图像处理之目标检测入门总结
点击上方“机器学习与生成对抗网络,"星标置顶”
重磅干货,第一时间送达
本文首先介绍目标检测的任务,然后介绍主流的目标检测算法或框架,重点为Faster R-CNN,SSD,YOLO三个检测框架。本文内容主要整理自网络博客,用于普及性了解。
ps:由于之后可能会有一系列对象检测的论文阅读笔记,在论文阅读之前,先大致了解一下目前的研究现状,目标检测的各种主流方法的大致原理,以助于后面能更顺畅看懂论文,后续再通过论文阅读进行细节学习。由于尚未阅读相关论文原文,若有问题,欢迎指出!先献上一个RCNN系列的图(来自知乎:iker peng)。

Objection Detection Tasks
目前计算机视觉(CV,computer vision)与自然语言处理(Natural Language Process, NLP)及语音识别(Speech Recognition)并列为人工智能(AI,artificial intelligence)·机器学习(ML,machine learning)·深度学习(DL,deep learning)方向的三大热点方向 。
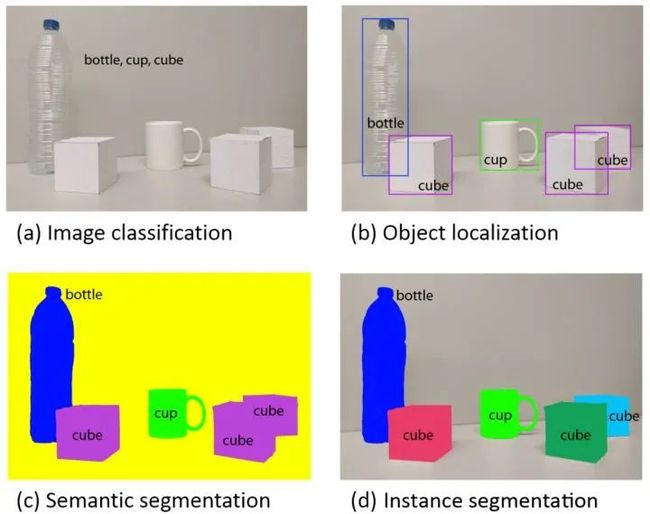
而计算机视觉又有四个基本任务(关于这个任务,说法不一,比如有些地方说到对象检测detection、对象追踪tracking、对象分割segmentation,不用拘泥),即图像分类,对象定位及检测,语义分割,实例分割。图示如下:
a)图像分类:一张图像中是否包含某种物体
b)物体检测识别:若细分该任务可得到两个子任务,即目标检测,与目标识别,首先检测是视觉感知得第一步,它尽可能搜索出图像中某一块存在目标(形状、位置)。而目标识别类似于图像分类,用于判决当前找到得图像块得目标具体是什么类别。
c)语义分割:按对象得内容进行图像得分割,分割的依据是内容,即对象类别。
d)实例分割:按对象个体进行分割,分割的依据是单个目标。
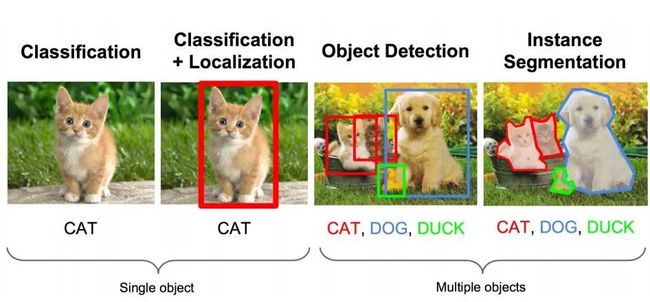
不管什么任务,目标检测应该是计算机视觉领域首先需要掌握的
Methods
传统的计算机视觉问题的解决思路:图像——预处理——人工特征(hand-crafted features)提取——分类。大部分研究集中在人工特征的构造和分类算法上,涌现了很多杰出的工作。但存在的问题是人工设计的特征可能适用性并不强,或者说泛化能力较弱,一类特征可能针对某类问题比较好,其他问题就效果甚微。
目前主流的深度学习解决思路:通过深度学习算法,进行端到端的解决,即输入图像到输出任务结果一步完成。但其实内部它还是分stages的,通常是图像——特征提取网络——分类、回归。
这里特征提取网络即各种深度神经网络结构,针对这一算法的研究很多,比如说各层的设计细节(激活函数,损失函数,网络结构等)、可视化等,为了能提取更加强壮有效的特征,研究者考虑各种问题,如尺度不变性问题(通常用于解决小目标的检测,如特征金字塔网络,Feature Pyramid Network,FPN),整个网络其实是分作两类的,前N个层为第一部分,用于特征的提取,输入的图片,输出的是特征图,这与传统的人工特征提取本质上没有太大区别,只是提取特征的算法变成了神经网络算法。而网络的后K层是作为第二部分,完成具体的分类或者回归任务,任务的输入是前一个部分得到的特征图,输出是任务的结果。所以显然后一部分其实是可以被替代的,也确实有很多框架的第二部分采用其他机器学习的算法替代,如SVM。
