使用pytorch搭建VGG网络
首先,引入CNN感受野
其次,VGG整体框架如下:
每层的卷积层stride=1,padding=1;池化层也一样的结构
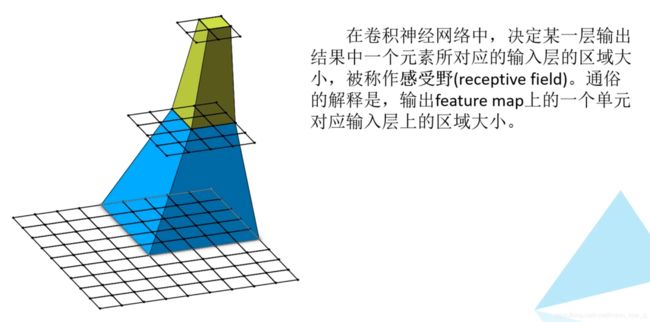
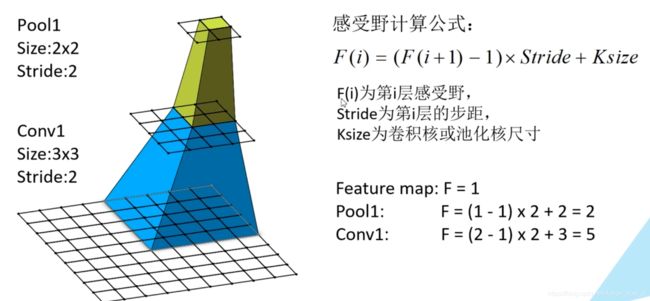
VGG论文要点:
- 仅使用3X3滤波器,这与之前的AlexNet的首层11X11滤波器、ZF Net的7X7滤波器都大不相同。作者所阐述的理由是,两个3X3的卷积层结合起来能够生成一个有效的5X5感知区。因此使用小尺寸滤波器既能保持与大尺寸相同的功能又保证了小尺寸的优势。优势其中之一就是参量的减少,另一个优势在于,针对两个卷积网络我们可以使用多一个线性整流层ReLU。
- 3个3X3卷积层并排起来相当于一个有效的7X7感知区。
- 输入图像的空间尺寸随着层数增加而减少(因为通过每层的卷积或是池化操作),其深度反而随着滤波器越来越多而增加。
- 一个有趣的现象是,每个最大池化层之后,滤波器数量都翻倍,这进一步说明了数据的空间尺寸减少但深度增加。
- 模型不仅对图像分类有效,同样能很好地应用在本地化任务中。作者在文章中进行了一系列的回归分析说明此事。
- 用Caffe工具箱进行建模
- 在训练中使用了尺寸抖动技术scale jittering进行数据扩容data augmentation
- 每卷积层后紧跟一个线性整流层ReLU并使用批量梯度下降法batch gradient descent进行训练
- 用4块Nvidia Titan Black GPU进行训练2~3周。
github代码 pytorch搭建经典网络模型
数据集 http://download.tensorflow.org/example_images/flower_photos.tgz
将数据集执行split_data.py脚本自动将数据集划分成训练集train和验证集val
|—— flower_data
|———— flower_photos(解压的数据集文件夹,3670个样本)
|———— train(生成的训练集,3306个样本)
|———— val(生成的验证集,364个样本)
1.model.py 创建网络架构
import torch.nn as nn
import torch
class VGG(nn.Module):
def __init__(self, features, num_classes=1000, init_weights=False):
super(VGG, self).__init__()
self.features = features
self.classifier = nn.Sequential(
nn.Dropout(p=0.5),
nn.Linear(512*7*7, 2048),
nn.ReLU(True),
nn.Dropout(p=0.5),
nn.Linear(2048, 2048),
nn.ReLU(True),
nn.Linear(2048, num_classes)
)
if init_weights:
self._initialize_weights()
def forward(self, x):
# N x 3 x 224 x 224
x = self.features(x)
# N x 512 x 7 x 7
x = torch.flatten(x, start_dim=1)
# N x 512*7*7
x = self.classifier(x)
return x
def _initialize_weights(self):
for m in self.modules(): # 遍历网络的每一个字模块
if isinstance(m, nn.Conv2d):
# nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
nn.init.xavier_uniform_(m.weight) # 初始化权重参数
if m.bias is not None: # 如果采用了偏置的话,置为0
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.xavier_uniform_(m.weight)
# nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)
def make_features(cfg: list): # 注意这里是 用一个函数把卷积层和池化层堆叠到layers中
layers = []
in_channels = 3
for v in cfg:
if v == "M":
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
else:
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)
layers += [conv2d, nn.ReLU(True)]
in_channels = v
return nn.Sequential(*layers)
cfgs = { # 论文中的A B D E
'vgg11': [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'vgg13': [64, 64, 'M', 128, 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'vgg16': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M'],
'vgg19': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256, 'M', 512, 512, 512, 512, 'M', 512, 512, 512, 512, 'M'],
}
def vgg(model_name="vgg16", **kwargs):
try:
cfg = cfgs[model_name]
except:
print("Warning: model number {} not in cfgs dict!".format(model_name))
exit(-1)
model = VGG(make_features(cfg), **kwargs)
return model
2.train.py 训练网络
import torch.nn as nn
from torchvision import transforms, datasets
import json
import os
import torch.optim as optim
from model import vgg
import torch
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(device)
data_transform = {
"train": transforms.Compose([transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]),
"val": transforms.Compose([transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])}
data_root = os.path.abspath(os.path.join(os.getcwd(), "../..")) # get data root path
image_path = data_root + "/data_set/flower_data/" # flower data set path
train_dataset = datasets.ImageFolder(root=image_path+"train",
transform=data_transform["train"])
