Prompt for Extraction? PAIE:Prompting Arguement Interaction for Event Argument Extraction
目录
Abstract
Introduction
Related Work
Methodology
Formulating Prompt for Extraction
Role-specific Selector Generation
Learning with Prompted Span Selector
Inference
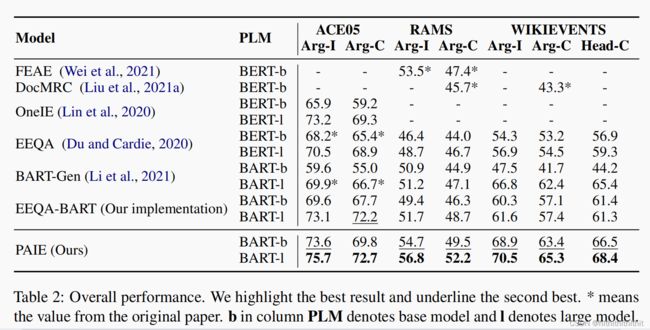
Experiments
Abstract
本文提出了一个有效且效率高的模型PAIE用于句子级和文档级事件 要素/论元 抽取(EAE),同时其在少样本的情况下的泛化性很好。本文使用了两个片段选择器去选择开始和结束位置的token,而且通过多角色prompts抓住了论元之间的交互关系并且通过bipartite matching loss进行具有最优跨度分配的联合优化。此外,PAIE可以提出具有相同角色的多个参数,而不是传统的启发式的阈值调优。
Introduction
事件抽取的定义:如下图所示,一个句子或者是一段文档表示一个事件类型,触发词用

事件抽取方法可大致分为两类:一是将其转化为一个语义角色标注任务,二是将其转换为问答和生成任务。语义角色标注首先识别候选的片段然后再进行角色分类。尽管联合模型可以共同优化,但是仍然不可避免地造成错误传播。基于问答地方法可以根据特定角色地问题有效地识别论元的边界,由于需要对一个句子进行多次提问造成复杂度成倍数提升。基于生成的方法有效的用于生成所有论元,但是序列预测在长程和多论元的情况下性能会有所降低。此外,优于目前SOTA的性能仍然不能令人满意。所以如何把以上方法的优点结合起来并加速性能。
本文针对真实的场景,即在句子和文档级别的任务上甚至在少样本设置下都有效。为此,强调了以下问题:
1、如何提取所有的论元的时候同时保证效率;
2、在事先不知道的情况下,有效地捕捉长文本的参数交互;
3、利用预训练模型中的知识来降低标注的需求。
在本文中,我们研究了在抽取设置下的提示调优,并提出了一种新的方法PAIE来提示实现论元抽取的参数交互。它扩展了基于问答的模型来处理多个参数抽取并利用了预训练模型的优势。基础的想法是设计合适的模板来提示所有的论元角色,并且获取针对角色的查询从文本中联合选择优化的片段。因此模板中的每个角色都作为交互的槽,而不是不可用的参数。在训练期间,通过匹配损失来使用论元填充这些槽。PAIE使用了一个高效和有效的学习方法来共同预测论元。此外,相似角色提示之间的事件间知识转移减轻了注释成本的沉重负担。
特别地,我们设计了两个片段选择器来识别输入文本中地开始和结束token。我们使用了三种类型地模板:人工模板、融合模板和软提示模板。我们在句子和文档层面都哦表现地不错,并且简化了详尽地提示式设计的要求。对于联合的span抽取,我们设计了二部匹配损失,可以在预测和真实值之间进行最小的成本匹配,以便每个参数得到最佳的角色提示。它还可以通过灵活的角色提示而不是启发式的阈值调优来处理具有相同角色的多个参数。我们总结了我们的贡献如下:
1、我们提出了PAIE高效且有效地解决了句子级别和文档级别地事件论元抽取,并且在少样本地设置中表现出了鲁棒性;
2、我们在抽取设置下制定和研究了提示调优,通过联合选取优化片段选择;
3、我们在三个benchmark上开展了大量的实验。在使用PAIE的时候表现出来良好的改善效果(在基础模型和大模型中F1的增长为3.5和2.3)。进一步的消融实验表明了我们提出的模型对少样本设置的效率和泛化性,以及提示调优的有效性。
Related Work