所以需要对自己有个认识!是做算法的研究(通常深度学习就是研究神经网络算法,如何让它特征提取更强大、分类更准确、速度更快,从网络结构、loss function、activation function等入手,需要强大的数学理论)?还是解决某个具体的问题(用已有的优秀的神经网络算法,侧重于研究解决问题的框架,当然很多时候需要对已有的算法做些微调)?
我粗浅的认为前者更纯理论,后者往往以工程为依托。
针对你的任务,如何设计网络?当面对你的实际任务时,如果你的目标是解决该任务而不是发明新算法,那么不要试图自己设计全新的网络结构,也不要试图从零复现现有的网络结构。找已经公开的实现和预训练模型进行微调。去掉最后一个全连接层和对应softmax,加上对应你任务的全连接层和softmax,再固定住前面的层,只训练你加的部分。如果你的训练数据比较多,那么可以多微调几层,甚至微调所有层。
Algorithms
目标检测的基本思路:同时解决定位(localization) + 检测(detection)。
多任务学习,带有两个输出分支。一个分支用于做图像分类,即全连接+softmax判断目标类别,和单纯图像分类区别在于这里还另外需要一个“背景”类。另一个分支用于判断目标位置,即完成回归任务输出四个数字标记包围盒位置(例如中心点横纵坐标和包围盒长宽),该分支输出结果只有在分类分支判断不为“背景”时才使用。
Region Proposal
为什么要有候选区域?既然目标是在图像中的某一个区域,那么最直接的方法就是滑窗法(sliding window approach),就是遍历图像的所有的区域,用不同大小的窗口在整个图像上滑动,那么就会产生所有的矩形区域,然后再后续排查,思路简单,但开销巨大。
候选区域生成算法通常基于图像的颜色、纹理、面积、位置等合并相似的像素,最终可以得到一系列的候选矩阵区域。这些算法,如selective search或EdgeBoxes,通常只需要几秒的CPU时间,而且,一个典型的候选区域数目是2k,相比于用滑动窗把图像所有区域都滑动一遍,基于候选区域的方法十分高效。另一方面,这些候选区域生成算法的查准率(precision)一般,但查全率(recall)通常比较高,这使得我们不容易遗漏图像中的目标。
Selective Search
“Segmentation as selective search for object recognition ”,ICCV,2011.
“Selective search for object recognition.” International journal of computer vision ,2013
论文应该是有两部分内容,一部分是Selective Search的方法寻找候选区域,第二部分为该区域上的特征提取及后续的分类。由于目前特征提取和分类都采用了深度学习方法,所以只是借鉴其候选区寻找算法Selective Search。
将图像划分成很多的小区域(regions)
如何将图像划分成很多的小区域? 划分的方式应该有很多种,比如:
1)等间距划分grid cell,这样划分出来的区域每个区域的大小相同,但是每个区域里面包含的像素分布不均匀,随机性大;同时,不能满足目标多尺度的要求(当然,可以用不同的尺度划分grid cell,这称为Exhaustive Search, 计算复杂度太大)!
