python爬取网易云飙升榜数据
首先,我们打开网易云网页版,击排行榜,然后点击左侧云音乐飙升榜,如图:
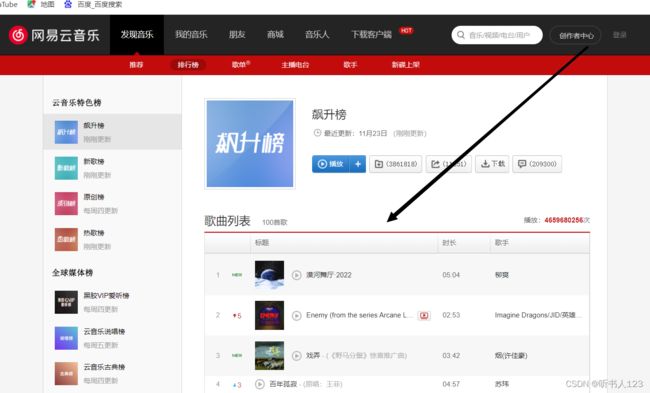
使用开发者工具找到我们需要的数据:



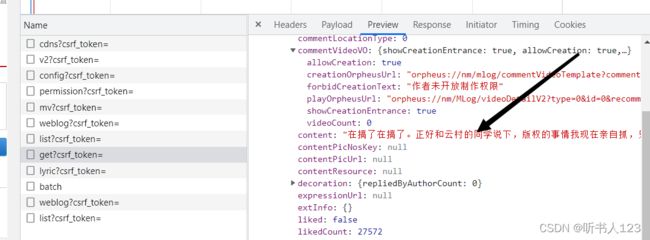
源码:
import requests
from lxml import etree
import re
import json
import urllib
import xlwt
import csv
url = "https://music.163.com/discover/toplist?id=19723756"
headers = {'user-agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'}
workbook=xlwt.Workbook(encoding='utf-8')
globals()
wooksheet=workbook.add_sheet('歌曲')
wooksheet.write(0,0,'歌曲名')
wooksheet.write(0,1,'歌手名')
wooksheet.write(0,2,'专辑名')
wooksheet.write(0,3,'歌词')
wooksheet.write(0,4,'评论')
response = requests.get(url,headers=headers)
html = etree.HTML(response.text)
ids = html.xpath('//ul[@class="f-hide"]//a/@href')
for i in range(len(ids)):
ids[i] = re.sub('\D', '', ids[i])
# print(ids)
# list=[]
for i in range(len(ids)):
music_url = f"https://music.163.com/song?id={ids[i]}"
response = requests.get(music_url,headers=headers)
html = etree.HTML(response.text)
music_info = html.xpath('//title/text()')
ly=f'http://music.163.com/api/song/lyric?' + 'id=' + str(ids[i]) + '&lv=1&kv=1&tv=-1'
res=requests.get(ly,headers=headers)
json_obj=res.text
j=json.loads(json_obj)
lrc=j['lrc']['lyric']
pat=re.compile(r'\[.*\]')
lrc=re.sub(pat,"",lrc)
lrc=lrc.strip()
rl = 'http://music.163.com/weapi/v1/resource/comments/R_SO_4_' + ids[i] + '?csrf_token='
data = {
'params': 'zC7fzWBKxxsm6TZ3PiRjd056g9iGHtbtc8vjTpBXshKIboaPnUyAXKze+KNi9QiEz/IieyRnZfNztp7yvTFyBXOlVQP/JdYNZw2+GRQDg7grOR2ZjroqoOU2z0TNhy+qDHKSV8ZXOnxUF93w3DA51ADDQHB0IngL+v6N8KthdVZeZBe0d3EsUFS8ZJltNRUJ',
'encSecKey': '4801507e42c326dfc6b50539395a4fe417594f7cf122cf3d061d1447372ba3aa804541a8ae3b3811c081eb0f2b71827850af59af411a10a1795f7a16a5189d163bc9f67b3d1907f5e6fac652f7ef66e5a1f12d6949be851fcf4f39a0c2379580a040dc53b306d5c807bf313cc0e8f39bf7d35de691c497cda1d436b808549acc'}
postdata = urllib.parse.urlencode(data).encode('utf8') # 进行编码
request = urllib.request.Request(rl, headers=headers, data=postdata)
reponse = urllib.request.urlopen(request).read().decode('utf8')
json_dict = json.loads(reponse) # 获取json
hot_commit = json_dict['hotComments']
music_name = music_info[0].split('-')[0]
singer=music_info[0].split('-')[1]
dis = html.xpath("//div[@class='cnt']//p[@class='des s-fc4']//a/@href")
for a in range(len(dis)):
dis[a] = re.sub('\D', '', dis[a])
isd=dis[1]
result= isd.split('\n')
uli=[]
for c in range(len(result)):
music_albums = f"https://music.163.com/album?id={result[c]}"
rse=requests.get(music_albums,headers=headers)
html = etree.HTML(rse.text)
album=html.xpath("//h2/text()")
wooksheet.write(i+1,2,album)
for item in hot_commit:
# list.append(item['content'])
mi=item['content']
wooksheet.write(i+1,0,music_name)
wooksheet.write(i+1,1,singer)
wooksheet.write(i+1,3,lrc)
wooksheet.write(i+1,4,mi)
workbook.save(r'C:\Users\8615\Desktop\song.xls')
try:
print('正在下载', music_name)
urllib.request.urlretrieve(music_url, './%s.mp3' % music_name)
print('下载成功')
except:
print('下载失败')
Pycharm运行结果
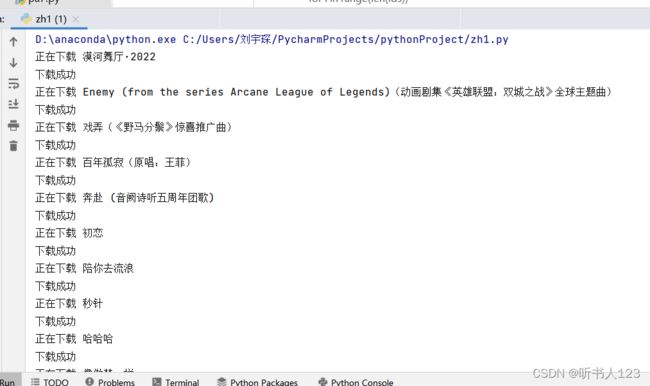
爬取到的名字、歌手、所属专辑、歌词、歌曲、评论信息保存到csv文件中

下载到的歌曲文件
