自训练的人脸带口罩判断算法
人脸系列文章目录
文章目录
- 人脸系列文章目录
- 前言
- 一、准备数据集
- 二、模型搭建
-
- 1.数据处理
- 2.模型选择
- 3.loss func 和 lr scheduler
- 4.pytorch使用fp16训练
- 5.训练调参
- 5.推理demo
- 总结
前言
使用widerface(带关键点)+一部分戴口罩人脸训练的人脸检测模型,可以很好的泛化检测出戴口罩的人脸。但无法判断出检测出的人脸是否戴口罩。目前开源的大部分是一种二类目标检测算法FaceMaskDetection来进行口罩判断判断,但此类算法一般要么不够轻量,要么人脸检测性能比较低。漏检率高,并且此类算法不带关键点。基于需求我训练一个戴口罩和不带口罩的二分类算法来做人脸口罩判断。最终精度和速度都能够满足要求。
GitHub:https://github.com/zengwb-lx/FaceMaskClassification
一、准备数据集
真实口罩人脸识别数据集:
1、https://github.com/X-zhangyang/Real-World-Masked-Face-Dataset
2、https://github.com/chandrikadeb7/Face-Mask-Detection
3、网上爬取
获得训练集:戴口罩1W张,不带口罩3W张图片,测试集各两千张图片

数据清洗是最好能够保持样本多样性,脏数据要剔除,否则很影响训练。
二、模型搭建
代码参考于此pytorch_img_classification_for_competition
1.数据处理
112x112的输入并做简单数据增强
normalize_imgnet = transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
transform_train = transforms.Compose([
transforms.RandomResizedCrop(configs.input_size),
transforms.RandomHorizontalFlip(p=0.5),
# transforms.RandomVerticalFlip(p=0.5),
transforms.ColorJitter(brightness=0.5, contrast=0.5),
transforms.ToTensor(),
normalize_imgnet
])
transform_val = transforms.Compose([
transforms.Resize(int(configs.input_size * 1.2)),
transforms.CenterCrop(configs.input_size),
transforms.ToTensor(),
normalize_imgnet
])
2.模型选择
使用mobilenetv2,如果部署算力有限可以选择mobilenetv2的裁剪版0.25或0.5。
from torchvision import models
model = models.mobilenet_v2(pretrained=True)
in_features = model.classifier[1].in_features
model.classifier = nn.Sequential(
nn.BatchNorm1d(in_features),
nn.Dropout(0.5),
nn.Linear(in_features, 2),
)
model.cuda()
3.loss func 和 lr scheduler
使用mobilenetv2,如果部署算力有限可以选择mobilenetv2的裁剪版0.25或0.5。
# choose loss func,default is CE
if configs.loss_func == "LabelSmoothCE":
criterion = LabelSmoothingLoss(0.1, configs.num_classes).cuda()
elif configs.loss_func == "CrossEntropy":
criterion = nn.CrossEntropyLoss().cuda()
elif configs.loss_func == "FocalLoss":
criterion = FocalLoss(gamma=2).cuda()
else:
criterion = nn.CrossEntropyLoss().cuda()
optimizer = get_optimizer(model)
# set lr scheduler method
if configs.lr_scheduler == "step":
scheduler = torch.optim.lr_scheduler.StepLR(optimizer,step_size=10,gamma=0.1)
elif configs.lr_scheduler == "on_loss":
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='min', factor=0.2, patience=5, verbose=False)
elif configs.lr_scheduler == "on_acc":
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='max', factor=0.2, patience=5, verbose=False)
else:
scheduler = torch.optim.lr_scheduler.StepLR(optimizer,step_size=6,gamma=0.1)
4.pytorch使用fp16训练
使用mobilenetv2,如果部署算力有限可以选择mobilenetv2的裁剪版0.25或0.5。
if configs.fp16:
print('training in fp16')
model, optimizer = amp.initialize(model, optimizer,
opt_level=configs.opt_level,
keep_batchnorm_fp32= None if configs.opt_level == "O1" else configs.keep_batchnorm_fp32
)
5.训练调参
由于是简单分类任务,128batch训练35epoch就收敛
Learning Rate Train Loss Valid Loss Train Acc. Valid Acc.