Event Argument Extraction:事件论元抽取是事件抽取中的一个子任务。从早期阶段开始,就有了大量的关于EAE任务的研究(Chen et al., 2015; Nguyen et al., 2016; Huang et al., 2018; Yang et al., 2018; Sha et al., 2018; Zheng et al., 2019).Huang and Peng (2021) 利用深度价值网络(DVN)来捕获情感E的跨事件依赖关系。Huang and Jia (2021)将文档转换为非加权图,使用GAT减缓角色重叠问题。一个普遍的做法是先识别候选论元然后再通过多分类为每个角色类型进行分类。为了处理隐秘的论元和多类事件,Xu et al. (2021) 建造了一个论元异构图。DEFNN(Yang et al., 2021)通过平行预测网络来预测论元。
最近的做法是将事件论元抽取转换为一个抽取式的问答问题。这种范式通过一个问题模板将EAE任务转换为充分探索的阅读理解任务,自然地从预先训练过的语言模型中引入语言知识。Wei et al. (2021)通过在模板中相互添加约束来考虑角色之间的隐式交互。Liu et al. (2021a)利用数据增强去提升性能。然而,它们只能逐个预测角色,这是效率较低的,通常会导致次优性能。
在预训练模的Transformer架构帮助下,将最近的工作转换为文本输出任务。Paolini等人(2021)提出TANL通过统一的文本到文本的方法来处理各种结构化的预测任务,包括EAE,并在一次传递中提取所有参数。Lu等人(2021)follow TANL的工作,并将EAE视为序列生成问题。Li等人(2021)通过为每种事件类型设计特定模板的目标生成模型。相比之下,我们通过设计一个二部匹配损失来提示参数交互来指导plm和优化多重参数检测。这不仅提高了对远程论元依赖关系的理解,而且通过基于提示的学习享有一个有效的过程。
Prompt-based Learning:基于提示的方法是预训练语言模型领域中的新范式。基于提示的方法将微调和预训练统一了起来。Schick and Schütze (2021)通过提示模板工程和答案工程将一系列的分类任务转换为完型填空任务。Li and Liang(2021)专注于生成任务,并通过冻结模型参数和只调整连续的任务特定向量序列来提出轻量级的前缀调整。和以上基于prompt调优针对分类和生成任务方法不同的是,我们的方法提出使用返回线性头方法的设置用于匹配抽取任务。它有点类似于P-tuning v2。
Methodology
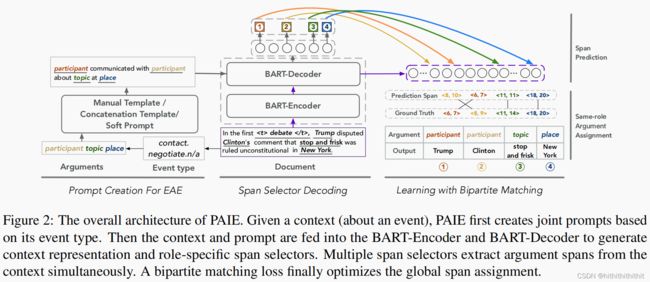
PAIE考虑多个论元和他们之间的关联用于提示预训练语言模型进行联合抽取。我们提出了以下的模型进行关系抽取。包括以下三部分:prompt create、span selector decoding、span prediction。在以下,我们首次将提示用于抽取并且依次介绍每一个部分。
Formulating Prompt for Extraction
现存的基于提示的方法主要关注分类和生成任务。传统的抽取任务被转化成一个生成任务。这带来一个效率问题,就是必须枚举所有的抽取候选实体。例如,Cui et al. (2021) 设计提示用于命名实体识别:[candidate span] is [entity type/not a] entity。模型需要使用候选的实体去填slot,然后查看语言模型的输出用于第二个slot的抽取。基于提示的方法可以被直接的应用于抽取吗?其基本思想和分类/生成相似,将插槽嵌入和标签词汇表/输入令牌进行比较。在此,我们给出了一般抽取提示的公式,并将其用于EAE进行案例研究。



Task Definition 我们将事件论元抽取转化为一个基于prompt片段抽取的问题。对于给出的例子![]() ,
, 表示上下文,
表示上下文, 表示触发词,
表示触发词, 表示事件类型,
表示事件类型,![]() 表示针对事件类型的角色类型集合,我们旨在抽取一系列的片段
表示针对事件类型的角色类型集合,我们旨在抽取一系列的片段 。
。![]() 是的切片,并且代表了论元
是的切片,并且代表了论元![]() 。
。
Prompt Creation for EAE 如上图所示,对于给出的事件类型协商(negotiate),有针对事件类型的论元角色{Participant,Topic,Place},组成如下的提示信息:
![]() communicated with
communicated with ![]() about
about ![]() at
at ![]() .
