Pytorch之VGG网络模型实现
GG-Network是K. Simonyan和A. Zisserman在论文“Very Deep Convolutional Networks for Large-Scale Image Recognition”中提出的卷积神经网络模型。该架构在 ImageNet 中实现了 92.7% 的 top-5 测试准确率,该网络拥有超过 1400 万张属于 1000 个类别的图像。它是深度学习领域的著名架构之一,将第1层和第2层的大内核大小的过滤器分别替换为11和5,显示了对 AlexNet 架构的改进,多个3×3内核大小的过滤器相继出现。它经过数周的训练,使用的是 NVIDIA Titan Black GPU。
架构简介:
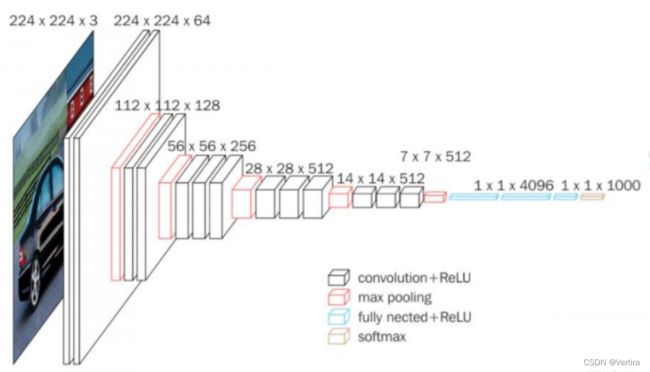
卷积神经网络的输入是固定大小的 224 × 224 RGB 图像。它所做的唯一预处理是从每个像素中减去在训练数据集上计算的平均 RGB 值,然后图像通过一堆卷积(Conv.)层,其中有一个非常小的感受野为 3 × 3 的过滤器,这是捕捉左/右、上/下概念的最小尺寸和中心部分。在其中一种配置中,它还使用 1 × 1 卷积滤波器,可以将其视为输入通道的线性变换,然后是非线性变换,卷积步幅固定为 1 个像素;卷积层输入的空间填充使得卷积后空间分辨率保持不变,即对于 3 × 3 Conv,填充为 1 个像素,然后空间池化由 5 个最大池化层执行,其中 16 个最大池化层跟在一些 Conv 层之后,但不是所有的 Conv 层。这个最大池化是在一个 2 × 2 像素的窗口上执行的,步长为 2。
论文里面的网络结构
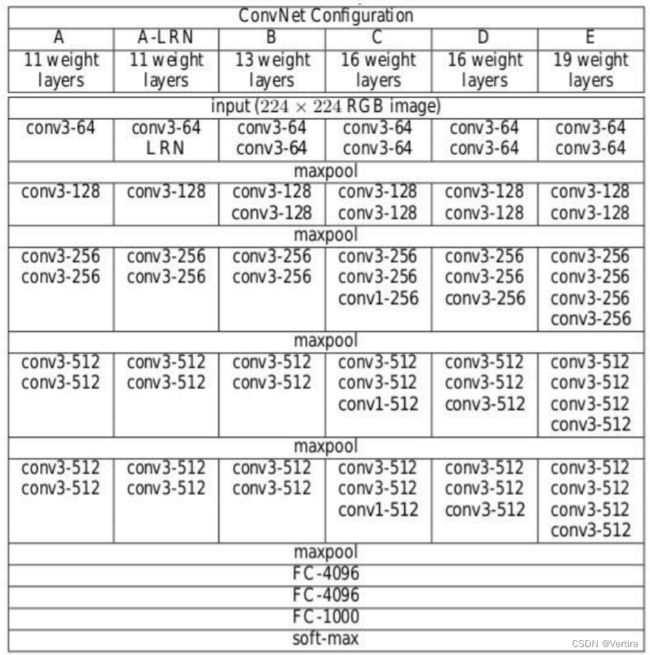
可以看到 这个是针对输入图像为224x224的尺寸设计的网络。如果你的不是,请resize()图像的尺寸为224x224,然后才能使用这个网络
废话少说,上代码
import torch
import torch.nn as nn
VGG_types = {
"VGG11": [64, "M", 128, "M", 256, 256, "M", 512, 512, "M", 512, 512, "M"],
"VGG13": [64, 64, "M", 128, 128, "M", 256, 256, "M", 512, 512, "M", 512, 512, "M"],
"VGG16": [64,64,"M",128,128,"M",256,256,256,"M",512,512,512,"M",512,512,512,"M",],
"VGG19": [64,64,"M",128,128,"M",256,256,256,256,"M",512,512,512,512,
"M",512,512,512,512,"M",],}
VGGType = "VGG16"
class VGGnet(nn.Module):
def __init__(self, in_channels=3, num_classes=1000):
super(VGGnet, self).__init__()
self.in_channels = in_channels
self.conv_layers = self.create_conv_layers(VGG_types[VGGType])
self.fcs = nn.Sequential(
nn.Linear(512 * 7 * 7, 4096),
nn.ReLU(),
nn.Dropout(p=0.5),
nn.Linear(4096, 4096),
nn.ReLU(),
nn.Dropout(p=0.5),
nn.Linear(4096, num_classes),
)
def forward(self, x):
x = self.conv_layers(x)
x = x.reshape(x.shape[0], -1)
x = self.fcs(x)
return x
def create_conv_layers(self, architecture):
layers = []
in_channels = self.in_channels
for x in architecture:
if type(x) == int:
out_channels = x
layers += [
nn.Conv2d(
in_channels=in_channels,
out_channels=out_channels,
kernel_size=(3, 3),
stride=(1, 1),
padding=(1, 1),
),
nn.BatchNorm2d(x),
nn.ReLU(),
]
in_channels = x
elif x == "M":
layers += [nn.MaxPool2d(kernel_size=(2, 2), stride=(2, 2))]
return nn.Sequential(*layers)
if __name__ == "__main__":
device = "cuda" if torch.cuda.is_available() else "cpu"
model = VGGnet(in_channels=3, num_classes=500).to(device)
