【深度学习】YOLOv5 工程落地部署过程,MNN转化,使用细节
文章目录
- 概述
- 目标检测模型概述
- 使用COCO2017体验YOLOv5
-
- 下载项目和权重
- 下载处理COCO2017数据
- 训练YOLOv5
- 导出模型到其他框架
- 模型推理
-
- detect.py
- 模型的输入输出尺寸
- letterbox
- non_max_suppression
- MNN
-
- 安装
- 转化
- 代码测试
- 模型的超参数
- 模型的训练数据文件组织
- 意外中断后恢复训练,训练过程中想修改参数
概述
兜兜转转又回到YOLOv5,YOLOv5的项目代码太易用了,开箱即用,工具多,效果好,谁能不爱呢。我这里对我使用YOLOv5 做简单的记录,以后自己看到能很快用起来就是本篇文章的目的,这篇文章我一直要干到MNN部署方式去。
目标检测模型概述
深度学习模型由于其拥有足够的表达能力,能够很好表达从输入数据到输出数据的映射关系,被广泛应用于各类场景中。图1中展现了深度学习模型在文字、图像、语音中的应用场景,其中图像是我个人最熟悉的,也是日常业务中最常遇到的场景。

图像领域有四个主要任务:图像分类、目标检测、图像分割、实例分割。
在目标分割领域中,基本可以分为anchor based方法和anchor free方法,yolov5这个算法模型是anchor based方法,同时也是集大成者,包含目前目标检测领域中所有的比较有效的方法(FPN、PAN、SPP、CSP等),目前仍就是目标检测领域中最为优秀的算法之一。目前学术界的研究在目标检测领域主要分为两个方向,一是使用anchor free方法的模型(学术界普遍认为此种方法更加符合目标检测的原始动机,不带有那么高的监督性),二是使用 NLP领域的一些新模型(比如Transformer、多模态的一些研究)。
就目前学术研究情况(靠学术前沿论坛获知)和各大公司所采用模型情况来看,yolov5依旧是一个值得长期选择和持有的模型。
使用COCO2017体验YOLOv5
在最新版本的yolov5中,只需要python train.py即可开始训练coco128,非常智能。
其实可以用COCO128体验,过程与下面类似,我这里用COCO2017因为我已经下载过了。
下载项目和权重
项目代码:https://github.com/ultralytics/yolov5
字模:https://github.com/ultralytics/yolov5/releases/download/v1.0/Arial.ttf
权重:https://github.com/ultralytics/yolov5/releases
或者直接全部用网盘下载:链接:https://pan.baidu.com/s/1q8WOj-aJgn3p2UhbXVFPtQ?pwd=v3e9
下载处理COCO2017数据
https://github.com/ultralytics/yolov5中yolov5/data/scripts中get_coco.sh脚本就是下载COCO2017数据集的,四个压缩包,coco2017labels.zip是处理过的符合COCO的数据,train2017.zip、val2017.zip、test2017.zip是图片数据。原代码中含有解压的一些操作,下面的代码删除了解压的操作:
#!/bin/bash
# YOLOv5 by Ultralytics, GPL-3.0 license
# Download COCO 2017 dataset http://cocodataset.org
# Example usage: bash data/scripts/get_coco.sh
# parent
# ├── yolov5
# └── datasets # 官网的方式
# └── coco ← downloads here
# Download/unzip labels
d='../datasets' # unzip directory
url=https://github.com/ultralytics/yolov5/releases/download/v1.0/
f='coco2017labels.zip' # or 'coco2017labels-segments.zip', 68 MB
echo 'Downloading' $url$f ' ...'
curl -L $url$f -o $f
# Download/unzip images
url=http://images.cocodataset.org/zips/
f1='train2017.zip' # 19G, 118k images
f2='val2017.zip' # 1G, 5k images
f3='test2017.zip' # 7G, 41k images (optional)
for f in $f1 $f2; do
echo 'Downloading' $url$f '...'