train_num = len(train_dataset)
# {'daisy':0, 'dandelion':1, 'roses':2, 'sunflower':3, 'tulips':4}
flower_list = train_dataset.class_to_idx
cla_dict = dict((val, key) for key, val in flower_list.items())
# write dict into json file
# json.dumps()将字典形式的数据转化为字符串
# json.loads()用于将字符串形式的数据转化为字典
json_str = json.dumps(cla_dict, indent=4)
with open('class_indices.json', 'w') as json_file:
json_file.write(json_str)
batch_size = 32
train_loader = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size, shuffle=True,
num_workers=0)
validate_dataset = datasets.ImageFolder(root=image_path + "val",
transform=data_transform["val"])
val_num = len(validate_dataset)
validate_loader = torch.utils.data.DataLoader(validate_dataset,
batch_size=batch_size, shuffle=False,
num_workers=0)
# test_data_iter = iter(validate_loader)
# test_image, test_label = test_data_iter.next()
model_name = "vgg16"
net = vgg(model_name=model_name, num_classes=5, init_weights=True)
net.to(device)
loss_function = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=0.0001)
best_acc = 0.0
save_path = './{}Net.pth'.format(model_name)
for epoch in range(30):
# train
net.train()
running_loss = 0.0
for step, data in enumerate(train_loader, start=0):
images, labels = data
optimizer.zero_grad()
outputs = net(images.to(device))
loss = loss_function(outputs, labels.to(device))
loss.backward()
optimizer.step()
# print statistics
running_loss += loss.item()
# print train process
rate = (step + 1) / len(train_loader)
a = "*" * int(rate * 50)
b = "." * int((1 - rate) * 50)
print("\rtrain loss: {:^3.0f}%[{}->{}]{:.3f}".format(int(rate * 100), a, b, loss), end="")
print()
# validate
net.eval()
acc = 0.0 # accumulate accurate number / epoch
with torch.no_grad():
for val_data in validate_loader:
val_images, val_labels = val_data
optimizer.zero_grad()
outputs = net(val_images.to(device))
predict_y = torch.max(outputs, dim=1)[1]
acc += (predict_y == val_labels.to(device)).sum().item()
val_accurate = acc / val_num
if val_accurate > best_acc:
best_acc = val_accurate
torch.save(net.state_dict(), save_path)
print('[epoch %d] train_loss: %.3f test_accuracy: %.3f' %
(epoch + 1, running_loss / step, val_accurate))
print('Finished Training')
3.predict.py 预测
import torch
from model import vgg
from PIL import Image
from torchvision import transforms
import matplotlib.pyplot as plt
import json
data_transform = transforms.Compose(
[transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
# load image
img = Image.open("../tulip.jpg")
plt.imshow(img)
# [N, C, H, W]
img = data_transform(img)
# expand batch dimension
img = torch.unsqueeze(img, dim=0)
# read class_indict
try:
json_file = open('./class_indices.json', 'r')
class_indict = json.load(json_file)
except Exception as e:
print(e)
exit(-1)
# create model
model = vgg(model_name="vgg16", num_classes=5)
# load model weights
model_weight_path = "./vgg16Net.pth"
model.load_state_dict(torch.load(model_weight_path))
model.eval()
with torch.no_grad():
# predict class
output = torch.squeeze(model(img))
predict = torch.softmax(output, dim=0)
predict_cla = torch.argmax(predict).numpy()
print(class_indict[str(predict_cla)])
plt.show()
train loss: 100%[**************************************************->]1.102
[epoch 1] train_loss: 1.500 test_accuracy: 0.401
train loss: 100%[**************************************************->]1.125
[epoch 2] train_loss: 1.333 test_accuracy: 0.401
train loss: 100%[**************************************************->]1.289
