注意力机制模块
1.SENet
SENet为通道注意力机制模块
实现方式:
1.首先对输入进来的特征层进行一个全局池化,将【b,c,h,w】 -> 【b,c,1,1】
2.对全局池化后的特征条进行两次全连接操作,第一次全连接操作生成一个较为短的特征条,之后用一个非线性的ReLU激活函数进行处理,第二次全连接层使特征长条恢复到输入的channel数,之后用Sigmoid激活函数让每个特征通道的权值固定在0-1之间
3.用获取的特征长条特征权值与原输入特征层进行乘积运算

代码参考
import torch
import torch.nn as nn
import math
class SEblock(nn.Module):
def __init__(self, channel, ratio=16):
super(SE_block, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channel, channel // ratio, bias=False),
nn.ReLU(inplace=True),
nn.Linear(channel // ratio, channel, bias=False),
nn.Sigmoid()
)
def forward(self, x):
b, c, h, w = x.size()
y = self.avg_pool(x).view(b, c)
y = self.fc(y).view(b, c, 1, 1)
return x * y
SENet模块应用

注:用两个Fully Connected层的优点
增加非线性,更好的拟合通道复杂的相关性
2.CBAM
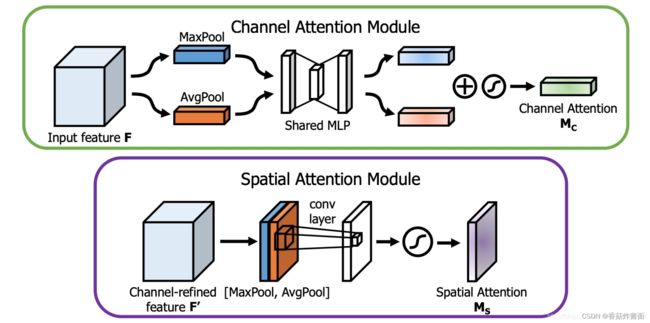
CBAM将空间注意力与通道注意力进行结合。
注:
空间注意力是在channel维度进行max与mean,通道注意力是在w,h维度上进行全局池化与平均
空间:【b,c,w,h】-> 【b,1,w,h】
通道:【b,c,w,h】->【b,c,1,1】
代码参考:
class ChannelAttention(nn.Module):
def __init__(self, in_planes, ratio=8):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
# 利用1x1卷积代替全连接
self.fc1 = nn.Conv2d(in_planes, in_planes // ratio, 1, bias=False)
self.relu1 = nn.ReLU()
self.fc2 = nn.Conv2d(in_planes // ratio, in_planes, 1, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = self.fc2(self.relu1(self.fc1(self.avg_pool(x))))
max_out = self.fc2(self.relu1(self.fc1(self.max_pool(x))))
out = avg_out + max_out
return self.sigmoid(out)
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
assert kernel_size in (3, 7), 'kernel size must be 3 or 7'
padding = 3 if kernel_size == 7 else 1
self.conv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
x = torch.cat([avg_out, max_out], dim=1)
x = self.conv1(x)
return self.sigmoid(x)
class cbam_block(nn.Module):
def __init__(self, channel, ratio=8, kernel_size=7):
super(cbam_block, self).__init__()
self.channelattention = ChannelAttention(channel, ratio=ratio)
self.spatialattention = SpatialAttention(kernel_size=kernel_size)
def forward(self, x):
x = x * self.channelattention(x)
x = x * self.spatialattention(x)
return x
代码参考来自于https://blog.csdn.net/weixin_44791964/article/details/121371986