curl -L $url$f -o $f
done
wait # finish background tasks
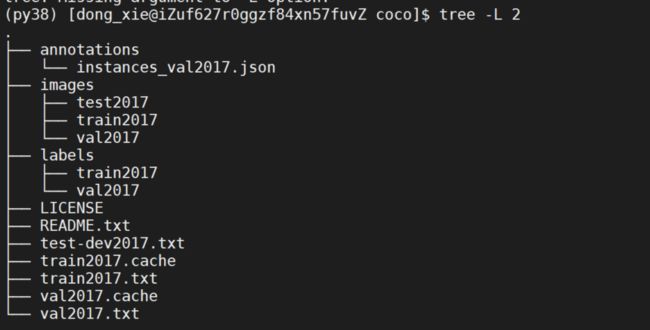
最终形成的数据文件夹的层级目录如下图,其中 instances_val2017.json 应该是COCO2017的标注原文件是json版的,images里面的三个文件就是我自行解压进去的,labels里面的2个文件是COCO2017的标注文件yolo版本的。 train2017.txt 里面写了用于训练的图片的路径(相对路径), val2017.txt里面写了用于验证的图片的路径(相对路径), test-dev2017.txt里面写了用于测试的图片的路径(相对路径)。
这里是一种方式,这里可以关注yolov5代码里对数据的解析:
(1)images和labels的路径名是被yolov5识别的,目录里面对图片数据和标注数据这么去组织很方便后面使用yolov5;
(2)数据使用train2017.txt 表达,train2017.txt 里面写的是图片数据的路径,而labels目录yolov5会自行寻找。
训练YOLOv5
如果是其他数据:
首先需要修改yolov5/data/中coco.yaml脚本,指定path,我这里直接指定为绝对路径/data/dong_xie/yolov5/data/scripts/coco,指定train、val、test对应到之前的三个txt文件,nc和names也是必须的。
# YOLOv5 by Ultralytics, GPL-3.0 license
# COCO 2017 dataset http://cocodataset.org by Microsoft
# Example usage: python train.py --data coco.yaml
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: /data/dong_xie/yolov5/data/scripts/coco # dataset root dir
train: train2017.txt # train images (relative to 'path') 118287 images
val: val2017.txt # val images (relative to 'path') 5000 images
test: test-dev2017.txt # 20288 of 40670 images, submit to https://competitions.codalab.org/competitions/20794
# Classes
nc: 80 # number of classes
names: ['person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus', 'train', 'truck', 'boat', 'traffic light',
'fire hydrant', 'stop sign', 'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse', 'sheep', 'cow',
'elephant', 'bear', 'zebra', 'giraffe', 'backpack', 'umbrella', 'handbag', 'tie', 'suitcase', 'frisbee',
'skis', 'snowboard', 'sports ball', 'kite', 'baseball bat', 'baseball glove', 'skateboard', 'surfboard',
'tennis racket', 'bottle', 'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl', 'banana', 'apple',
'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza', 'donut', 'cake', 'chair', 'couch',
'potted plant', 'bed', 'dining table', 'toilet', 'tv', 'laptop', 'mouse', 'remote', 'keyboard', 'cell phone',
'microwave', 'oven', 'toaster', 'sink', 'refrigerator', 'book', 'clock', 'vase', 'scissors', 'teddy bear',
'hair drier', 'toothbrush'] # class names
然后就可以训练了,需要指定batch-size、data 、img、epochs 、weight 这几个关键参数。
python train.py --batch-size 60 --data coco.yaml --img 640 --epochs 600 --weight /data/dong_xie/yolov5/weights/yolov5m.pt
如果有多机多卡环境,可以去这里看看并行训练:https://blog.csdn.net/x1131230123/article/details/123840608
单机多卡我一般使用的一些命令参考:
python -m torch.distributed.launch --nproc_per_node 4 train.py --batch-size 680 --data intent.yaml --img 640 --epochs 300 --weight weights/yolov5s.pt --device 0,1,2,3 --name intent
python -m torch.distributed.launch --nproc_per_node 4 train.py --batch-size 680 --data intent.yaml --img 640 --epochs 300 --weight runs/train/intent5/weights/last.pt --device 0,1,2,3 --name intent
导出模型到其他框架
详细:https://github.com/ultralytics/yolov5/issues/251
export.py中代码说明,需要额外安装的环境:
Requirements:
$ pip install -r requirements.txt coremltools onnx onnx-simplifier onnxruntime openvino-dev tensorflow-cpu # CPU
$ pip install -r requirements.txt coremltools onnx onnx-simplifier onnxruntime-gpu openvino-dev tensorflow # GPU
Usage:
$ python path/to/export.py --weights yolov5s.pt --include torchscript onnx openvino engine coreml tflite ...
