【Keras+计算机视觉+Tensorflow】DCGAN对抗生成网络在MNIST手写数据集上实战(附源码和数据集 超详细)
需要源码和数据集请点赞关注收藏后评论区留言私信~~~
一、生成对抗网络的概念
生成对抗网络(GANs,Generative Adversarial Nets),由Ian Goodfellow在2014年提出的,是当今计算机科学中最有趣的概念之一。GAN最早提出是为了弥补真实数据的不足,生成高质量的人工数据。GAN的主要思想是通过两个模型的对抗性训练。随着训练过程的推进,生成网络(Generator,G)逐渐变得擅长创建看起来真实的图像,而判别网络(Discriminator,D)则变得更擅长区分真实图像和生成器生成的图像。GAN网络不局限于提高单一网络的性能,而是希望实现生成器和鉴别器之间的纳什均衡。
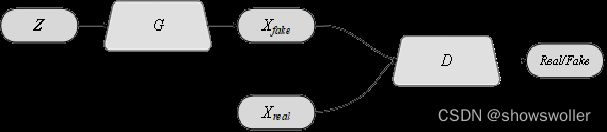
假设在低维空间Z存在一个简单容易采样的分布p(z),例如正态分布 ,生成网络构成一个映射函数G:Z→X,判别网络需要判别输入是来自真实数据X_real还是生成网络生成的数据X_fake,结构示意图如图8-1所示

下面给出DCGAN利用LSUN数据库生成卧室样本的例子和生成人脸样本的例子,虽然DCGAN还难以生成高精度的图像样本,但这样的结果已经足够让世人感到惊艳


二、DCGAN在MNIST手写数据集上实战
通过本程序可以完成两个模型的训练。一个是生成模型,一个是判别模型
1:项目结构如下
代码大致可以分为以下几部分
1:构建生成网络
2:构建判别网络
3:DCGAN网络训练
开始下载模型