2)使用边缘保持超像素划分;
3)使用本文提出的Selective Search(SS)的方法来找到最可能的候选区域;
其实这一步可以看做是对图像的过分割,都是过分割,本文SS方法的过人之处在于预先划分的区域什么大小的都有(满足目标多尺度的要求),而且对过分割的区域还有一个合并的过程(区域的层次聚类),最后剩下的都是那些最可能的候选区域,然后在这些已经过滤了一遍的区域上进行后续的识别等处理,这样的话,将会大大减小候选区域的数目,提供了算法的速度.
下图说明目标的多尺度:

总体思路:假设现在图像上有n个预分割的区域,表示为R={R1, R2, …, Rn}, 计算每个region与它相邻region(注意是相邻的区域)的相似度,这样会得到一个n*n的相似度矩阵(同一个区域之间和一个区域与不相邻区域之间的相似度可设为NaN),从矩阵中找出最大相似度值对应的两个区域,将这两个区域合二为一,这时候图像上还剩下n-1个区域; 重复上面的过程(只需要计算新的区域与它相邻区域的新相似度,其他的不用重复计算),重复一次,区域的总数目就少1,知道最后所有的区域都合并称为了同一个区域(即此过程进行了n-1次,区域总数目最后变成了1).算法的流程图如下图所示:

step0:生成区域集R,具体参见论文《Efficient Graph-Based Image Segmentation》,基于图的图像分割,也就是说起点还是图像分割
step1:计算区域集R里每个相邻区域的相似度S={s1,s2,…}
step2:找出相似度最高的两个区域,将其合并为新集,添加进R
step3:从S中移除所有与step2中有关的子集
step4:计算新集与所有子集的相似度
step5:跳至step2,直至S为空
相似度计算:论文从四个方面考虑相似度度量——颜色、纹理、尺寸和空间交叠
EdgeBoxes
Edge Boxes: Locating Object Proposals from Edges ,ECCV2014
文章没有涉及到“机器学习”,采用的是纯图像的方法。
研究方法:利用边缘信息(Edge),确定box内的轮廓个数和与box边缘重叠的edge个数(知道一个box内完全包含的轮廓个数,那么目标有很大可能性,就在这个box中),基于此对box进行评分,进一步根据得分的高低顺序确定proposal信息(由大小,长宽比,位置构成)。而后续工作就是在proposal内部运行相关检测算法。
matlab 代码:https://github.com/pdollar/edges
建议参考博客:《Edge Boxes: Locating Object Proposals from Edges》读后感 :https://blog.csdn.net/wsj998689aa/article/details/39476551
R-CNN
“Rich feature hierarchies for accurate object detection and semantic segmentation.” CVPR 2014
卷积神经网络进入目标识别的里程碑,R-CNN,直接看图了解其结构! 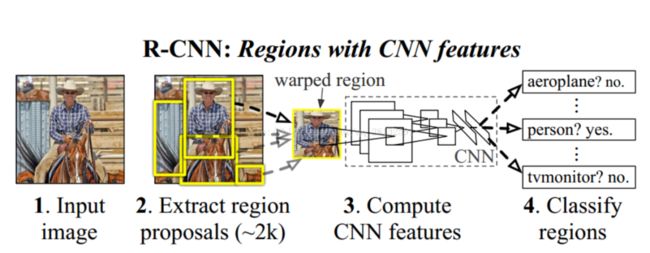
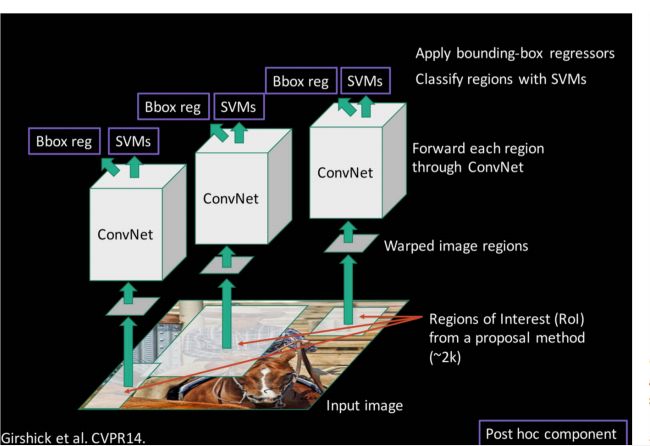
流程:原图——Selective Search得到2K Proposal Regions —— Warpped image region(?) —— ConvNet —— 分类(svm) + 回归(bounding box regression) 。
这里的Warpped Image Region应该是一种类似resize的操作,将不同大小的proposal region统一到相同的尺寸,用以输入相同的ConvNet,上面的Convnet是相同的,但SVM分类器是针对每一个类别单独训练好的,是不同的分类器。
R-CNN,是基于这样一种非常简单的想法,对于输入图像,通过selective search方法,先确定出例如2000个最有可能包含物体的窗口,对于这2000个窗口,我们希望它能够对待检测物体达到非常高的召回率。然后对这2000个中的每一个去用CNN进行特征提取和分类。对这2000个区域都要去跑一次CNN,那么它的速度是非常慢的,即使每次只需要0.5秒,2000个窗口的话也是需要1000秒,为了加速2014年的时候何凯明提出了SPP-net,其做法是对整个图跑一次CNN,而不需要每一个窗口单独做,但是这样有一个小困难,就是这2000个候选窗口每一个的大小都不一样,为了解决这个问题,SPP-net设计了spatial pyramid pooling,使得不同大的小窗口具有相同维度的特征。这个方法使得检测时不需要对每一个候选窗口去计算卷积,但是还是不够快,检测一张图像还是需要几秒的时间。
存在的不足:
1)多个候选区域对应的图像需要预先提取,占用较大的磁盘空间;
2)针对传统CNN需要固定尺寸的输入图像,crop/warp(归一化)产生物体截断或拉伸,会导致输入CNN的信息丢失;
3)每一个ProposalRegion都需要进入CNN网络计算,上千个Region存在大量的范围重叠,重复的特征提取带来巨大的计算浪费。
SPP-Net
Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition,ECCV 2014,Kaiming He
各个Proposal Region大小不一,全图只卷积一次的话,就不需要经过Wrapp,在特征图上找这些Region的时候还是存在大小不一的问题,由于维度不同,后面的全连接层FC的输入无法统一,故采用SPP,空间金字塔池化,这样不同尺寸的Region通过不同金字塔池化层,从而得到统一维度的输出,加速算法同时,兼顾了尺度问题。
