基于分布式数据库集群的大数据职位信息统计
目录
任务一:
MongoDB 分布式集群关键配置信息截图(启动参数文件、初始化参数文件、启动命令等)
ch0的参数文件配置:
编辑 ch1的参数文件配置:
编辑chconfig的参数文件配置:
router的参数文件配置:
初始化参数文件配置:
编辑 启动命令文件配置:
启动截图:
MongoDB 分布式集群启动状态截图
任务二:
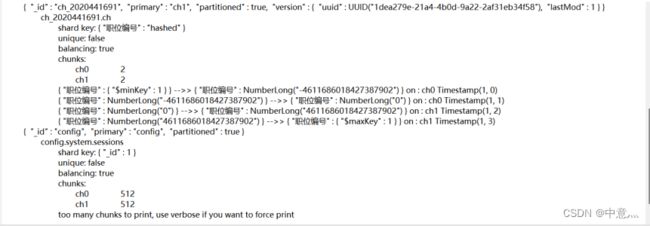
MongoDB分布式集群分片管理(截图)
MongoDB 分布式集群数据导入与分片状态查询(截图)
任务三:程序代码及运行结果截图:
(1)列出数据中重庆的所有区县名称
(2)查询月薪8000及以上的职位信息:"公司","招聘岗位","薪资"
(3)查询学历要求不低于"硕士"且提供"五险一金"和"周末双休"的重庆"公司"、"招聘岗位"、"上班地址"、"学历"和"福利标签"。
(4)将"工作经验-下限"要求为0的改为{"工作经验":"不限"}
(5)统计不同"学历"要求的总招聘人数
(6)统计各个城市各个行业的职位数量,以城市和职位数量多少排序
试题内容及要求:
学校委托你建设新的职业指导数据统计分析系统,以便及时让学生了解当前就业趋势。经过一番调研,你发现各招聘网站的职位信息多样,即使同一个网站的职位信息往往也具有多变的数据结构。这种情况下,建立传统的关系数据库进行数据存储和分析统计颇为不便。于是你决定选择MongoDB搭建数据非关系型数据库,这样通过爬虫采集的招聘职位信息可以直接存储而不需要受限于表结构。
为了完成此项目,请完成以下任务:
任务一:该系统拟选择MongoDB作为分析数据库,并采用分布式集群的架构以获得更好的数据安全、高可用性以及性能保障。下图为MongoDB分布式集群部署规划图,请根据该图搭建一个MongoDB分布式集群:

注意: 分片副本集名称为xx0,xx1, 配置副本集名称为xxconfig,其中xx为你的姓名拼音首字母。
任务二:为了验证数据分布情况及进行统计分析程序开发,请创建一个MongoDB测试数据库,数据库名为你的姓名拼音首字母_学号,并请自行选择片键创建一个分片集合xx(你的姓名拼音首字母),需满足数据均匀分布的要求。测试数据已经写入了附件的load_jobs.js脚本,请补完该脚本并将测试数据加载到jobs集合。请查看集合数据熟悉数据文档结构,并查看数据的分布状况。
任务三:请编写常用操作的MongoDB Shell命令/脚本:
- 列出数据中重庆的所有区县名称
- 查询月薪8000及以上的职位信息:"公司","招聘岗位","薪资"
- 查询学历要求不低于"硕士"且提供"五险一金"和"周末双休"的重庆"公司"、"招聘岗位"、"上班地址"、"学历"和"福利标签"。
- 将"工作经验-下限"要求为0的改为{“工作经验”:“不限”}
- 统计不同“学历”要求的总招聘人数,从多到少排列。
- 统计各个城市各个行业的职位数量,以城市和职位数量多少排序
任务一:
-
MongoDB 分布式集群关键配置信息截图(启动参数文件、初始化参数文件、启动命令等)
ch0的参数文件配置:
 ch1的参数文件配置:
ch1的参数文件配置:
 chconfig的参数文件配置:
chconfig的参数文件配置:

router的参数文件配置:

初始化参数文件配置:
 启动命令文件配置:
启动命令文件配置:


启动截图:

-
MongoDB 分布式集群启动状态截图


任务二:
-
MongoDB分布式集群分片管理(截图)


-
MongoDB 分布式集群数据导入与分片状态查询(截图)


任务三:程序代码及运行结果截图:
前言:后续代码均用python所编写,库的导入和数据连接放在这里(不建议大家抄我的,我上课没认真听,写不来mongdb的命令,就用python写的)
1.import pymongo
2.import pandas as pd
3.client = pymongo.MongoClient(host='localhost', port=27017)
4.db=client.ch_2020441691
5.collection=db.ch(1)列出数据中重庆的所有区县名称
1.for i in collection.aggregate([{"$match":{"所在地.城市":"重庆"}},{"$group":{"_id":"$所在地.区县"}}]):
2. print(i)
(2)查询月薪8000及以上的职位信息:"公司","招聘岗位","薪资"
1.money=[]
2.pipeline=[{"$group":{"_id":"$薪资.类型"}}]
3.for i in collection.aggregate(pipeline):
4. money.append(i['_id'])
5.print(money)
6.pipeline=[{"$project":{"公司":1,"招聘岗位":1,"薪资":1}}]
7.for i in collection.aggregate(pipeline):
8. if i['薪资']['类型']==None:
9. pass
10. if i['薪资']['类型']=="千/月":
11. if i['薪资']['下限']>=8:
12. print(i)
13. if i['薪资']['类型']=="万/月":
14. if i['薪资']['下限']*10>=8:
15. print(i)
16. if i['薪资']['类型']=='万/年':
17. if i['薪资']['下限']*10/12>=8:
18. print(i)
(3)查询学历要求不低于"硕士"且提供"五险一金"和"周末双休"的重庆"公司"、"招聘岗位"、"上班地址"、"学历"和"福利标签"。
1.edu=[]
2.pipeline=[{"$group":{"_id":"$学历"}}]
3.for i in collection.aggregate(pipeline):
4. edu.append(i['_id'])
5.pipeline=[{"$project":{"公司":1,"招聘岗位":1,"上班地址":1,'学历':1,"福利标签":1}}]
6.keys=["公司","招聘岗位","上班地址",'学历',"福利标签"]
7.for i in collection.find():
8. if (i['学历']=="博士" or i['学历']=="硕士") and ("五险一金" in i['福利标签'] )and ("周末双休" in i['福利标签']) and i['所在地']['城市']=="重庆":
9. i=pd.Series(i)
10. print(i[keys])
(4)将"工作经验-下限"要求为0的改为{"工作经验":"不限"}
1.myquery = { "工作经验.下限":0 }
2.newvalues = { "$set": { "工作经验.下限":'不限' } }
3.x=collection.update_many(myquery, newvalues)
4.print(x.modified_count)
5.for i in collection.find({"工作经验.下限":'不限'}):
6. print(i['工作经验'])

(5)统计不同"学历"要求的总招聘人数
1.pipeline=[{"$group":{"_id":"$学历",'招聘总人数': {'$sum': '$所招人数'}}},{"$sort":{"招聘总人数":-1}}]
2.for i in collection.aggregate(pipeline):
3. print(i)
(6)统计各个城市各个行业的职位数量,以城市和职位数量多少排序
1.pipeline=[{"$unwind":"$所属行业"},{"$group":{"_id":{"城市":"$所在地.城市","行业":"$所属行业"},"职位数量":{"$sum":"$所招人数"}}},{"$sort":{"职位数量":-1,"城市":-1}}]
2.for i in collection.aggregate(pipeline):
3. print(i)