MacOS安装PyAudio
brew install portaudio
pip install pyaudiodocs:https://people.csail.mit.edu/hubert/pyaudio/docs/
pyaudio对象的open()方法:
- rate:取样频率
- channels:声道数
- format:取样值的量化格式 (paFloat32, paInt32, paInt24, paInt16, paInt8 …)
- input:输入流标志,如果为True的话则开启输入流
- output:输出流标志,如果为True的话则开启输出流
- input_device_index:输入流所使用的设备的编号,如果不指定的话,则使用系统的缺省设备
- output_device_index:输出流所使用的设备的编号,如果不指定的话,则使用系统的缺省设备
- frames_per_buffer:底层的缓存的块的大小,底层的缓存由N个同样大小的块组成
- start:指定是否立即开启输入输出流,缺省值为True
pyaudio.paFloat32:每帧4个字节,如果channels=2,那么wave_write()应该设置setsampwidth(8)
pyaudio.paInt16:每帧2个字节,如果channels=2,那么wave_write()应该设置setsampwidth(4);若channels=1,setsampwidth(2)
音频信号是模拟信号,我们需要将其保存为数字信号,才能对语音进行算法操作,WAV是Microsoft开发的一种声音文件格式,通常被用来保存未压缩的声音数据。
- 通道数:同时有个几个设备在进行音频的采样;
- 采样频率: 每秒从连续信号中提取并组成离散信号的采样个数,用赫兹(Hz)来表示。每秒内对声音信号采样样本的总数目,44100Hz采样频率意味着每秒钟信号被分解成44100份。换句话说,每隔1/144100秒就会存储一次,如果采样率高,那么媒体播放音频时会感觉信号是连续的;
- 量化位数(Bit depth):也称为“位深”,每个采样点中信息的比特(bit)数。1 byte等于8 bit;
- 比特率(Bit rate): 每秒处理多少个Bit。比如一个单声道,用44.1KHz/16Bit的配置来说,它的比特率就为44100161=705600,单位是bit/s(或者bps)。在对音频进行压缩时,越高的比特率,其音质也就越好;
- 采样位数(采样格式):如何描述每个采样点呢?用什么方法独立每个采样点值的区别呢?也就是如何度量每个采样点,而这正是采样格式出现的意义。通常使用16bit(2字节),也就是2的16次方,共有65536个不同的度量值,这样采样位数越高,音频度量化的就越精细,音质同样也就越高;
- 采样个数,对于采样频率,采样频率是一秒采样的个数,例如48000HZ,每秒采样个数为48000,44100HZ,每秒采样个数为44100;(从一帧音频帧的播放时长中就可以看出,范围在21ms,24ms,26ms范围左右,而视频一帧的时长一般是40ms,人体对图片变化的感知也在20-60ms内感知良好,采样数固定,是在考虑人眼,与音视频同步的方便程度,音频压缩的质量等方面因素后,最终确定下来的采样数。)
- 例如1s采样了10个采样点,那么需要区分这10个采样点,就需要给它一个范围值区分,一般以2字节16位的来保存这个值,所以既然每个采样点占2字节,那么所有采样点的总字节=采样个数 x 其所占字节数。即10 x 2 = 20。若为双通道采样,那么就是2 x 10 x 2 = 40。
- 一帧音频的大小(字节) = 通道数 x 采样个数 x 采样位数
- 一帧播放时间(毫秒) = sample样本数 * 1000 / 采样率
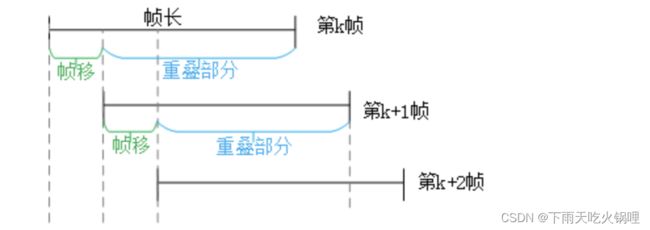
语音信号是一个非平稳的时变信号,但语音信号是由声门的激励脉冲通过声道形成的,而声道(人的口腔、鼻腔)的肌肉运动是缓慢的,所以“短时间”(10~30ms)内可以认为语音信号是平稳时不变的。由此构成了语音信号的“短时分析技术”。在短时分析中,将语音信号分为一段一段的语音帧,每一帧一般取10~30ms,研究就建立在每一帧的语音特征分析上。
通常对信号截断、分帧需要加窗,因为截断都有频域能量泄露,而窗函数可以减少截断带来的影响。
在分帧中,相邻两帧之间会有一部分重叠,帧长(wlen) = 重叠(overlap)+帧移(inc),如果相邻两帧之间不重叠,那么由于窗函数的形状,截取到的语音帧边缘会出现损失,所以要设置重叠部分。