在R-CNN中,要求输入固定大小的图片,因此需要对图片进行crop、wrap变换,改变尺寸引起的形变影响检测效果。此外,对每一个图像中每一个proposal进行一遍CNN前向特征提取,如果是2000个propsal,需要2000次前向CNN特征提取,这无疑将浪费很多时间。
该论文对R-CNN中存在的缺点进行了改进,基本思想是,输入整张图像,提取出整张图像的特征图,然后利用空间关系从整张图像的特征图中,在spatial pyramid pooling layer提取各个region proposal的特征。
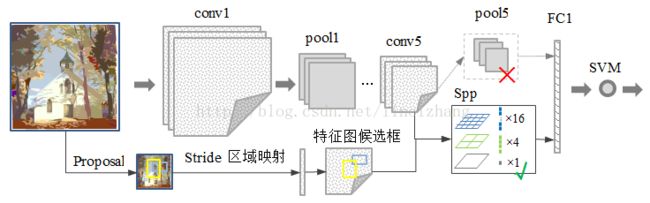
1)取消了crop/warp图像归一化过程,解决图像变形导致的信息丢失以及存储问题;
2)采用空间金字塔池化(SpatialPyramid Pooling )替换了 全连接层之前的最后一个池化层(上图top),翠平说这是一个新词,我们先认识一下它。
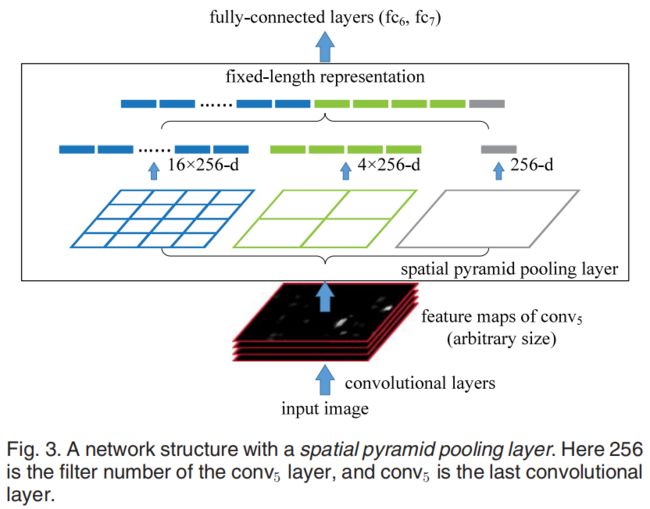
SPP主要有两个特点:
结合空间金字塔方法实现CNNs的对尺度输入。
一般CNN后接全连接层或者分类器,他们都需要固定的输入尺寸,因此不得不对输入数据进行crop或者warp,这些预处理会造成数据的丢失或几何的失真。SPP Net的第一个贡献就是将金字塔思想加入到CNN,实现了数据的多尺度输入。如下图所示,在卷积层和全连接层之间加入了SPP layer。此时网络的输入可以是任意尺度的,在SPP layer中每一个pooling的filter会根据输入调整大小,而SPP的输出尺度始终是固定的。
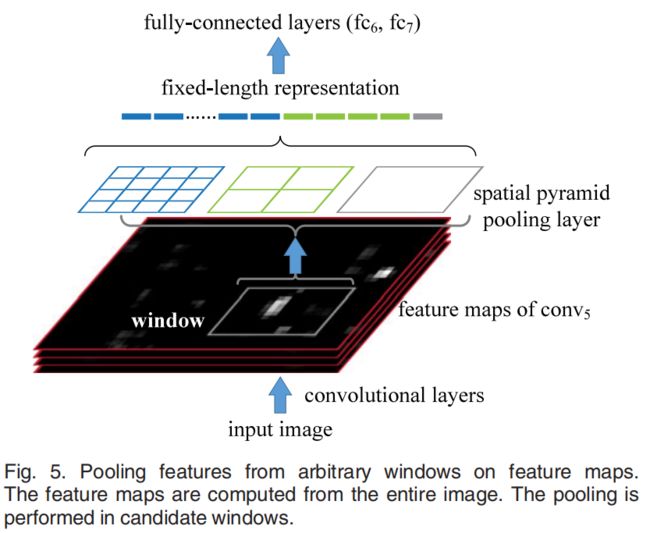
只对原图提取一次卷积特征
在R-CNN中,每个候选框先resize到统一大小,然后分别作为CNN的输入,这样是很低效的。所以SPP Net根据这个缺点做了优化:只对原图进行一次卷积得到整张图的feature map,然后找到每个候选框在feature map上的映射patch,将此patch作为每个候选框的卷积特征输入到SPP layer和之后的层。节省了大量的计算时间,比R-CNN有一百倍左右的提速。
存在的不足:
1)和RCNN一样,训练过程仍然是隔离的,提取候选框 | 计算CNN特征| SVM分类 | Bounding Box回归独立训练,大量的中间结果需要转存,无法整体训练参数;
2)SPP-Net在无法同时Tuning在SPP-Layer两边的卷积层和全连接层,很大程度上限制了深度CNN的效果;
3)在整个过程中,Proposal Region仍然很耗时。
Fast R-CNN
“Fast r-cnn.” ICCV 2015. Girshick, Ross.
R-CNN的进阶版Fast R-CNN就是在RCNN的基础上采纳了SPP Net方法,对RCNN作了改进,使得性能进一步提高。
Fast R-CNN借鉴了SPP-net的做法,在全图上进行卷积,然后采用ROI-pooling得到定长的特征向量,例如不管窗口大小是多少,转换成7x7这么大。Fast R-CNN还引入了一个重要的策略,在对窗口进行分类的同时,还会对物体的边框进行回归,使得检测框更加准确。前面我们说候选窗口会有非常高的召回率,但是可能框的位置不是很准,例如一个人体框可能是缺胳膊缺腿,那么通过回归就能够对检测框进行校准,在初始的位置上求精。Fast R-CNN把分类和回归放在一起来做,采用了多任务协同学习的方式。
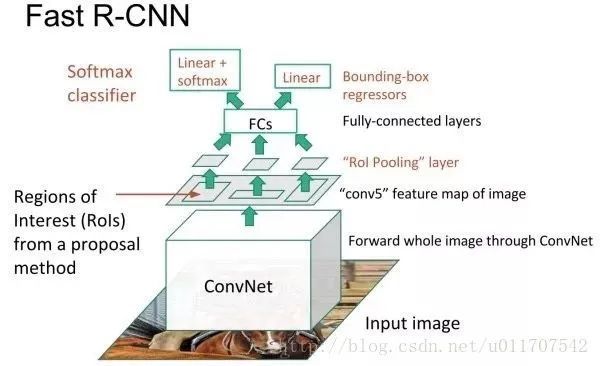
ROI Pooling(region of interest pooling )
兴趣区域汇合旨在由任意大小的候选区域对应的局部卷积特征提取得到固定大小的特征,这是因为下一步的两分支网络由于有全连接层,需要其输入大小固定。其做法是,先将候选区域投影到卷积特征上,再把对应的卷积特征区域空间上划分成固定数目的网格(数目根据下一步网络希望的输入大小确定,例如VGGNet需要7×7的网格),最后在每个小的网格区域内进行最大汇合,以得到固定大小的汇合结果。和经典最大汇合一致,每个通道的兴趣区域汇合是独立的。 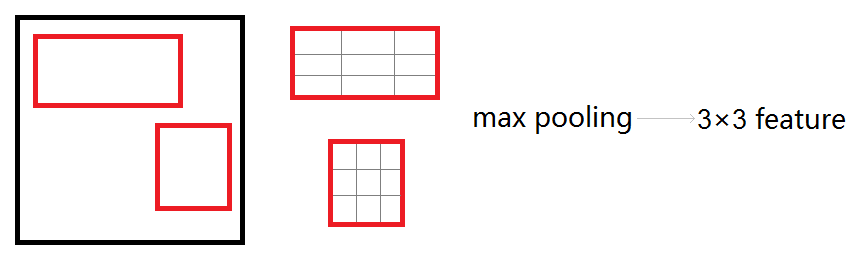
Faster R-CNN
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks,NIPS 2015
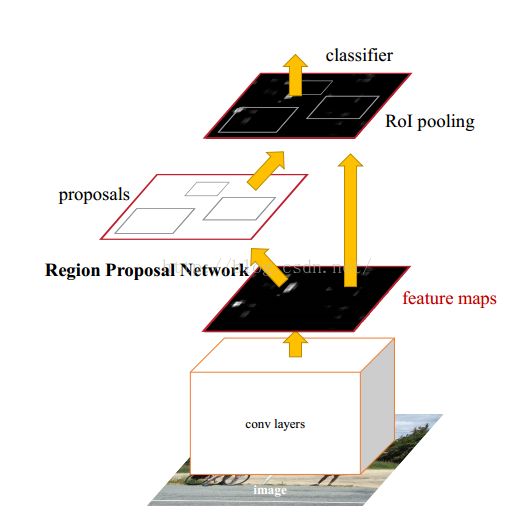
之前的Fast R-CNN已经基本实现端到端的检测,而主要的速度瓶颈是在Selective Search算法实现的Region Proposal,故到了Faster R-CNN,主要是解决Region Proposal问题,以实现Real-Time检测。Faster R-CNN的主要思路是,既然检测工作是在卷积的结果Feature Map上做的,那么候选区域的选取是否也能在Feature Map上做?于是RPN网络(Region Proposal Network)应运而生。
候选框提取不一定要在原图上做,特征图上同样可以,低分辨率特征图意味着更少的计算量,基于这个假设,MSRA的任少卿等人提出RPN(RegionProposal Network),整体架构如下图所示
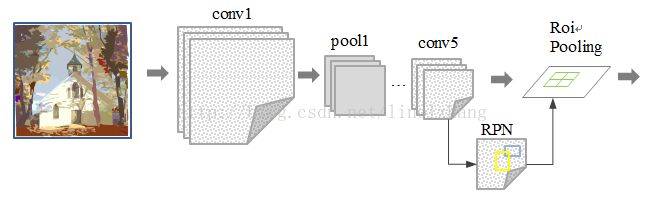
通过添加额外的RPN分支网络,将候选框提取合并到深度网络中,这正是Faster-RCNN里程碑式的贡献 !
RPN引入了所谓anchor box的设计,具体来说,RPN在最后一个卷积层输出的特征图上,先用3x3的卷积得到每个位置的特征向量,然后基于这个特征向量去回归9个不同大小和长宽比的窗口,如果特征图的大小是40x60,那么总共就会有大约2万多个窗口,把这些窗口按照信度进行排序,然后取前300个作为候选窗口,送去做最终的分类 。