Inference:
$ python path/to/detect.py --weights yolov5s.pt # PyTorch
yolov5s.torchscript # TorchScript
yolov5s.onnx # ONNX Runtime or OpenCV DNN with --dnn
yolov5s.xml # OpenVINO
yolov5s.engine # TensorRT
yolov5s.mlmodel # CoreML (macOS-only)
yolov5s_saved_model # TensorFlow SavedModel
yolov5s.pb # TensorFlow GraphDef
yolov5s.tflite # TensorFlow Lite
yolov5s_edgetpu.tflite # TensorFlow Edge TPU
导出yolov5m.pt为onnx文件:
python export.py --weights weights/yolov5m.pt --include onnx
有诸多可选择的参数:
parser.add_argument('--data', type=str, default=ROOT / 'data/coco128.yaml', help='dataset.yaml path')
parser.add_argument('--weights', nargs='+', type=str, default=ROOT / 'yolov5s.pt', help='model.pt path(s)')
parser.add_argument('--imgsz', '--img', '--img-size', nargs='+', type=int, default=[640, 640], help='image (h, w)')
parser.add_argument('--batch-size', type=int, default=1, help='batch size')
parser.add_argument('--device', default='cpu', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--half', action='store_true', help='FP16 half-precision export')
parser.add_argument('--inplace', action='store_true', help='set YOLOv5 Detect() inplace=True')
parser.add_argument('--train', action='store_true', help='model.train() mode')
parser.add_argument('--keras', action='store_true', help='TF: use Keras')
parser.add_argument('--optimize', action='store_true', help='TorchScript: optimize for mobile')
parser.add_argument('--int8', action='store_true', help='CoreML/TF INT8 quantization')
parser.add_argument('--dynamic', action='store_true', help='ONNX/TF: dynamic axes')
parser.add_argument('--simplify', action='store_true', help='ONNX: simplify model')
parser.add_argument('--opset', type=int, default=12, help='ONNX: opset version')
parser.add_argument('--verbose', action='store_true', help='TensorRT: verbose log')
parser.add_argument('--workspace', type=int, default=4, help='TensorRT: workspace size (GB)')
parser.add_argument('--nms', action='store_true', help='TF: add NMS to model')
parser.add_argument('--agnostic-nms', action='store_true', help='TF: add agnostic NMS to model')
parser.add_argument('--topk-per-class', type=int, default=100, help='TF.js NMS: topk per class to keep')
parser.add_argument('--topk-all', type=int, default=100, help='TF.js NMS: topk for all classes to keep')
parser.add_argument('--iou-thres', type=float, default=0.45, help='TF.js NMS: IoU threshold')
parser.add_argument('--conf-thres', type=float, default=0.25, help='TF.js NMS: confidence threshold')
parser.add_argument('--include',
nargs='+',
default=['torchscript', 'onnx'],
help='torchscript, onnx, openvino, engine, coreml, saved_model, pb, tflite, edgetpu, tfjs')
还可以使用onnx文件进行val:
python val.py --weights weights/yolov5m.onnx --data coco.yaml
模型推理
看模型推理的意图是快速了解模型的输入输出,而看模型训练则需要关注损失函数和训练方式。
detect.py
修改源码detect.py中几个重要参数,权重改成正确路径,输入源改成一张图片。可以参考这里解析:https://icode.best/i/80558242058842。
parser.add_argument('--weights', nargs='+', type=str, default=ROOT / 'weights/yolov5m.pt', help='model path(s)')
parser.add_argument('--source', type=str, default=ROOT / 'data/images/bus.jpg',
help='file/dir/URL/glob, 0 for webcam')
# YOLOv5 by Ultralytics, GPL-3.0 license
"""
Run inference on images, videos, directories, streams, etc.
Usage - sources:
$ python path/to/detect.py --weights yolov5s.pt --source 0 # webcam
img.jpg # image
vid.mp4 # video
path/ # directory
path/*.jpg # glob
'https://youtu.be/Zgi9g1ksQHc' # YouTube
'rtsp://example.com/media.mp4' # RTSP, RTMP, HTTP stream
Usage - formats:
$ python path/to/detect.py --weights yolov5s.pt # PyTorch
yolov5s.torchscript # TorchScript
yolov5s.onnx # ONNX Runtime or OpenCV DNN with --dnn
yolov5s.xml # OpenVINO
yolov5s.engine # TensorRT
yolov5s.mlmodel # CoreML (macOS-only)
yolov5s_saved_model # TensorFlow SavedModel
yolov5s.pb # TensorFlow GraphDef
yolov5s.tflite # TensorFlow Lite
yolov5s_edgetpu.tflite # TensorFlow Edge TPU
"""
import argparse
import os
import sys
import torch
import torch.backends.cudnn as cudnn
from pathlib import Path
FILE = Path(__file__).resolve()
ROOT = FILE.parents[0] # YOLOv5 root directory
if str(ROOT) not in sys.path:
sys.path.append(str(ROOT)) # add ROOT to PATH
ROOT = Path(os.path.relpath(ROOT, Path.cwd())) # relative
from models.common import DetectMultiBackend
from utils.dataloaders import IMG_FORMATS, VID_FORMATS, LoadImages, LoadStreams
from utils.general import (LOGGER, check_file, check_img_size, check_imshow, check_requirements, colorstr, cv2,
increment_path, non_max_suppression, print_args, scale_coords, strip_optimizer, xyxy2xywh)
from utils.plots import Annotator, colors, save_one_box
from utils.torch_utils import select_device, time_sync
@torch.no_grad()
def run(
weights=ROOT / 'yolov5s.pt', # model.pt path(s)
source=ROOT / 'data/images', # file/dir/URL/glob, 0 for webcam
data=ROOT / 'data/coco128.yaml', # dataset.yaml path
imgsz=(640, 640), # inference size (height, width)
conf_thres=0.25, # confidence threshold
iou_thres=0.45, # NMS IOU threshold
max_det=1000, # maximum detections per image
device='', # cuda device, i.e. 0 or 0,1,2,3 or cpu
view_img=False, # show results
save_txt=False, # save results to *.txt
save_conf=False, # save confidences in --save-txt labels
save_crop=False, # save cropped prediction boxes
nosave=False, # do not save images/videos
classes=None, # filter by class: --class 0, or --class 0 2 3
agnostic_nms=False, # class-agnostic NMS
augment=False, # augmented inference
visualize=False, # visualize features
update=False, # update all models
project=ROOT / 'runs/detect', # save results to project/name
name='exp', # save results to project/name
exist_ok=False, # existing project/name ok, do not increment
line_thickness=3, # bounding box thickness (pixels)
hide_labels=False, # hide labels
hide_conf=False, # hide confidences
half=False, # use FP16 half-precision inference
dnn=False, # use OpenCV DNN for ONNX inference
):
source = str(source)
save_img = not nosave and not source.endswith('.txt') # save inference images
is_file = Path(source).suffix[1:] in (IMG_FORMATS + VID_FORMATS)
is_url = source.lower().startswith(('rtsp://', 'rtmp://', 'http://', 'https://'))
webcam = source.isnumeric() or source.endswith('.txt') or (is_url and not is_file)
if is_url and is_file:
source = check_file(source) # download
# Directories
save_dir = increment_path(Path(project) / name, exist_ok=exist_ok) # increment run
(save_dir / 'labels' if save_txt else save_dir).mkdir(parents=True, exist_ok=True) # make dir
# Load model
device = select_device(device)
model = DetectMultiBackend(weights, device=device, dnn=dnn, data=data, fp16=half)
stride, names, pt = model.stride, model.names, model.pt
imgsz = check_img_size(imgsz, s=stride) # check image size
# Dataloader
if webcam:
view_img = check_imshow()
cudnn.benchmark = True # set True to speed up constant image size inference
dataset = LoadStreams(source, img_size=imgsz, stride=stride, auto=pt)
bs = len(dataset) # batch_size
else:
dataset = LoadImages(source, img_size=imgsz, stride=stride, auto=pt)
bs = 1 # batch_size
vid_path, vid_writer = [None] * bs, [None] * bs
# Run inference
model.warmup(imgsz=(1 if pt else bs, 3, *imgsz)) # warmup
seen, windows, dt = 0, [], [0.0, 0.0, 0.0]
for path, im, im0s, vid_cap, s in dataset:
t1 = time_sync()
im = torch.from_numpy(im).to(device)
im = im.half() if model.fp16 else im.float() # uint8 to fp16/32
im /= 255 # 0 - 255 to 0.0 - 1.0
if len(im.shape) == 3:
im = im[None] # expand for batch dim
t2 = time_sync()
dt[0] += t2 - t1
# Inference
visualize = increment_path(save_dir / Path(path).stem, mkdir=True) if visualize else False
pred = model(im, augment=augment, visualize=visualize)
t3 = time_sync()
dt[1] += t3 - t2
# NMS
pred = non_max_suppression(pred, conf_thres, iou_thres, classes, agnostic_nms, max_det=max_det)
dt[2] += time_sync() - t3
# Second-stage classifier (optional)
# pred = utils.general.apply_classifier(pred, classifier_model, im, im0s)
# Process predictions
for i, det in enumerate(pred): # per image
seen += 1
