keras ImageDataGenerator类的个人笔记
参考网站:
https://keras-cn-docs.readthedocs.io/zh_CN/latest/blog/image_classification_using_very_little_data/
https://blog.csdn.net/jacke121/article/details/79245732
https://blog.csdn.net/dod_jdi/article/details/78379781
一些个人理解:
1 Keras的数据提升类的功能为:每次训练的时候,对拿到的数据进行随机变换处理,这使得拿到相同数据的不同的epoch随机之后喂给模型的数据是不一样的,增加随机性。
ImageDataGenerator的参数:
keras.preprocessing.image.ImageDataGenerator(featurewise_center=False,
samplewise_center=False,
featurewise_std_normalization = False,
samplewise_std_normalization = False,
zca_whitening = False,
rotation_range = 0.,
width_shift_range = 0.,
height_shift_range = 0.,
shear_range = 0.,
zoom_range = 0.,
channel_shift_range = 0.,
fill_mode = 'nearest',
cval = 0.0,
horizontal_flip = False,
vertical_flip = False,
rescale = None,
preprocessing_function = None,
data_format = K.image_data_format(),
)
不常用:
featurewise_center:布尔值,使输入数据集去中心化(均值为0), 按feature执行。
samplewise_center:布尔值,使输入数据的每个样本均值为0。
featurewise_std_normalization:布尔值,将输入除以数据集的标准差以完成标准化, 按feature执行。
samplewise_std_normalization:布尔值,将输入的每个样本除以其自身的标准差。
zca_whitening:布尔值,对输入数据施加ZCA白化。
preprocessing_function: 将被应用于每个输入的函数。该函数将在任何其他修改之前运行。该函数接受一个参数,为一张图片(秩为3的numpy array),并且输出一个具有相同shape的numpy array
data_format:字符串,“channel_first”或“channel_last”之一,代表图像的通道维的位置。该参数是Keras 1.x中的image_dim_ordering,“channel_last”对应原本的“tf”,“channel_first”对应原本的“th”。以128x128的RGB图像为例,“channel_first”应将数据组织为(3,128,128),而“channel_last”应将数据组织为(128,128,3)。该参数的默认值是~/.keras/keras.json中设置的值,若从未设置过,则为“channel_last”。
常用:
rotation_range:整数,数据提升时图片随机转动的角度。随机选择图片的角度,是一个0~180的度数,取值为0~180。
我的理解是比如给一个40,那么后续图像随机转动的角度会在0~40之间
# -*- coding: utf-8 -*-
"""
Created on Thu Jul 26 10:42:59 2018
@author: th
"""
from keras.preprocessing.image import ImageDataGenerator, array_to_img, img_to_array, load_img
datagen = ImageDataGenerator(
rotation_range=180)
img = load_img('zc_0.jpg') # this is a PIL image
x = img_to_array(img) # this is a Numpy array with shape (3, 150, 150)
x = x.reshape((1,) + x.shape) # this is a Numpy array with shape (1, 3, 150, 150)
# the .flow() command below generates batches of randomly transformed images
# and saves the results to the `preview/` directory
i = 0
for batch in datagen.flow(x, batch_size=1,
save_to_dir='lalala', save_prefix='zc', save_format='jpeg'):
i += 1
if i > 30:
break # otherwise the generator would loop indefinitely测试一下,如果这里参数选10,最后得到的30张图像:

如果选180,得到:

因此,以下参数的道理类似。
width_shift_range:浮点数,图片宽度的某个比例,数据提升时图片随机水平偏移的幅度。
height_shift_range:浮点数,图片高度的某个比例,数据提升时图片随机竖直偏移的幅度。
height_shift_range和width_shift_range是用来指定水平和竖直方向随机移动的程度,这是两个0~1之间的比例。
shear_range:浮点数,剪切强度(逆时针方向的剪切变换角度)。是用来进行剪切变换的程度。
zoom_range:浮点数或形如[lower,upper]的列表,随机缩放的幅度,若为浮点数,则相当于[lower,upper] = [1 - zoom_range, 1+zoom_range]。用来进行随机的放大。
channel_shift_range:浮点数,随机通道偏移的幅度。
fill_mode:‘constant’,‘nearest’,‘reflect’或‘wrap’之一,当进行变换时超出边界的点将根据本参数给定的方法进行处理
cval:浮点数或整数,当fill_mode=constant时,指定要向超出边界的点填充的值。
horizontal_flip:布尔值,进行随机水平翻转。随机的对图片进行水平翻转,这个参数适用于水平翻转不影响图片语义的时候。
vertical_flip:布尔值,进行随机竖直翻转。
rescale: 值将在执行其他处理前乘到整个图像上,我们的图像在RGB通道都是0~255的整数,这样的操作可能使图像的值过高或过低,所以我们将这个值定为0~1之间的数。
Dropout通过防止一层看到两次完全一样的模式来防止过拟合,相当于也是一种数据提升的方法。(你可以说dropout和数据提升都在随机扰乱数据的相关性)
dropout是指在深度学习网络的训练过程中,对于神经网络单元,按照一定的概率将其暂时从网络中丢弃。注意是暂时,对于随机梯度下降来说,由于是随机丢弃,故而每一个mini-batch都在训练不同的网络。
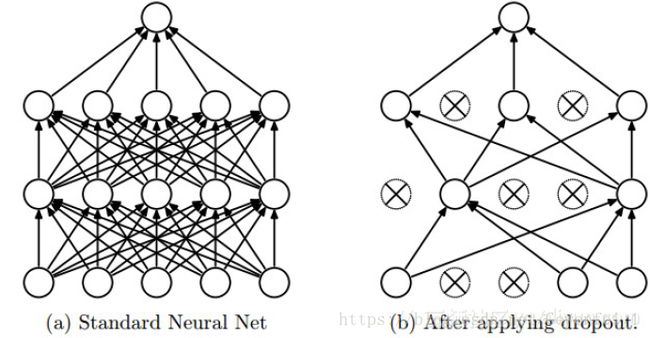

当前Dropout被大量利用于全连接网络,而且一般人为设置为0.5或者0.3,而在卷积隐藏层由于卷积自身的稀疏化以及稀疏化的ReLu函数的大量使用等原因,Dropout策略在卷积隐藏层中使用较少。需要根据具体的网路,具体的应用领域进行尝试。
使用.flow_from_directory()来从我们的jpgs图片中直接产生数据和标签。
# this is the augmentation configuration we will use for training
train_datagen = ImageDataGenerator(
rescale=1./255,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True)
# this is the augmentation configuration we will use for testing:
# only rescaling
test_datagen = ImageDataGenerator(rescale=1./255)
# this is a generator that will read pictures found in
# subfolers of 'data/train', and indefinitely generate
# batches of augmented image data
train_generator = train_datagen.flow_from_directory(
'data/train', # this is the target directory
target_size=(150, 150), # all images will be resized to 150x150
batch_size=32,
class_mode='binary') # since we use binary_crossentropy loss, we need binary labels
# this is a similar generator, for validation data
validation_generator = test_datagen.flow_from_directory(
'data/validation',
target_size=(150, 150),
batch_size=32,
class_mode='binary')最后,关于使用预训练网络的bottleneck特征
如何使用一个别人训练好的模型用到自己的问题上?且别人的模型没有识别过相关的内容?