Faster实现了端到端的检测,并且几乎达到了效果上的最优,但小物体的识别还存在问题,故SSD算法诞生;速度方向的改进仍有余地,于是YOLO诞生了。
SSD
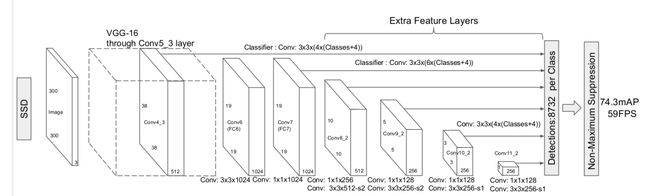
SSD算法是一种直接预测目标类别和bounding box的多目标检测算法。与faster rcnn相比,该算法没有生成 proposal 的过程,这就极大提高了检测速度。针对不同大小的目标检测,传统的做法是先将图像转换成不同大小(图像金字塔),然后分别检测,最后将结果综合起来(NMS)。而SSD算法则利用不同卷积层的 feature map 进行综合也能达到同样的效果。算法的主网络结构是VGG16,将最后两个全连接层改成卷积层,并随后增加了4个卷积层来构造网络结构。对其中5种不同的卷积层的输出(feature map)分别用两个不同的 3×3 的卷积核进行卷积,一个输出分类用的confidence,每个default box 生成21个类别confidence;一个输出回归用的 localization,每个 default box 生成4个坐标值(x, y, w, h)。此外,这5个feature map还经过 PriorBox 层生成 prior box(生成的是坐标)。上述5个feature map中每一层的default box的数量是给定的(8732个)。最后将前面三个计算结果分别合并然后传给loss层。
YOLO
2015年出现了一个名为YOLO的方法,其最终发表在CVPR 2016上。这是一个蛮奇怪的方法,对于给定的输入图像,YOLO不管三七二十一最终都划分出7x7的网格,也就是得到49个窗口,然后在每个窗口中去预测两个矩形框。这个预测是通过全连接层来完成的,YOLO会预测每个矩形框的4个参数和其包含物体的信度,以及其属于每个物体类别的概率。YOLO的速度很快,在GPU上可以达到45fps。
YOLO的处理步骤为:把输入图片缩放到448×448大小;运行卷积网络;对模型置信度卡阈值,得到目标位置与类别。对VOC数据集来说,YOLO就是把图片统一缩放到448×448,然后每张图平均划分为7×7=49个小格子,每个格子预测2个矩形框及其置信度,以及20种类别的概率。舍弃了Region proposal阶段,加快了速度,但是定位精度比较低,与此同时带来的问题是,分类的精度也比较低。在各类数据集上的平均表现大概为54.5%mAP。
总结一下RCNN系列算法的步骤: 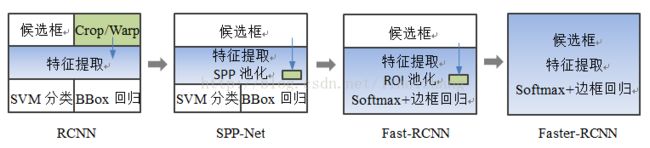
RCNN
在图像中确定约1000-2000个候选框 (使用选择性搜索)
每个候选框内图像块缩放至相同大小,并输入到CNN内进行特征提取
对候选框中提取出的特征,使用分类器判别是否属于一个特定类