if webcam: # batch_size >= 1
p, im0, frame = path[i], im0s[i].copy(), dataset.count
s += f'{i}: '
else:
p, im0, frame = path, im0s.copy(), getattr(dataset, 'frame', 0)
p = Path(p) # to Path
save_path = str(save_dir / p.name) # im.jpg
txt_path = str(save_dir / 'labels' / p.stem) + ('' if dataset.mode == 'image' else f'_{frame}') # im.txt
s += '%gx%g ' % im.shape[2:] # print string
gn = torch.tensor(im0.shape)[[1, 0, 1, 0]] # normalization gain whwh
imc = im0.copy() if save_crop else im0 # for save_crop
annotator = Annotator(im0, line_width=line_thickness, example=str(names))
if len(det):
# Rescale boxes from img_size to im0 size
det[:, :4] = scale_coords(im.shape[2:], det[:, :4], im0.shape).round()
# Print results
for c in det[:, -1].unique():
n = (det[:, -1] == c).sum() # detections per class
s += f"{n} {names[int(c)]}{'s' * (n > 1)}, " # add to string
# Write results
for *xyxy, conf, cls in reversed(det):
if save_txt: # Write to file
xywh = (xyxy2xywh(torch.tensor(xyxy).view(1, 4)) / gn).view(-1).tolist() # normalized xywh
line = (cls, *xywh, conf) if save_conf else (cls, *xywh) # label format
with open(f'{txt_path}.txt', 'a') as f:
f.write(('%g ' * len(line)).rstrip() % line + '\n')
if save_img or save_crop or view_img: # Add bbox to image
c = int(cls) # integer class
label = None if hide_labels else (names[c] if hide_conf else f'{names[c]} {conf:.2f}')
annotator.box_label(xyxy, label, color=colors(c, True))
if save_crop:
save_one_box(xyxy, imc, file=save_dir / 'crops' / names[c] / f'{p.stem}.jpg', BGR=True)
# Stream results
im0 = annotator.result()
if view_img:
if p not in windows:
windows.append(p)
cv2.namedWindow(str(p), cv2.WINDOW_NORMAL | cv2.WINDOW_KEEPRATIO) # allow window resize (Linux)
cv2.resizeWindow(str(p), im0.shape[1], im0.shape[0])
cv2.imshow(str(p), im0)
cv2.waitKey(1) # 1 millisecond
# Save results (image with detections)
if save_img:
if dataset.mode == 'image':
cv2.imwrite(save_path, im0)
else: # 'video' or 'stream'
if vid_path[i] != save_path: # new video
vid_path[i] = save_path
if isinstance(vid_writer[i], cv2.VideoWriter):
vid_writer[i].release() # release previous video writer
if vid_cap: # video
fps = vid_cap.get(cv2.CAP_PROP_FPS)
w = int(vid_cap.get(cv2.CAP_PROP_FRAME_WIDTH))
h = int(vid_cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
else: # stream
fps, w, h = 30, im0.shape[1], im0.shape[0]
save_path = str(Path(save_path).with_suffix('.mp4')) # force *.mp4 suffix on results videos
vid_writer[i] = cv2.VideoWriter(save_path, cv2.VideoWriter_fourcc(*'mp4v'), fps, (w, h))
vid_writer[i].write(im0)
# Print time (inference-only)
LOGGER.info(f'{s}Done. ({t3 - t2:.3f}s)')
# Print results
t = tuple(x / seen * 1E3 for x in dt) # speeds per image
LOGGER.info(f'Speed: %.1fms pre-process, %.1fms inference, %.1fms NMS per image at shape {(1, 3, *imgsz)}' % t)
if save_txt or save_img:
s = f"\n{len(list(save_dir.glob('labels/*.txt')))} labels saved to {save_dir / 'labels'}" if save_txt else ''
LOGGER.info(f"Results saved to {colorstr('bold', save_dir)}{s}")
if update:
strip_optimizer(weights) # update model (to fix SourceChangeWarning)
def parse_opt():
parser = argparse.ArgumentParser()
parser.add_argument('--weights', nargs='+', type=str, default=ROOT / 'weights/yolov5m.pt', help='model path(s)')
parser.add_argument('--source', type=str, default=ROOT / 'data/images/bus.jpg',
help='file/dir/URL/glob, 0 for webcam')
parser.add_argument('--data', type=str, default=ROOT / 'data/coco128.yaml', help='(optional) dataset.yaml path')
parser.add_argument('--imgsz', '--img', '--img-size', nargs='+', type=int, default=[640], help='inference size h,w')
parser.add_argument('--conf-thres', type=float, default=0.25, help='confidence threshold')
parser.add_argument('--iou-thres', type=float, default=0.45, help='NMS IoU threshold')
parser.add_argument('--max-det', type=int, default=1000, help='maximum detections per image')
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--view-img', action='store_true', help='show results')
