《AdaFace: Quality Adaptive Margin for Face Recognition》用于人脸识别的图像质量自适应边缘损失
方法简介:
(1)介绍了损失函数中自适应性的另一个方面,即图像质量。
(2)强调误分类样本的策略应根据其图像质量进行调整。
(3)提出了一种新的损失函数,该函数根据图像质量强调不同困难的样本。
1、图像质量
图像质量是一组属性的组合,指示图像捕捉原始场景的真实程度。影响图像质量的因素包括亮度、对比度、锐度、噪声、颜色恒定性、分辨率、色调再现等。人脸图像是本文的重点,可以在各种照明、姿势和面部表情设置下拍摄,有时还可以在极端的视觉变化下拍摄。这些参数设置使得学习人脸识别模型的识别任务变得困难。尽管如此,这项任务是可以实现的,因为人类或模型通常可以在这些困难的环境下识别人脸。然而,当人脸图像质量较低时,有时识别任务变得不可行。
低质量图像正日益成为人脸识别数据集的重要组成部分,因为它们在监控视频和无人机镜头中遇到。鉴于SoTA FR方法能够在相对高质量的数据集中获得98%以上的验证精度,最近的FR挑战已转移到低质量的数据集。尽管挑战是在低质量数据集上实现高精度,但大多数流行的训练数据集仍然由高质量图像组成。由于只有一小部分训练数据质量较低,因此在训练期间适当利用它很重要。

主要工作:
(1)提出了一种损失函数AdaFace,该函数根据样本的图像质量对样本的不同困难赋予不同的重要性。通过结合图像质量,避免了强调无法识别的图像,而集中在难以识别的样本上。
(2)表明角度边界根据训练样本的难度来缩放学习梯度。这一观察促使自适应地改变边界函数,以在图像质量较高时强调硬样本,而如果图像质量低就会忽略难以识别的样本。
(3)证明了特征范数可以作为图像质量的表示。它不需要额外的模块来估计图像质量。因此,在不增加复杂性的情况下实现了自适应边界函数。
(4)通过对9个不同质量的数据集(LFW、CFP-FP、CPLFW、AgeDB、CALFW、IJB-B、IJB-C、IJB-S和TinyFace)进行广泛评估,验证了该方法的有效性。表明在保持高质量数据集性能的同时,可以极大地提高低质量数据集的识别性能。