对于属于某一特征的候选框,用回归器进一步调整其位置
Fast RCNN
在图像中确定约1000-2000个候选框 (使用选择性搜索)
对整张图片输进CNN,得到feature map
找到每个候选框在feature map上的映射patch,将此patch作为每个候选框的卷积特征输入到SPP layer和之后的层
对候选框中提取出的特征,使用分类器判别是否属于一个特定类
对于属于某一特征的候选框,用回归器进一步调整其位置
Faster RCNN
对整张图片输进CNN,得到feature map
卷积特征输入到RPN,得到候选框的特征信息
对候选框中提取出的特征,使用分类器判别是否属于一个特定类
对于属于某一特征的候选框,用回归器进一步调整其位置
三者比较
方法 创新 缺点 改进 R-CNN (Region-based Convolutional Neural Networks) 1、SS提取RP;2、CNN提取特征;3、SVM分类;4、BB盒回归。 1、 训练步骤繁琐(微调网络+训练SVM+训练bbox);2、 训练、测试均速度慢 ;3、 训练占空间 1、 从DPM HSC的34.3%直接提升到了66%(mAP);2、 引入RP+CNN Fast R-CNN (Fast Region-based Convolutional Neural Networks) 1、SS提取RP;2、CNN提取特征;3、softmax分类;4、多任务损失函数边框回归。 1、 依旧用SS提取RP(耗时2-3s,特征提取耗时0.32s);2、 无法满足实时应用,没有真正实现端到端训练测试;3、 利用了GPU,但是区域建议方法是在CPU上实现的。 1、 由66.9%提升到70%;2、 每张图像耗时约为3s。 Faster R-CNN (Fast Region-based Convolutional Neural Networks) 1、RPN提取RP;2、CNN提取特征;3、softmax分类;4、多任务损失函数边框回归。 1、 还是无法达到实时检测目标;2、 获取region proposal,再对每个proposal分类计算量还是比较大。 1、 提高了检测精度和速度;2、 真正实现端到端的目标检测框架;3、 生成建议框仅需约10ms。
转自:https://blog.csdn.net/f290131665/article/details/81012556
 End
End
声明:部分内容来源于网络,仅供读者学术交流之目的。文章版权归原作者所有。如有不妥,请联系删除。
猜您喜欢:
超100篇!CVPR 2020最全GAN论文梳理汇总!
拆解组新的GAN:解耦表征MixNMatch
StarGAN第2版:多域多样性图像生成
附下载 | 《可解释的机器学习》中文版
附下载 |《TensorFlow 2.0 深度学习算法实战》
附下载 |《计算机视觉中的数学方法》分享
《基于深度学习的表面缺陷检测方法综述》
《零样本图像分类综述: 十年进展》
《基于深度神经网络的少样本学习综述》