parser.add_argument('--save-txt', action='store_true', help='save results to *.txt')
parser.add_argument('--save-conf', action='store_true', help='save confidences in --save-txt labels')
parser.add_argument('--save-crop', action='store_true', help='save cropped prediction boxes')
parser.add_argument('--nosave', action='store_true', help='do not save images/videos')
parser.add_argument('--classes', nargs='+', type=int, help='filter by class: --classes 0, or --classes 0 2 3')
parser.add_argument('--agnostic-nms', action='store_true', help='class-agnostic NMS')
parser.add_argument('--augment', action='store_true', help='augmented inference')
parser.add_argument('--visualize', action='store_true', help='visualize features')
parser.add_argument('--update', action='store_true', help='update all models')
parser.add_argument('--project', default=ROOT / 'runs/detect', help='save results to project/name')
parser.add_argument('--name', default='exp', help='save results to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
parser.add_argument('--line-thickness', default=3, type=int, help='bounding box thickness (pixels)')
parser.add_argument('--hide-labels', default=False, action='store_true', help='hide labels')
parser.add_argument('--hide-conf', default=False, action='store_true', help='hide confidences')
parser.add_argument('--half', action='store_true', help='use FP16 half-precision inference')
parser.add_argument('--dnn', action='store_true', help='use OpenCV DNN for ONNX inference')
opt = parser.parse_args()
opt.imgsz *= 2 if len(opt.imgsz) == 1 else 1 # expand
print_args(vars(opt))
return opt
def main(opt):
check_requirements(exclude=('tensorboard', 'thop'))
run(**vars(opt))
if __name__ == "__main__":
opt = parse_opt()
main(opt)
模型的输入输出尺寸
在源码中打上断点可以看到一些有用的信息,这里非常有意思,bus.jpg是 810 ∗ 1080 810*1080 810∗1080的一张图,letterbox(一个预处理函数)会让其封装为一张 480 ∗ 640 480*640 480∗640的图片,letterbox后续详说。
那么这里就是:
模型输入:img为(1,3,640,480) ,分别是batch、channel、高、宽。
模型输出:[1, 18900, 85]。
其中 18900 是这么来的:模型的下采样倍率是32、16、8,所以最终特征图平面格子数:
( 640 / 32 ∗ 480 / 32 + 640 / 16 ∗ 480 / 16 + 480 / 8 ∗ 640 / 8 ) ∗ 3 = 18900 。 (640/32*480/32+640/16*480/16+480/8*640/8)*3=18900。 (640/32∗480/32+640/16∗480/16+480/8∗640/8)∗3=18900。
乘以3是表示堆叠【 255 = 85 ∗ 3 255=85*3 255=85∗3】,同时也要注意对于一个点的有三个不同尺寸的anchor也反应到这里:

而通道85是这么来的:85表示的是 x,y,w,h,c,哪个类别的置信度,x和y是中心点预测,w和h是预测边框bbox的宽和高,c是bbox的预测置信度,其余80个变量就是当前bbox属于某个类别的置信度。
官方的模型介绍:https://github.com/ultralytics/yolov5/issues/6998
letterbox
在detect.py这个地方加断点可以看到,im就是想要传入模型的图片,这里的im是原始图片通过letterbox函数后出来的图片。

可以使用cv2.imwrite("2.jpg",cv2.cvtColor(np.transpose(im, (1,2,0)),cv2.COLOR_RGB2BGR))得到待输入的图片,输入到模型的图片是RGB的,为了能cv2.imwrite需要cv2.cvtColor一下;同时,输入到模型的图片是chw,使用np.transpose使其改为hwc的才能使用cv2.imwrite。
letterbox的效果:

读一下letterbox的源码是怎么做的:
def letterbox(im, new_shape=(640, 640), color=(114, 114, 114), auto=True, scaleFill=False, scaleup=True, stride=32):
# Resize and pad image while meeting stride-multiple constraints
shape = im.shape[:2] # current shape [height, width]
if isinstance(new_shape, int):
new_shape = (new_shape, new_shape) # 目标的尺寸
# Scale ratio (new / old)
r = min(new_shape[0] / shape[0], new_shape[1] / shape[1]) # 取小的那个
if not scaleup: # only scale down, do not scale up (for better val mAP)
r = min(r, 1.0) # scaleup是False的时候,只支持缩小,不支持小尺寸放大
# Compute padding
ratio = r, r # width, height ratios
new_unpad = int(round(shape[1] * r)), int(round(shape[0] * r)) # 这里较长的那条边已经满足640的要求,较短的不一定满足
dw, dh = new_shape[1] - new_unpad[0], new_shape[0] - new_unpad[1] # wh padding,较长的那条边不用padding,较短的需要padding
if auto: # minimum rectangle
dw, dh = np.mod(dw, stride), np.mod(dh, stride) # wh padding,太多padding不是好事,这里取余数,padding之后长度是32的倍数
elif scaleFill: # stretch
dw, dh = 0.0, 0.0
new_unpad = (new_shape[1], new_shape[0])
ratio = new_shape[1] / shape[1], new_shape[0] / shape[0] # width, height ratios
dw /= 2 # divide padding into 2 sides
dh /= 2
if shape[::-1] != new_unpad: # resize
im = cv2.resize(im, new_unpad, interpolation=cv2.INTER_LINEAR)