print(model)
x = torch.randn(1, 3, 224, 224).to(device)
print(model(x).shape)
看一下 这个网络的各层参数量吧
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 64, 224, 224] 640
BatchNorm2d-2 [-1, 64, 224, 224] 128
ReLU-3 [-1, 64, 224, 224] 0
Conv2d-4 [-1, 64, 224, 224] 36,928
BatchNorm2d-5 [-1, 64, 224, 224] 128
ReLU-6 [-1, 64, 224, 224] 0
MaxPool2d-7 [-1, 64, 112, 112] 0
Conv2d-8 [-1, 128, 112, 112] 73,856
BatchNorm2d-9 [-1, 128, 112, 112] 256
ReLU-10 [-1, 128, 112, 112] 0
Conv2d-11 [-1, 128, 112, 112] 147,584
BatchNorm2d-12 [-1, 128, 112, 112] 256
ReLU-13 [-1, 128, 112, 112] 0
MaxPool2d-14 [-1, 128, 56, 56] 0
Conv2d-15 [-1, 256, 56, 56] 295,168
BatchNorm2d-16 [-1, 256, 56, 56] 512
ReLU-17 [-1, 256, 56, 56] 0
Conv2d-18 [-1, 256, 56, 56] 590,080
BatchNorm2d-19 [-1, 256, 56, 56] 512
ReLU-20 [-1, 256, 56, 56] 0
Conv2d-21 [-1, 256, 56, 56] 590,080
BatchNorm2d-22 [-1, 256, 56, 56] 512
ReLU-23 [-1, 256, 56, 56] 0
MaxPool2d-24 [-1, 256, 28, 28] 0
Conv2d-25 [-1, 512, 28, 28] 1,180,160
BatchNorm2d-26 [-1, 512, 28, 28] 1,024
ReLU-27 [-1, 512, 28, 28] 0
Conv2d-28 [-1, 512, 28, 28] 2,359,808
BatchNorm2d-29 [-1, 512, 28, 28] 1,024
ReLU-30 [-1, 512, 28, 28] 0
Conv2d-31 [-1, 512, 28, 28] 2,359,808
BatchNorm2d-32 [-1, 512, 28, 28] 1,024
ReLU-33 [-1, 512, 28, 28] 0
MaxPool2d-34 [-1, 512, 14, 14] 0
Conv2d-35 [-1, 512, 14, 14] 2,359,808
BatchNorm2d-36 [-1, 512, 14, 14] 1,024
ReLU-37 [-1, 512, 14, 14] 0
Conv2d-38 [-1, 512, 14, 14] 2,359,808
BatchNorm2d-39 [-1, 512, 14, 14] 1,024
ReLU-40 [-1, 512, 14, 14] 0
Conv2d-41 [-1, 512, 14, 14] 2,359,808
BatchNorm2d-42 [-1, 512, 14, 14] 1,024
ReLU-43 [-1, 512, 14, 14] 0
MaxPool2d-44 [-1, 512, 7, 7] 0
Linear-45 [-1, 4096] 102,764,544
ReLU-46 [-1, 4096] 0
Dropout-47 [-1, 4096] 0
Linear-48 [-1, 4096] 16,781,312
ReLU-49 [-1, 4096] 0
Dropout-50 [-1, 4096] 0
Linear-51 [-1, 500] 2,048,500
================================================================
Total params: 136,316,340
Trainable params: 136,316,340
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.19
Forward/backward pass size (MB): 321.95
Params size (MB): 520.01
Estimated Total Size (MB): 842.14
----------------------------------------------------------------
Process finished with exit code 0
说实话 ,参数量 缺时不少。总共842MB
训练图像时Basize 设置为10,我的GPU 8G内存不够用,汗颜。
我这里就暂时一下 得了。我暂时不用这个网络,对于多数据量的情况2G,上万张以上的样本,训练时间太长了。