0.000016 0.033926 0.047094 98.658925 98.836634
5.推理demo
推理阶段数据预处理必须和训练阶段保持一致,否则会影响准确率。2070S单张图片仅需4ms,采用mobilenet作为backbone,模型转换到推理框架部署到嵌入式平台也是非常容易的。
best_cpk = './checkpoints/best.pth'
checkpoint = torch.load(best_cpk)
cudnn.benchmark = True
# model = get_model()
model = models.mobilenet_v2()
in_features = model.classifier[1].in_features
model.classifier = nn.Sequential(
nn.BatchNorm1d(in_features),
nn.Dropout(0.5),
nn.Linear(in_features, configs.num_classes),
)
model.load_state_dict(checkpoint)
model.cuda().eval()
# test_files = pd.read_csv(configs.submit_example)
data_root = './data'
test_transform = transforms.Compose([transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],std=[0.229, 0.224, 0.225])])
i = 0
with torch.no_grad():
for root, dir, files in os.walk(data_root):
files = [os.path.join(root, file) for file in files]
for file in files:
inputs = cv2.imread(file)
inputs = cv2.cvtColor(inputs, cv2.COLOR_BGR2RGB)
inputs = cv2.resize(inputs, (112, 112))
t1 = time.time()
inputs = test_transform(inputs).unsqueeze(0).cuda()
outputs = model(inputs)
# print(outputs)
outputs = torch.nn.functional.softmax(outputs, dim=1).data.cpu().numpy()[0][0]
print('tttttt',time.time() - t1, outputs)
# print(outputs)
if outputs > 0.5:
mask = 0
i += 1
print('no mask', file, i)
else:
mask = 1
# i += 1
# print('with mask', file, i)
总结
insightface开源的RetinaFaceAntiCov,非常好
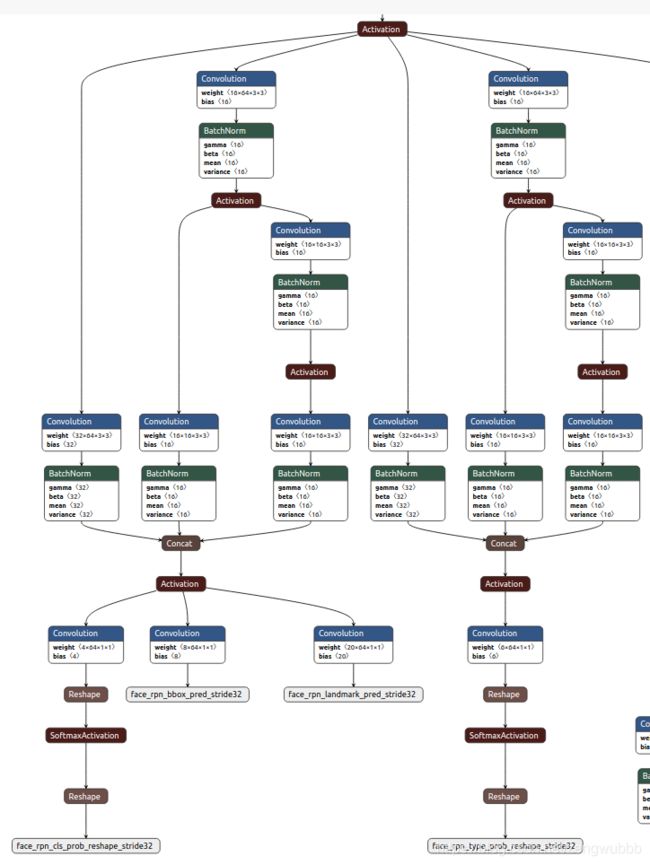
在RetinaFace的基础上增加了一个口罩判断的head,但是测试发现这个轻量模型人脸漏检率高,达不到人脸检测性能的要求。如有需要我们自己复现重新训练一个更高精度的模型。