top, bottom = int(round(dh - 0.1)), int(round(dh + 0.1))
left, right = int(round(dw - 0.1)), int(round(dw + 0.1))
im = cv2.copyMakeBorder(im, top, bottom, left, right, cv2.BORDER_CONSTANT, value=color) # add border
return im, ratio, (dw, dh)
non_max_suppression
模型输入:img为(1,3,640,480) ,分别是batch、channel、高、宽。
模型输出:[1, 18900, 85]。
其中 18900 是这么来的:模型的下采样倍率是32、16、8,所以最终特征图平面格子数:(640/32480/32+640/16480/16+480/8*640/8)*3=18900。
其实就是18900个候选框,经过non_max_suppression之后候选框bbox就少了,yolov5里面non_max_suppression在用torch算子计算显存里的张量变量,也就是在显卡里进行的,有点不好理解,可以搜一下网上好理解的cpu版本看。
def non_max_suppression(prediction,
conf_thres=0.25,
iou_thres=0.45,
classes=None,
agnostic=False,
multi_label=False,
labels=(),
max_det=300):
"""Non-Maximum Suppression (NMS) on inference results to reject overlapping bounding boxes
Returns:
list of detections, on (n,6) tensor per image [xyxy, conf, cls]
"""
bs = prediction.shape[0] # batch size ,prediction的shape里第一个数值是batch
nc = prediction.shape[2] - 5 # number of classes,有多少个类别
xc = prediction[..., 4] > conf_thres # candidates,bbox的置信度要大于阈值
# Checks
assert 0 <= conf_thres <= 1, f'Invalid Confidence threshold {conf_thres}, valid values are between 0.0 and 1.0'
assert 0 <= iou_thres <= 1, f'Invalid IoU {iou_thres}, valid values are between 0.0 and 1.0'
# Settings
# min_wh = 2 # (pixels) minimum box width and height
max_wh = 7680 # (pixels) maximum box width and height,图片分辨率最大边不能超过这个数值
max_nms = 30000 # maximum number of boxes into torchvision.ops.nms()
time_limit = 0.3 + 0.03 * bs # seconds to quit after,处理时间太大就在循环中break
redundant = True # require redundant detections
multi_label &= nc > 1 # multiple labels per box (adds 0.5ms/img)
merge = False # use merge-NMS
t = time.time()
output = [torch.zeros((0, 6), device=prediction.device)] * bs
for xi, x in enumerate(prediction): # image index, image inference
# Apply constraints
# x[((x[..., 2:4] < min_wh) | (x[..., 2:4] > max_wh)).any(1), 4] = 0 # width-height
x = x[xc[xi]] # confidence
# Cat apriori labels if autolabelling
if labels and len(labels[xi]):
lb = labels[xi]
v = torch.zeros((len(lb), nc + 5), device=x.device)
v[:, :4] = lb[:, 1:5] # box
v[:, 4] = 1.0 # conf
v[range(len(lb)), lb[:, 0].long() + 5] = 1.0 # cls
x = torch.cat((x, v), 0)
# If none remain process next image
if not x.shape[0]:
continue
# Compute conf
x[:, 5:] *= x[:, 4:5] # conf = obj_conf * cls_conf
# Box (center x, center y, width, height) to (x1, y1, x2, y2)
box = xywh2xyxy(x[:, :4])
# Detections matrix nx6 (xyxy, conf, cls)
if multi_label:
i, j = (x[:, 5:] > conf_thres).nonzero(as_tuple=False).T
x = torch.cat((box[i], x[i, j + 5, None], j[:, None].float()), 1)
else: # best class only
conf, j = x[:, 5:].max(1, keepdim=True)
x = torch.cat((box, conf, j.float()), 1)[conf.view(-1) > conf_thres]
# Filter by class
if classes is not None:
x = x[(x[:, 5:6] == torch.tensor(classes, device=x.device)).any(1)]
# Apply finite constraint
# if not torch.isfinite(x).all():
# x = x[torch.isfinite(x).all(1)]
# Check shape
n = x.shape[0] # number of boxes
if not n: # no boxes
continue
elif n > max_nms: # excess boxes
x = x[x[:, 4].argsort(descending=True)[:max_nms]] # sort by confidence
# Batched NMS
c = x[:, 5:6] * (0 if agnostic else max_wh) # classes
boxes, scores = x[:, :4] + c, x[:, 4] # boxes (offset by class), scores
i = torchvision.ops.nms(boxes, scores, iou_thres) # NMS
if i.shape[0] > max_det: # limit detections
i = i[:max_det]
if merge and (1 < n < 3E3): # Merge NMS (boxes merged using weighted mean)
# update boxes as boxes(i,4) = weights(i,n) * boxes(n,4)
iou = box_iou(boxes[i], boxes) > iou_thres # iou matrix
weights = iou * scores[None] # box weights
x[i, :4] = torch.mm(weights, x[:, :4]).float() / weights.sum(1, keepdim=True) # merged boxes
if redundant:
i = i[iou.sum(1) > 1] # require redundancy
output[xi] = x[i]
if (time.time() - t) > time_limit:
LOGGER.warning(f'WARNING: NMS time limit {time_limit:.3f}s exceeded')
break # time limit exceeded
return output
MNN
安装
windows上太难编译了,直接CentOS上进行。