[epoch 3] train_loss: 1.322 test_accuracy: 0.404
train loss: 100%[**************************************************->]1.273
[epoch 4] train_loss: 1.305 test_accuracy: 0.407
train loss: 100%[**************************************************->]1.540
[epoch 5] train_loss: 1.285 test_accuracy: 0.459
train loss: 100%[**************************************************->]1.181
[epoch 6] train_loss: 1.190 test_accuracy: 0.473
train loss: 100%[**************************************************->]0.895
[epoch 7] train_loss: 1.146 test_accuracy: 0.503
train loss: 100%[**************************************************->]1.354
[epoch 8] train_loss: 1.104 test_accuracy: 0.522
train loss: 100%[**************************************************->]1.542
[epoch 9] train_loss: 1.095 test_accuracy: 0.500
train loss: 100%[**************************************************->]0.818
[epoch 10] train_loss: 1.058 test_accuracy: 0.566
train loss: 100%[**************************************************->]0.641
[epoch 11] train_loss: 1.002 test_accuracy: 0.615
train loss: 100%[**************************************************->]0.612
[epoch 12] train_loss: 0.923 test_accuracy: 0.657
train loss: 100%[**************************************************->]0.489
[epoch 13] train_loss: 0.919 test_accuracy: 0.659
train loss: 100%[**************************************************->]0.302
[epoch 14] train_loss: 0.864 test_accuracy: 0.668
train loss: 100%[**************************************************->]0.596
[epoch 15] train_loss: 0.884 test_accuracy: 0.654
train loss: 100%[**************************************************->]0.780
[epoch 16] train_loss: 0.836 test_accuracy: 0.615
train loss: 100%[**************************************************->]0.979
[epoch 17] train_loss: 0.858 test_accuracy: 0.665
train loss: 100%[**************************************************->]1.077
[epoch 18] train_loss: 0.820 test_accuracy: 0.695
train loss: 100%[**************************************************->]1.745
[epoch 19] train_loss: 0.785 test_accuracy: 0.701
train loss: 100%[**************************************************->]0.329
[epoch 20] train_loss: 0.796 test_accuracy: 0.712
train loss: 100%[**************************************************->]1.188
[epoch 21] train_loss: 0.766 test_accuracy: 0.717
train loss: 100%[**************************************************->]0.541
[epoch 22] train_loss: 0.766 test_accuracy: 0.714
train loss: 100%[**************************************************->]0.743
[epoch 23] train_loss: 0.750 test_accuracy: 0.731
train loss: 100%[**************************************************->]0.696
[epoch 24] train_loss: 0.763 test_accuracy: 0.736
train loss: 100%[**************************************************->]0.657
[epoch 25] train_loss: 0.747 test_accuracy: 0.745
train loss: 100%[**************************************************->]0.358
[epoch 26] train_loss: 0.722 test_accuracy: 0.731
train loss: 100%[**************************************************->]0.653
[epoch 27] train_loss: 0.745 test_accuracy: 0.725
train loss: 100%[**************************************************->]0.487
[epoch 28] train_loss: 0.728 test_accuracy: 0.750
train loss: 100%[**************************************************->]1.140
[epoch 29] train_loss: 0.716 test_accuracy: 0.720
train loss: 100%[**************************************************->]1.415
[epoch 30] train_loss: 0.689 test_accuracy: 0.717
Finished TrainingProcess finished with exit code 0