2:效果展示
生成图片如下 可以说效果十分逼真
这是第一张生成图片 可以看出里面有些字体还是略微不够真实,容易被判别器鉴别出来

这一张是图片生成的十分逼真,几乎没有什么缺点

三、代码
部分代码如下 全部代码和数据集请点赞关注收藏后评论区留言私信~~~
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import Reshape
from keras.layers.core import Activation
from tensorflow.python.keras.layers import BatchNormalization
from keras.layers.convolutional import UpSampling2D
from keras.layers.convolutional import Conv2D, MaxPooling2D
from keras.layers.core import Flatten
from tensorflow.keras.optimizers import SGD
from keras.datasets import mnist
import numpy as np
from PIL import Image
import argparse
import math
def generator_model():
model = Sequential()
model.add(Dense(input_dim=100, units=1024))
model.add(Activation('tanh'))
model.add(Dense(128*7*7))
model.add(BatchNormalization())
model.add(Activation('tanh'))
model.add(Reshape((7, 7, 128), input_shape=(128*7*7,)))
model.add(UpSampling2D(size=(2, 2)))
model.add(Conv2D(64, (5, 5), padding='same'))
model.add(Activation('tanh'))
model.add(UpSampling2D(size=(2, 2)))
model.add(Conv2D(1, (5, 5), padding='same'))
model.add(Activation('tanh'))
return model
def discriminator_model():
model = Sequential()
model.add(
Conv2D(64, (5, 5),
padding='same',
input_shape=(28, 28, 1))
)
model.add(Activation('tanh'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(128, (5, 5)))
model.add(Activation('tanh'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(1024))
model.add(Activation('tanh'))
model.add(Dense(1))
model.add(Activation('sigmoid'))
return model
def generator_containing_discriminator(g, d):
model = Sequential()
model.add(g)
d.trainable = False
model.add(d)
return model
def combine_images(generated_images):
num = generated_images.shape[0]
width = int(math.sqrt(num))
height = int(math.ceil(float(num)/width))
shape = generated_images.shape[1:3]
image = np.zeros((height*shape[0], width*shape[1]),
dtype=generated_images.dtype)
for index, img in enumerate(generated_images):
i = int(index/width)
j = index % width
image[i*shape[0]:(i+1)*shape[0], j*shape[1]:(j+1)*shape[1]] = \
img[:, :, 0]
return image
def train(BATCH_SIZE,path):
(X_train, y_train), (X_test, y_test) = mnist.load_data()
X_train = (X_train.astype(np.float32) - 127.5)/127.5
X_train = X_train[:, :, :, None]
X_test = X_test[:, :, :, None]
# X_train = X_train.reshape((X_train.shape, 1) + X_train.shape[1:])
d = discriminator_model()
g = generator_model()
d_on_g = generator_containing_discriminator(g, d)
d_optim = SGD(lr=0.0005, momentum=0.9, nesterov=True)
g_optim = SGD(lr=0.0005, momentum=0.9, nesterov=True)
g.compile(loss='binary_crossentropy', optimizer="SGD")
d_on_g.compile(loss='binary_crossentropy', optimizer=g_optim)
d.trainable = True
d.compile(loss='binary_crossentropy', optimizer=d_optim)
for epoch in range(100):
print("Epoch is", epoch)
print("Number of batches", int(X_train.shape[0]/BATCH_SIZE))
for index in range(int(X_train.shape[0]/BATCH_SIZE)):
noise = np.random.uniform(-1, 1, size=(BATCH_SIZE, 100))
image_batch = X_train[index*BATCH_SIZE:(index+1)*BATCH_SIZE]
generated_images = g.predict(noise, verbose=0)
if index % 20 == 0:
image = combine_images(generated_images)
image = image*127.5+127.5
Image.fromarray(image.astype(np.uint8)).save(
str(epoch)+"_"+str(index)+".png")
X = np.concatenate((image_batch, generated_images))
y = [1] * BATCH_SIZE + [0] * BATCH_SIZE
d_loss = d.train_on_batch(X, y)
print("batch %d d_loss : %f" % (index, d_loss))
noise = np.random.uniform(-1, 1, (BATCH_SIZE, 100))
d.trainable = False
g_loss = d_on_g.train_on_batch(noise, [1] * BATCH_SIZE)
d.trainable = True
print("batch %d g_loss : %f" % (index, g_loss))
if index % 10 == 9:
g.save_weights('generator', True)
d.save_weights('discriminator', True)
def generate(BATCH_SIZE, nice=False):
g = generator_model()
g.compile(loss='binary_crossentropy', optimizer="SGD")
g.load_weights('generator')
if nice:
s = g.predict(noise, verbose=1)
d_pret = d.predict(generated_images, verbose=1)
index = np.arange(0, BATCH_SIZE*20)
index.resize((BATCH_SIZE*20, 1))
pre_with_index = list(np.append(d_pret, index, axis=1))
pre_with_index.sort(key=lambda x: x[0], reverse=True)
nice_images = np.zeros((BATCH_SIZE,) + generated_images.shape[1:3], dtype=np.float32)
nice_images = nice_images[:, :, :, None]
for i in range(BATCH_SIZE):
idx = int(pre_with_index[i][1])
nice_images[i, :, :, 0] = generated_images[idx, :, :, 0]
.predict(noise, verbose=1)
image = combine_images(generated_images)
image = image*127.5+127.5
Image.fromarray(image.astype(np.uint8)).save(
"generated_image.png")
def get_args():
parser = argparse.ArgumentParser()
parser.add_argument("--mode", type=str,default = 'train',)
# parser.add_argument("--mode", type=str,default = 'generate',)
parser.add_argument("--batch_size", type=int, default=8)
parse
if __name__ == "__main__":
args = get_args()
if args.mode == "train":
train(BATCH_SIZE=args.batch_size,path =args.path )
elif args.mode == "generate":
generate(BATCH_SIZE=args.batch_size, nice=args.nice)
创作不易 觉得有帮助请点赞关注收藏~~~