安装MNN:https://blog.csdn.net/x1131230123/article/details/125536750
安装boost :
yum update
yum install epel-release
yum install boost boost-thread boost-devel
安装opencv:
yum install opencv
转化
代码:https://github.com/techshoww/mnn-yolov5
转MNN:./MNN-1.1.0/build/MNNConvert -f ONNX --modelFile yolov5-sort-cpp/yolov5ss.onnx --MNNModel yolov5ss.mnn --bizCode MNN
~/MNN/build/MNNConvert -f ONNX --modelFile yolov5s.onnx --MNNModel yolov5s.mnn --bizCode MNN
代码测试
python 3.7 环境 pip install mnn opencv-python numpy 之后执行测试代码:
import MNN.expr as F
import cv2
import numpy as np
mnn_model_path = '/data/dong_xie/yolov5/weights/yolov5m.mnn'
image_path = '/data/dong_xie/yolov5/data/images/bus.jpg'
vars = F.load_as_dict(mnn_model_path)
inputVar = vars["images"]
# 查看输入信息
print('input shape: ', inputVar.shape)
print(inputVar.data_format)
# 修改原始模型的 NC4HW4 输入为 NCHW,便于输入
if (inputVar.data_format == F.NC4HW4):
inputVar.reorder(F.NCHW)
# 写入数据
im = cv2.imread("/data/dong_xie/yolov5/data/images/1.jpg")
im = cv2.resize(im, (640, 640))
im = cv2.cvtColor(im, cv2.COLOR_BGR2RGB)
# im.astype("float32")
im2 = im / 255
im2 = np.transpose(im2, (2, 0, 1))
im2 = np.expand_dims(im2, 0)
inputVar.write(im2.tolist())
# 查看输出结果
outputVar = vars['output']
print('output shape: ', outputVar.shape)
# print(outputVar.read())
# 切换布局便于查看结果
if (outputVar.data_format == F.NC4HW4):
outputVar = F.convert(outputVar, F.NCHW)
print(outputVar.read())
cls_id = F.argmax(outputVar, axis=1).read()
cls_probs = F.softmax(outputVar, axis=1).read()
print("cls id: ", cls_id)
print("cls prob: ", cls_probs[0, cls_id])
# cls id: [162]
# cls prob: [0.9519043]
模型的超参数
yolov5可以依靠遗传算法进化出好的超参数,但很消耗资源。简单的可以直接:https://github.com/ultralytics/yolov5/issues/5653。
默认的几个超参数文件对应到不同的模型尺寸以供选择:
finetune.yaml: evolved on VOC
finetune_objects365: evolved on Objects365
scratch: default
scratch_low: for smaller models, i.e. v5n, v5s
scratch_med: for medium models, i.e. v5m
scratch_high: for large models, i.e. v3, v3-spp, v5l, v5x
模型的训练数据文件组织
data.yaml可以简单写为:
path: /data/dong_xie/datasets # dataset root dir
train: train.txt
val: val.txt
test: test.txt
# Classes
nc: 1 # number of classes
names: [ 'idcard' ] # class names
# python train.py --batch-size 32 --data data.yaml --name helloworld --img 640 --epochs 50 --weight weights/yolov5m.pt
也可以写成:
path: /data/dong_xie/datasets # dataset root dir
train: train/images
val: val/images
test: test/images
# Classes
nc: 1 # number of classes
names: [ 'idcard' ] # class names
# python train.py --batch-size 32 --data data.yaml --name helloworld --img 640 --epochs 50 --weight weights/yolov5m.pt
文件的组织是:
/data/dong_xie/datasets
-------------------------------train
-------------------------------train/images
-------------------------------train/labels
-------------------------------val
-------------------------------val/images
-------------------------------val/labels
-------------------------------test
-------------------------------test/images
-------------------------------train.txt
-------------------------------val.txt
-------------------------------test.txt
第一种写法是我常用的,通过在train.txt中书写罗列出图片名称(相对路径或者绝对路径均可),yolov5会自己寻找对应labels。
第二种写法就不需要train.txt,yolov5自行list出images路径中的图片,也会自己寻找对应labels。
yolov5是依靠把图片路径的images换成labels,从而找到图片对应的labels。目前这段代码在utils/dataloaders.py中:
def img2label_paths(img_paths):
# Define label paths as a function of image paths
# sa, sb = f'{os.sep}images{os.sep}', f'{os.sep}labels{os.sep}' # /images/, /labels/ substrings
sa, sb = f'{os.sep}images{os.sep}', f'{os.sep}labels{os.sep}' # /images/, /labels/ substrings
return [sb.join(x.rsplit(sa, 1)).rsplit('.', 1)[0] + '.txt' for x in img_paths]
意外中断后恢复训练,训练过程中想修改参数
train.py中这个参数用于控制:
parser.add_argument('--resume', nargs='?', const=True, default=False, help='resume most recent training')
哪些情况使用这个参数:
(1)人为中止:模型训练epochs给多了,懒得等待继续训练。可直接中断当前训练后,修改训练文件夹中的opt.yaml,然后再恢复训练。
(2)意外中止:终端意外断开或者按键按错了,训练意外中止。
使用:
python -m torch.distributed.launch --nproc_per_node 4 train.py --batch-size 680 --data intent.yaml --img 640 --device 0,1,2,3 --name intent --resume