.
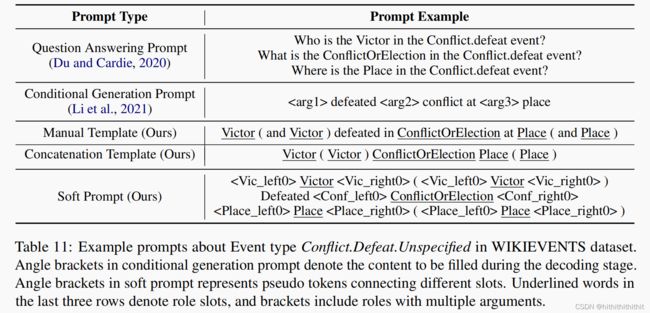
上面斜体字是论元角色提及,在这个例子中一共有四个槽,这样的设计允许我们的模型抓住不同角色之间的隐式联系。为了避免相同类型的多个论元需要阈值调优的情况出现,提示模板使用多个slot用于相同语义角色的提取,如上所示。角色的插槽数是根据训练数据集中每个角色的最大参数数启发式地确定的。我们设计了三种不同的提示创建者![]() ,从一组角色到提示的映射如下:
,从一组角色到提示的映射如下:
Manual Template:所有的角色都与自然语言人工连接。
Soft Template:使用可学习的针对特定角色的伪token连接不同的角色。
Concatention Template:连接某一个事件类型所有的角色名。
示例如下图所示:

Role-specific Selector Generation
对于给出的上下文和提示 ,这个模块生成针对角色的选择器
,这个模块生成针对角色的选择器![]() ,其中k表示提示的槽的顺序。本文中使用BART作为预训练模型
,其中k表示提示的槽的顺序。本文中使用BART作为预训练模型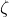 ,包含编码器
,包含编码器![]() 和解码器
和解码器![]() 。我们在输入文中使用
。我们在输入文中使用![]() .我们没有把prompt和上下文直接串联起来,而是将上下文放入编码器,prompt提示模板放入解码器,如上图figure2所示。提示和上下文将会在解码器模块中在交叉注意力层进行交互。
.我们没有把prompt和上下文直接串联起来,而是将上下文放入编码器,prompt提示模板放入解码器,如上图figure2所示。提示和上下文将会在解码器模块中在交叉注意力层进行交互。
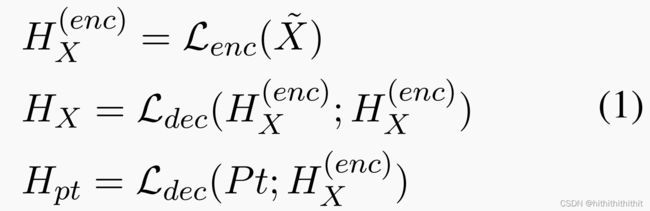
上图中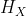 表示面向事件的上下文表示,
表示面向事件的上下文表示,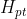 表示面向上下文的提示表示。对于第k个联合提示中的slot,我们从
表示面向上下文的提示表示。对于第k个联合提示中的slot,我们从![]() 中平均池化了他的对应的表示并且获取了角色特征
中平均池化了他的对应的表示并且获取了角色特征![]() ,其中h表示BART中隐藏层的维度。一个角色可能有多个slot和多个role feature以及多个span选择器。
,其中h表示BART中隐藏层的维度。一个角色可能有多个slot和多个role feature以及多个span选择器。
我们在先前的基于QA的方法上采取了简单有效的改动,通过从提示中的每个角色特征中推导出特定的跨度选择器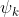 ,有以下:
,有以下:
![]()
![]()
其中,![]() 在所有角色之间共享可学习的参数,
在所有角色之间共享可学习的参数, 表示元素相乘。
表示元素相乘。![]() 表示提示中第k个槽。由于只有一个meta-head
表示提示中第k个槽。由于只有一个meta-head  和简单的操作,我们的方法可以生成任意数量的特定角色的片段选择器去从上下文中抽取相关的论元。从提示
和简单的操作,我们的方法可以生成任意数量的特定角色的片段选择器去从上下文中抽取相关的论元。从提示![]() 中回顾角色特征
中回顾角色特征![]() 的生成过程,很明显在这种范式下同时可以拥有不同角色之间的交互以及上下文和角色的聚合信息。
的生成过程,很明显在这种范式下同时可以拥有不同角色之间的交互以及上下文和角色的聚合信息。
Learning with Prompted Span Selector
对于给出的上下文表示和一系列的片段选择器![]() ,每一个
,每一个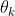 旨在从中抽取至少一个对应的论元片段
旨在从中抽取至少一个对应的论元片段![]() 。对于和相对应的一个论元
。对于和相对应的一个论元![]() ,其中i和j分别是上下文中开始和结束词下标,片段选择器期待输出
,其中i和j分别是上下文中开始和结束词下标,片段选择器期待输出![]() 作为预测。如果第k个槽没有对应的论元,那么会输出
作为预测。如果第k个槽没有对应的论元,那么会输出![]() 表示空论元。
表示空论元。
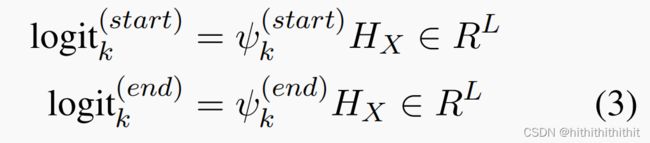
其中![]() 和
和![]() 表示上下文中每个slot的的开始和结束位置的概率分布,L表示上下文的文本长度。然后我们计算如下的开始和结束位置的概率:
表示上下文中每个slot的的开始和结束位置的概率分布,L表示上下文的文本长度。然后我们计算如下的开始和结束位置的概率:
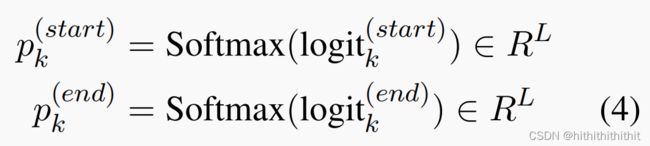
损失函数为:

其中D表示数据集中所有的文本,k表示提示中所有的slot。
Inference
在推理阶段,我们定义一系列的候选片段用于事件抽取![]() 。它包含所有的比阈值l段的所有片段并且片段(0,0)表示没有论元。我们的模型通过枚举并且对所有的候选片段进行打分来抽取每个片段选择器的论元。
。它包含所有的比阈值l段的所有片段并且片段(0,0)表示没有论元。我们的模型通过枚举并且对所有的候选片段进行打分来抽取每个片段选择器的论元。

通过下面的公式来预测第k个slot的片段:

由于提示符中的每个插槽最多可以预测一个跨度,因此该策略避免了详尽的阈值调优。
Experiments