2、相关工作
(1)基于边界的损失函数(SphereFace、CosFace、ArcFace)
提出初衷:将边界添加到softmax中是因为没有边距,学习的特征就没有足够的区分性。
形式:
:特征向量和第j个分类器权重向量之间的角度;
:地面真值(GT)标签的索引;
m:边距,标量超参数。
f:一个边界函数。
对于不同的边界函数,可以将f标记为:
这里s是一个用于缩放的超参数。
本文方法是将边界m建模为图像质量的函数,因为
对训练期间样本贡献更多梯度(即学习信号)有影响。
(2)自适应损失函数(Adaptive Loss Functions)
所用问题:硬样本挖掘、训练期间的调度困难、寻找最优超参数。
CurricularFace :将课程学习的理念引入进损失函数。在训练的初始阶段,
(负余弦相似性)的边界设置为较小值,以便可以学习简单样本。在训练时,边界逐渐增加,以便学习硬样本。
其中:
t是一个随着训练进度而增加的参数。
本文认为边界的自适应性应基于图像质量。我们认为,在高质量图像中,如果样本很难(相对于模型),网络应该学会利用图像中的信息;但在低质量图像中,如果样本很难,则更有可能缺乏适当的身份线索,网络不应该努力适应它。
3、AdaFace方法
样本
的交叉熵softmax损失可以标记为:
:
:最后一个全连接层权重矩阵的第j列;
:相应的偏置项;
C:类别的数量。
在测试期间,任意一对图像样本
和
,其余弦相似度度量为
,用于查找最接近的匹配身份。
为了使训练目标直接优化余弦距离,使用归一化softmax,其中偏置项设置为零,特征
在训练期间归一化并用s重新缩放。公式就变形为:
之间的角度;
然后引入边界m来减少类内差异,就变形为原始的边界损失函数。
(1)边界形式和梯度
目的:在反向传播过程中,由于边缘引起的梯度变化具有缩放样本相对于其他样本重要性的效果。
方法:角度边界可以在梯度方程中引入一个附加项,根据样本的难度来缩放信号。
假设
是样本
前两项
和
是标量。此外,这两项是唯一受参数m影响的项。作为方向项,
不含m,我们可以将前两个标量项视为梯度标度项(GST),并表示为:
为了进行GST分析,考虑类别指数
,因为所有负类
在等式中没有边界。
(1.1)归一化后的softmax的GST为:
此时
且
。
(1.2)CosFace的GST为:
此时
且
(1.3)ArcFace的GST为:
因为GST是
和m的函数,可以用它来控制在训练期间基于难度的样本重点。
GST可视化如下图所示:
(2)范数和图像质量
图像质量是一个综合术语,涵盖亮度、对比度和清晰度等特征。图像质量评估(IQA)在计算机视觉中得到广泛研究。SER-FIQ是一种用于人脸IQA的无监督蒸馏方法。BRISQUE是一种用于盲/无参考IQA的流行算法。然而,这种方法在训练期间使用的计算成本很高。本文避免引入计算图像质量的额外模块,使用特征范数作为图像质量的代理。我们观察到,在使用基于边缘的softmax损失训练的模型中,特征范数呈现出与图像质量相关的趋势。
下图中a部分展示了特征范数和用(1-BRISQUE)计算的图像质量(IQ)分数之间的相关图,图中的绿色曲线。本文还将概率输出
和IQ分数之间的相关图显示为橙色曲线。
b部分显示了特征范数和IQ分数之间的散点图,c部分显示了Pyi和IQ分数之间的散点图。
特征范数和IQ分数之间的高度相关性支持我们使用特征范数作为图像质量的代理。
特征范数的相关性始终高于
所以根据样本难度调整样本重要性时,考虑图像质量是有意义的。
(3)AdaFace:基于范数的自适应边界
目的:为了解决由无法识别的图像引起的问题,本文提出了基于特征范数的边界函数。
基础:a、不同的边界函数可以强调样本的不同困难;
b、特征范数是一种寻找低质量图像的好方法。
(3.1)图像质量指示器
作为特征范数,
是一个依赖于模型的量,使用
和
对其进行归一化,标记为:
:平均值;
:标准差;
:指将值剪裁在−1和1,并阻止梯度流动。
大约68%的单位高斯分布介于−1和1,所以我们引入h项来控制浓度,使得大多数的结果在-1到1之间。
如果批 尺寸太小,
和
作为
(3.2)自适应边界函数
a、如果图像质量高,我们强调硬样本;
b、如果图像质量较低,我们将不强调硬样本。
我们使用两个自适应项
和
来实现这一点,分别指角度边界和附加边界。具体来说,我们让:
其中
,
。
当
就变为ArcFace,为0就变为CosFace,为1就会变成随着偏移变为负角度边界。
高范数特征将在远离决策边界的地方获得更高的梯度尺度,而低范数特征将在靠近决策边界的地方获得更高的梯度尺度。
对于低范数特征,不强调远离边界的较硬样本,即图像质量较低的情况。
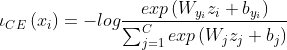




![\widehat{\left \| z_{i} \right \|}=\left [ \frac{\left \| z_{i} \right \|-\mu _{z}}{\frac{\sigma _{z}}{h}} \right ]_{-1}^{1}](http://img.e-com-net.com/image/info8/246650d97df44375aedc96155237dd4d.gif)
4、总结
本文解决了训练数据集中无法识别的人脸图像引起的问题。数据收集过程或数据增强在训练数据中引入这些图像。受基于图像质量的可识别性差异的影响,通过:
1)使用特征范数作为图像质量的代理;
2)基于特征范数自适应地改变边界函数来控制分配给不同质量图像的梯度尺度来解决该问题。
我们评估了所提出的自适应损失对不同质量数据集的有效性,并实现了混合和低质量人脸数据集的SoTA。
(1)局限性
解决了训练数据中存在无法识别的图像的问题。然而,噪声标签也是大规模人脸训练数据集的显著特征之一。我们的损失函数不会对标签错误的样本进行特殊处理。由于自适应损失非常重视高质量的困难样本,因此可能会错误地强调高质量的错误标记图像。相信未来的工作可以同时自适应地处理不可识别性和标签噪声。
(2)潜在的社会影响
计算机视觉界作为一个整体应努力将负面社会影响降至最低。我们的实验使用了训练数据集MS1MV*,它是MS Celeb的副产品,该数据集由其创建者提取。为了在公平的基础上将我们的结果与SoTA方法进行比较,我们需要使用MS1MV*。然而,我们认为社区应该转向新的数据集,因此我们纳入了新发布的WebFace4M的结果,以促进未来的研究。在科学界,收集人类数据需要IRB批准,以确保知情同意。虽然IRB状态通常不由数据集创建者提供,但由于收集过程的性质,假设大多数FR数据集(IJB-S除外)没有IRB。FR社区的一个方向是在知情同意的情况下收集大型数据集,在没有社会顾虑的情况下促进研发。