nn.Parameter(torch.randn(4, 1))
})
self.params.update({'linear3': nn.Parameter(torch.randn(4, 2))}) # 新增
def forward(self, x, choice='linear1'):
return torch.mm(x, self.params[choice])
net = MyDictDense()
print(net)
下面给出常见的神经网络的一些层,比如卷积层、池化层,以及较为基础的AlexNet,LeNet等。
- 二维卷积层
二维卷积层将输入和卷积核做互相关运算,并加上一个标量偏差来得到输出。卷积层的模型参数包括了卷积核和标量偏差。在训练模型的时候,通常我们先对卷积核随机初始化,然后不断迭代卷积核和偏差
import torch
from torch import nn
# 卷积运算(二维互相关)
def corr2d(X, K):
h, w = K.shape
X, K = X.float(), K.float()
Y = torch.zeros((X.shape[0] - h + 1, X.shape[1] - w + 1))
for i in range(Y.shape[0]):
for j in range(Y.shape[1]):
Y[i, j] = (X[i: i + h, j: j + w] * K).sum()
return Y
# 二维卷积层
class Conv2D(nn.Module):
def __init__(self, kernel_size):
super(Conv2D, self).__init__()
self.weight = nn.Parameter(torch.randn(kernel_size))
self.bias = nn.Parameter(torch.randn(1))
def forward(self, x):
return corr2d(x, self.weight) + self.bias
卷积窗口形状为 p × q p \times q p×q 的卷积层称为 p × q p \times q p×q 卷积层。同样, p × q p \times q p×q 卷积或 p × q p \times q p×q 卷积核说明卷积核的高和宽分别为 p p p 和 q q q。
填充(padding)是指在输⼊高和宽的两侧填充元素(通常是0元素)。
下面的例子里我们创建一个⾼和宽为3的二维卷积层,然后设输⼊高和宽两侧的填充数分别为1。给定一 个高和宽为8的输入,我们发现输出的高和宽也是8。
import torch
from torch import nn
# 定义一个函数来计算卷积层。它对输入和输出做相应的升维和降维
def comp_conv2d(conv2d, X):
# (1, 1)代表批量大小和通道数
X = X.view((1, 1) + X.shape)
Y = conv2d(X)
return Y.view(Y.shape[2:]) # 排除不关心的前两维:批量和通道
# 注意这里是两侧分别填充1⾏或列,所以在两侧一共填充2⾏或列
conv2d = nn.Conv2d(in_channels=1, out_channels=1, kernel_size=3,padding=1)
X = torch.rand(8, 8)
comp_conv2d(conv2d, X).shape
当卷积核的高和宽不同时,我们也可以通过设置高和宽上不同的填充数使输出和输入具有相同的高和宽
# 使用高为5、宽为3的卷积核。在⾼和宽两侧的填充数分别为2和1
conv2d = nn.Conv2d(in_channels=1, out_channels=1, kernel_size=(5, 3), padding=(2, 1))
comp_conv2d(conv2d, X).shape
在二维互相关运算中,卷积窗口从输入数组的最左上方开始,按从左往右、从上往下 的顺序,依次在输⼊数组上滑动。我们将每次滑动的行数和列数称为步幅(stride)。
conv2d = nn.Conv2d(1, 1, kernel_size=(3, 5), padding=(0, 1), stride=(3, 4))
comp_conv2d(conv2d, X).shape
填充可以增加输出的高和宽。这常用来使输出与输入具有相同的高和宽。
步幅可以减小输出的高和宽,例如输出的高和宽仅为输入的高和宽的 ( 为大于1的整数)。
- 池化层
池化层每次对输入数据的一个固定形状窗口(⼜称池化窗口)中的元素计算输出。不同于卷积层里计算输⼊和核的互相关性,池化层直接计算池化窗口内元素的最大值或者平均值。该运算也 分别叫做最大池化或平均池化。在二维最⼤池化中,池化窗口从输入数组的最左上方开始,按从左往右、从上往下的顺序,依次在输⼊数组上滑动。当池化窗口滑动到某⼀位置时,窗口中的输入子数组的最大值即输出数组中相应位置的元素。
下面把池化层的前向计算实现在pool2d函数里
import torch
from torch import nn
def pool2d(X, pool_size, mode='max'):
p_h, p_w = pool_size
Y = torch.zeros((X.shape[0] - p_h + 1, X.shape[1] - p_w + 1))
for i in range(Y.shape[0]):
for j in range(Y.shape[1]):
if mode == 'max':
Y[i, j] = X[i: i + p_h, j: j + p_w].max()
elif mode == 'avg':
Y[i, j] = X[i: i + p_h, j: j + p_w].mean()
return Y
X = torch.tensor([[0, 1, 2], [3, 4, 5], [6, 7, 8]], dtype=torch.float)
pool2d(X, (2, 2))
, 'avg')

我们可以使用torch.nn包来构建神经网络。我们已经介绍了autograd包,nn包则依赖于autograd包来定义模型并对它们求导。一个nn.Module包含各个层和一个forward(input)方法,该方法返回output。