基于Spark MLlib的余弦相似度计算实战与欧几里得距离概述【相似度度量】
在上篇文章协同过滤推荐算法概述中,我们看到了对于不同形式的协同过滤举证,最重要的部分是相似度的计算,如果不同的用户或者物品之间的相似度缺乏有效而可靠的算法定义,那么协同过滤算法就失去了成立的基础条件。
转载请标明原文链接:原文链接
欧几里得距离相似度计算
欧几里得距离是常用的计算距离的公式,它表示三维空间的两个点的真实距离。欧几里得相似度计算是一种基于用户之间直线距离的计算方式,在计算时,不同的物品或者用户可以将其定义为不同的坐标点,而特定的目标定位为坐标原点,欧几里得计算两个点之间的距离公式如下:

知道了两个坐标之间的直线距离,欧几里得相似度也就很好计算了,与d成反比,即其相似度公式如下:
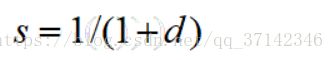
从公式可以看出两个物品或者用户之间的距离越大,则其相似度越小,距离越小则相似度越大。
|物品 |物品1 |物品2 |物品3 |物品4
|- |
|用户1 |1 |1 |3 |1
|用户2 |1 |2 |3 |2
|用户3 |2 |2 |1 |1
下面分别计算用户2和用户3之间的相似度,通过欧几里得距离公式可得:
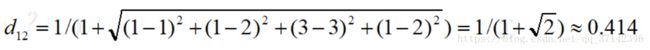
![]()
从计算结果可以看出,d12的分值大于d13的分值,因此可以得出结论,用户2比用户3更与用户1具有相似性。
余弦角度相似度计算
与欧几里得距离相似,余弦相似度也特定目标,即物品或者用户作为坐标上的点,但不是坐标原点。基于此与特定的被计算的目标进行夹角计算。

由上图可以看出,如果两个目标较为相似,则其射线形成的夹角较小。如果两个用户不相近,则两条射线形成的夹角较大,因此在使用余弦度量的相似度计算中,可以用夹角的大小来反映目标之间的相似性。计算公式如下:

按照上面公式同样可以计算出上面案例中用户之间的相似度。
欧几里得相似度注重目标之间的差异,与目标在空间中的距离直接相关,而余弦相似度是不同目标在空间中的夹角,更加表现在前进趋势上的差异。一般来说,欧几里得相似度用来表现不同目标的绝对差异性,分析目标用户之间的相似度与差异情况。而余弦相似度更多是对目标从方向趋势上区分(分离状态),对特定坐标数字不敏感。
余弦相似度计算实战
下面以余弦相似度为例进行实战演习,模拟不同用户对不同电影之间的评分来计算用户之间的相似性。
首先是数据的输入,这里使用以数组的形式初始化进行模拟。代码如下:
//实例化环境
val conf=new SparkConf()
.setAppName("ConsineSimilar")
.setMaster("local")
val sc=new SparkContext(conf)
//初始化用户
val users=sc.parallelize(Array("aaa","bbb","ccc","ddd","eee"))
//设置电影名
val films=sc.parallelize(Array("smzdm","yixb","znh","nhsc","fcwr"))
下面是核心代码,使用余弦相似度公式来计算不同用户之间的相似度。
/**
* 计算余弦相似性
* @param user1
* @param user2
* @return
*/
def getCollaborateSource(user1:String,user2:String): Double ={
//获得第一个用户的评分
val user1FilmSource = source.get(user1).get.values.toVector
//获得第二个用户的评分
val user2FileSource = source.get(user2).get.values.toVector
//对欧几里得公式分子部分进行计算
val member = user1FilmSource.zip(user2FileSource).map(num=>num._1*num._2).reduce(_+_).toDouble
//求出分母第一个变量的值
val temp1 = math.sqrt(user1FilmSource.map(num => {
math.pow(num, 2)
}).reduce(_+_)).toDouble
//求出分母第二个变量的值
val temp2 = math.sqrt(user2FileSource.map(num => {
math.pow(num,2)
}).reduce(_+_)).toDouble
//求出分母
val denominator = temp1*temp2
//返回结果
member/denominator
}
主函数:
def main(args: Array[String]): Unit = {
//初始化分数
getSource()
//设定目标对象
val name="bbb"
//迭代进行计算
users.foreach(user=>{
println(name + " 相对于 "+user +"的相似性分数为: "+getCollaborateSource(name,user))
})
val frist=users.sortBy((user=>getCollaborateSource(name,user)),false,1).first()
println("-----------------------------------------------------------")
println("相似度最高的用户为:"+frist)
}
最后打印结果如下:
bbb 相对于 aaa的相似性分数为: 0.7089175569585667
bbb 相对于 bbb的相似性分数为: 1.0000000000000002
bbb 相对于 ccc的相似性分数为: 0.8780541105074453
bbb 相对于 ddd的相似性分数为: 0.6865554812287477
bbb 相对于 eee的相似性分数为: 0.6821910402406466
-----------------------------------------------------------
相似度最高的用户为:bbb
完整的代码下载地址:完整代码下载地址
如果你想和我们一起学习交流,共同进步,欢迎加群:
