GhostNetV2学习笔记
GhostNetV2学习笔记
GhostNetV2: Enhance Cheap Operation with Long-Range Attention
Abstract
轻量级卷积神经网络(CNNs)是专为在移动设备上具有较快推理速度的应用而设计的。卷积运算只能捕获窗口区域的局部信息,这阻碍了性能的进一步提高。在卷积中引入自我注意可以很好地捕获全局信息,但会极大地影响卷积的实际速度。在本文中,我们提出了一种硬件友好的注意机制(称为DFC注意),然后提出了一种新的移动应用的GhostNetV2架构。所提出的DFC注意结构基于全连接层,既能在普通硬件上快速执行,又能捕获远距离像素间的依赖关系。我们进一步回顾了之前GhostNet的表达瓶颈,并提出在DFC的关注下,增强由廉价操作产生的扩展特性,使GhostNetV2块可以同时聚合本地和远程信息。大量的实验证明了GhostNetV2相对于现有体系结构的优越性。例如,它在ImageNet上以167M FLOPs达到75.3%的top-1精度,显著抑制了GhostNetV1(74.5%),但计算成本相似。源代码将在https://github.com/huawei-noah/Efficient-AI-Backbones/tree/master/ghostnetv2_pytorch和https://gitee.com/mindspore/models/tree/master/research/cv/ghostnetv2。
1 Introduction
在计算机视觉中,深度神经网络的架构在各种任务中发挥着至关重要的作用,如图像分类[19,10],目标检测[27,26],视频分析[18]。在过去的十年中,网络架构发展迅速,出现了包括AlexNet[19]、GoogleNet[29]、ResNet[10]和EfficientNet[32]在内的一系列里程碑。这些网络已经将一系列视觉任务的表现推向了一个高水平。
在智能手机和可穿戴设备等边缘设备上部署神经网络,不仅需要考虑模型的性能,还需要考虑其效率,特别是实际的推理速度。矩阵乘法占据了计算成本和参数的主要部分。开发轻量级模型是减少推理延迟的一种很有前途的方法。MobileNet[13]将标准卷积分解为深度卷积和点卷积,大大降低了计算成本。MobileNetV2[28]和MobileNetV3[12]进一步引入了反向残留块,改进了网络架构。ShuffleNet[42]利用shuffle操作来鼓励信道组之间的信息交换。GhostNet[8]提出了低成本的操作来减少信道中的特征冗余。WaveMLP[33]取代了复合体自注意模块和一个简单的多层感知器(MLP),以减少计算成本。这些轻量级的神经网络已经在许多移动应用中得到应用。
然而,基于卷积的轻量级模型在建模远程依赖性方面较弱,这限制了进一步的性能改进。近年来,计算机视觉引入了类似变压器的模型,其中的自注意模块可以捕获全局信息。典型的自我注意模块要求二次复杂度w.r.t。特征的形状和大小在计算上不友好。此外,计算注意地图需要大量的特征分割和重塑操作。尽管理论上它们的复杂性可以忽略不计,但实际上这些操作会占用更多的内存和更长的延迟。因此,在轻量级模型中使用香草式自我注意对移动部署并不友好。例如,在ARM设备[23]上,具有大量自注意操作的MobileViT比MobileNetV2慢7倍以上。
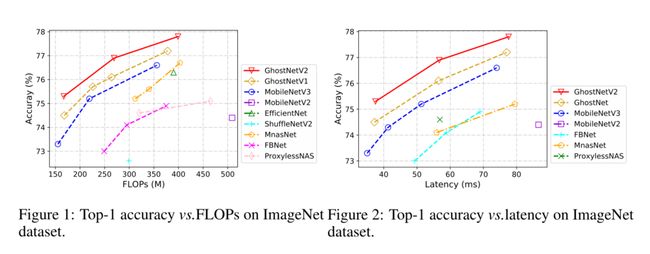
本文提出了一种新的注意机制(DFC注意),在保持轻量级卷积神经网络实现效率的前提下,捕获长距离的空间信息。为了简单起见,只有完全连接(FC)层参与生成注意地图。具体来说,将一个FC层分解为水平FC和垂直FC,聚合CNN二维特征图中的像素。两个FC层包括沿各自方向的较长范围内的像素,叠加它们将产生一个全局的接受场。此外,我们从最先进的GhostNet入手,重新审视了它的表示瓶颈,并利用DFC的关注增强了中间特征。然后,我们构建了一个新的轻型视觉中枢GhostNetV2。与现有的体系结构相比,它可以在准确性和推理速度之间实现更好的平衡(如图1和图2所示)。
2 Related Work
如何同时设计一种推理速度快、性能高的轻量级神经体系结构是一个挑战[16,41,13,40,35]。SqueezeNet[16]提出了三种策略来设计一个紧凑的模型,即将3×3过滤器替换为1×1过滤器,将输入通道的数量减少到3x3过滤器,在网络后期下采样以保持大的特征映射。这些原理是有建设性的,特别是1 × 1卷积的使用。MobileNetV1[13]用1 × 1核和深度可分离卷积代替了几乎所有的3 × 3文件,这极大地降低了计算成本。MobileNetV2[28]进一步将残差连接引入到轻量级模型中,构造了一个倒置残差结构,其中块的中间层比它的输入输出通道多。为了保持表达能力,去掉了一部分非线性函数。MobileNeXt[44]重新思考了反向瓶颈的必要性,并声称经典的瓶颈结构也可以实现高性能。考虑到1 × 1卷积占计算成本的很大一部分,ShuffleNet[42]将其替换为群卷积。信道洗牌操作,以帮助信息在不同组之间流动。通过研究影响实际运行速度的因素,ShuffleNet V2[22]提出了一种硬件友好的新块。通过利用特性的冗余,GhostNet[8]用廉价的操作取代了1 × 1卷积中的一半通道。到目前为止,GhostNet一直是SOTA轻量级模型,在准确性和速度之间有很好的权衡。
除了手工设计,还有一系列的方法试图寻找一个轻量级的建筑。例如,FBNet[39]设计了一种硬件感知的搜索策略,它可以直接在特定硬件上找到精度和速度之间的良好平衡。基于反向残差瓶颈,MnasNet[31]、MobileNetV3[12]搜索体系结构参数,如模型宽度、模型深度、卷积滤波器的大小等。虽然基于NAS的方法可以实现高性能,但它们的成功是基于精心设计的搜索空间和架构单元。自动搜索和手动设计可以结合起来找到更好的架构
3 Preliminary
3.1 A Brief Review of GhostNet
GhostNet[8]是SOTA轻量级模型,设计用于移动设备上的高效推理。它的主要组成部分是Ghost模块,它可以通过低成本的操作生成更多的特征映射来取代原来的卷积。给定输入特征 X ∈ R H × W × C X∈R^{H×W ×C} X∈RH×W×C,高度H,宽度W,通道数C,一个典型的Ghost模块可以用两步替换一个标准卷积。首先,利用1 × 1卷积生成本征特征,即:

其中,*表示卷积操作。 F 1 × 1 F_{1×1} F1×1为按点卷积, Y ′ ∈ R H × W × C o u t ′ Y^{'}∈R^{H×W ×C^{'}_{out}} Y′∈RH×W×Cout′为固有特征,其大小通常小于原始输出特征,即 C o u t ′ < C o u t C^{'}_{out} < C_{out} Cout′<Cout。然后使用廉价的操作(例如深度卷积)来生成基于内在特征的更多特征。特征的两部分沿信道维度连接,即
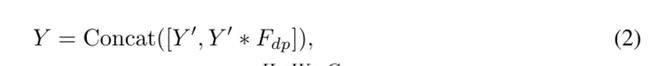
其中 F d p F_{dp} Fdp为深度卷积滤波器, Y ∈ R H × W × C o u t Y∈R^{H×W ×C_{out}} Y∈RH×W×Cout为输出特征。虽然Ghost模块可以显著降低计算成本,但不可避免地削弱了其表示能力**。空间像素之间的关系是实现精确识别的关键**。而在GhostNet中,对一半的特征只通过廉价的操作(通常通过3 × 3深度卷积实现)捕获空间信息。其余特征仅通过1 × 1点向卷积产生,不与其他像素相互作用。捕获空间信息的能力较弱可能会阻碍性能的进一步提高。
通过堆叠两个Ghost模块(如图4(A)所示)来构造一个GhostNet块。与MobileNetV2[28]类似,它也是一个反向瓶颈,即第一个Ghost模块作为扩展层,增加输出通道的数量,第二个Ghost模块减少通道的数量,以匹配快捷路径。
3.2 Revisit Attention for Mobile Architecture
基于注意的模型起源于NLP领域[36],近年来被引入计算机视觉领域[6,9,34,7]。例如,ViT[6]采用自注意模块和MLP模块堆叠的标准变压器模型。Wang等人在卷积神经网络中插入自注意操作来捕获非局域信息[37]。典型的注意模块通常具有二次复杂度w.r.t。该特征的大小,在下游任务如对象检测和语义分割中无法扩展到高分辨率图像。
降低注意复杂度的主流策略是将图像分割成多个窗口,并在窗口内或跨窗口执行注意操作。例如,Swin Transformer[21]将原始特征分割为多个不重叠的窗口,并在本地窗口内计算自注意。MobileViT[23]还将功能展开为不重叠的补丁,并计算这些补丁之间的注意力。对于CNN中的二维特征图,实现特征分割和注意计算涉及大量的张量重塑还有转置运算。其理论复杂性可以忽略不计。在一个高度复杂的大型模型(例如,具有数十亿FLOPs的swing - b[21])中,这些操作只占总推理时间的一小部分。而对于轻量级模型,其部署延迟不容忽视。
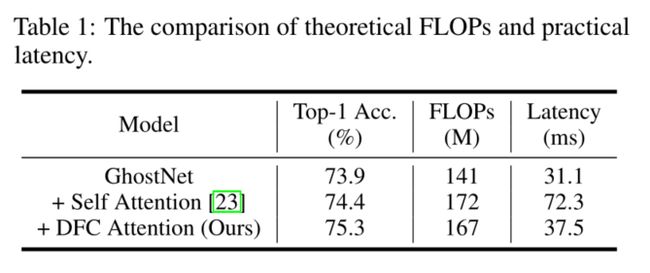
为了直观的理解,我们为GhostNet模型配备了MobileViT[23]中使用的self-attention,并使用TFLite工具在华为P30(麒麟980 CPU)上测量延迟。我们使用ImageNet的标准输入分辨率,即224 × 224,结果如表1所示。注意机制只增加约20%的理论FLOPs,但在移动设备上需要2倍的推理时间。理论复杂度和实际复杂度的巨大差异表明,为了在移动设备上快速实现,有必要设计一种硬件友好的注意机制。
4 Approach
4.1 DFC Attention for Mobile Architecture
在本节中,我们将讨论如何为移动cnn设计一个注意模块。期望的注意力应该具有以下特性:
Long-range
为了提高表示能力,捕获远程空间信息进行关注是至关重要的,轻量级CNN(如MobileNet [13], GhostNet[8])通常采用小的卷积滤波器(如1 × 1卷积)来节省计算成本。
Deployment-efficient
注意模块应该非常有效,以避免减慢推断。具有高flop或硬件不友好操作的昂贵转换是不可预期的。
Concept-simple
为了保持模型对不同任务的泛化性,注意模块应概念简单,设计不讲究。
尽管自我注意操作[6,24,21]可以很好地模拟远程依赖,但它们并不像上节所讨论的那样具有部署效率。与之相比,具有固定权重的全连接层(FC)更简单、更容易实现,也可用于生成具有全局接受域的注意映射。具体的计算过程如下所示。
给定一个特征 Z ∈ R H × W × C Z∈R^{H×W ×C} Z∈RH×W×C,可视为HW令牌 z i ∈ R C z_i∈R^C zi∈RC,即 Z = z 11 , z 12 , ⋅ ⋅ ⋅ , z H W Z = {z_{11}, z_{12},···,z_{HW}} Z=z11,z12,⋅⋅⋅,zHW。FC层生成注意地图的直接实现表述如下:
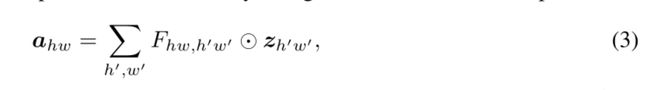
这里 ⊙ \odot ⊙为按元素乘法,F为FC层的可学习权值, A = a 11 , a 12 , ⋅ ⋅ ⋅ , a H W A = {a_{11}, a_{12},···,a_{HW}} A=a11,a12,⋅⋅⋅,aHW为生成的注意图。Eq 3可以通过将所有标记与可学习的权重聚合在一起来捕获全局信息,这也比典型的自我注意[36]简单得多。然而,它的计算过程仍然需要二次复杂度w.r t。特征的大小(即 O ( H 2 W 2 ) ) O(H^2 W^2)) O(H2W2)),这在实际情况下是不可接受的,特别是当输入图像是高分辨率时。例如,GhostNet的第4层有一个特征映使用3136 (56 × 56)个令牌,这导致计算注意地图非常复杂。实际上,CNN中的特征图通常是低秩的[30,17],没有必要将不同空间位置的所有输入输出令牌都紧密连接起来。特征的2D形状自然提供了一个减少FC层计算的视角,即,将Eq. 3分解为两个FC层,并分别沿水平和垂直方向聚合特征。它可以表述为:

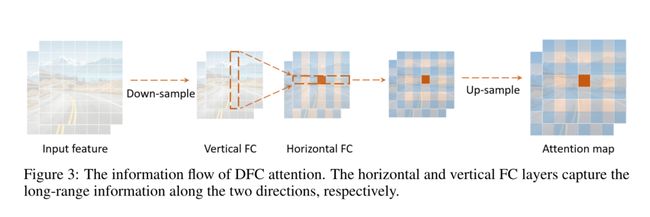
其中 F H F^H FH和 F W F^W FW是变换权值。以原始特征Z为输入,依次对特征应用Eq. 4和Eq. 5,分别捕获沿两个方向的长程相关性。我们将这种操作称为解耦全连接注意(DFC),其信息流如图3所示。由于水平和垂直变换的解耦,注意模块的计算复杂度可以降低到 O ( H 2 W + H W 2 ) O(H^2 W + H W^2) O(H2W+HW2)。在全注意(式3)中,正方形区域内的所有patch都直接参与到聚焦patch的计算中。在DFC注意中,一个补丁直接由垂直/水平线上的补丁聚合,而其他补丁则参与垂直/水平线上这些补丁的生成,与被聚焦的令牌有间接关系。因此,一个patch的计算也涉及到正方形区域内的所有patch。
等式4和5表示DFC注意的一般公式,它分别沿水平方向和垂直方向聚合像素。通过共享部分变换权值,可以方便地用卷积实现,省去了影响实际推理速度的耗时的张量重塑和转置操作。为了处理不同分辨率的输入图像,可以将滤波器的大小与特征图的大小解耦,即在输入特征上依次进行两个核大小为 1 × K H 1 × K_H 1×KH和 K W × 1 K_W × 1 KW×1的深度卷积。当采用卷积实现时,DFC注意的理论复杂度记为 O ( K H H W + K W H W ) O(K_H HW + K_W HW) O(KHHW+KWHW)。该策略得到了TFLite和ONNX等工具的良好支持,可在移动设备上进行快速推断。
4.2 GhosetNet V2
在本节中,我们使用DFC注意来提高轻量级模型的表示能力,然后提出新的视觉主干GhostNetV2。
Enhancing Ghost module
正如3.1中所讨论的,Ghost模块中只有一半的特征(等式1和2)与其他像素相互作用,这损害了它捕获空间信息的能力。因此,我们使用DFC注意增强Ghost模块的输出特征Y,以捕获不同空间像素之间的远程依赖性。
输入特征 X ∈ R H × W × C X∈R^{H×W ×C} X∈RH×W×C被发送到两个分支,一个是Ghost模块,产生输出特征Y(等式1和2),另一个是DFC模块,产生注意映射A(等式4和5)。回想一下,在典型的自注意[36]中,使用线性转换层将输入特征转换为查询和键,计算注意映射。同理,我们也实现1 × 1卷积,将模块的输入X转换为DFC的输入z。模块的最终输出 O ∈ R H × W × C O∈R^{H×W ×C} O∈RH×W×C是两个分支输出的乘积,即

这里的 ⊙ \odot ⊙为元素乘法,Sigmoid为标度函数,将注意映射A归一化到范围(0,1)。
信息聚合过程如图5所示。在相同的输入下,Ghost模块和DFC注意是两个平行的分支,从不同的角度提取信息。输出是它们的元素乘积,其中包含来自Ghost模块的特征和DFC注意模块的注意的信息。每个注意值的计算都涉及到大范围的补丁,因此输出特征可以包含来自这些补丁的信息。

Feature downsampling
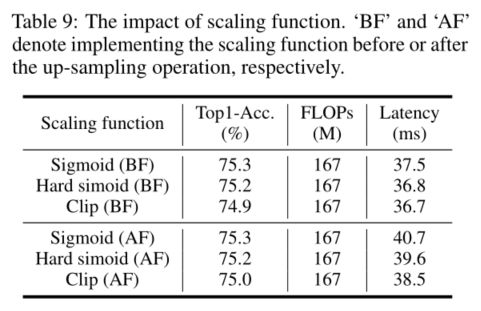
由于Ghost模块(等式1和2)是一种非常高效的操作,直接与DFC注意并行将引入额外的计算成本。因此,我们通过在水平和垂直方向上对特征进行下采样来减小特征的大小,这样DFC注意中的所有操作都可以在较小的特征上进行。默认情况下,宽度和高度都是原来长度的一半,这减少了75%的DFC注意FLOPs。然后将生成的特征图上采样到原始大小,以匹配Ghost分支中的特征大小。我们天真地使用平均池和双线性插值分别进行下采样和上采样。注意到直接实现sigmoid(或硬sigmoid)函数将导致较长的延迟,我们还将sigmoid函数部署在下采样的特征上,以加速实际推断。虽然注意地图的价值可能不是严格限制在(0,1)的范围内,但我们的经验发现,它对最终表现的影响是可以忽略不计的。

GhostV2 bottleneck
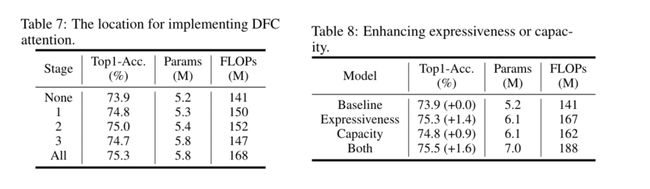
GhostNet采用了一个包含两个Ghost模块的反向残差瓶颈,其中第一个模块产生的扩展特征具有更多的通道,而第二个模块减少通道的数量得到输出特征。这个反向瓶颈自然地分离了模型[28]的“表达性”和“容量”。前者通过扩展特征度量,后者通过块的输入输出域反映。原始的Ghost模块通过廉价的操作生成了部分特征,这损害了表达能力和容量。通过研究在扩展特征或输出特征上配置DFC注意力的性能差异(第5.4节表8),我们发现增强“表现力”更有效。因此,我们只将扩展的特征与DFC注意相乘。
图4(b)显示了GhostV2瓶颈示意图**。DFC注意分支与第一个Ghost模块并行,以增强扩展功能**。然后将增强的特征发送到第二个Ghost模块产生输出特征。它捕获了不同空间位置像素之间的长程依赖性,增强了模型的表达能力。
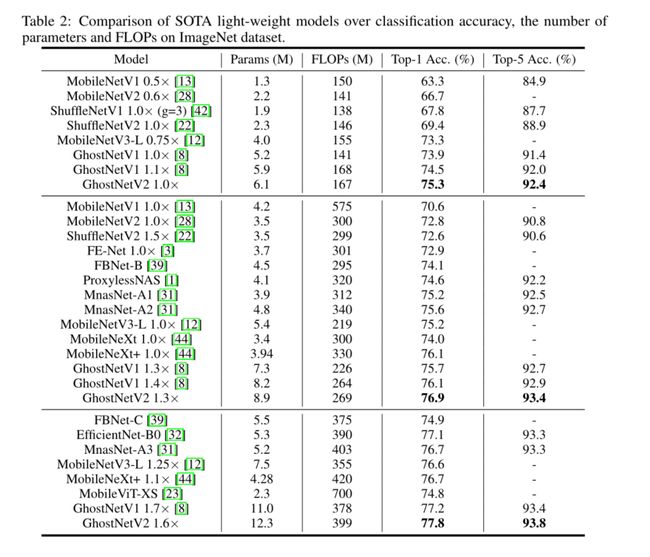
5 Experiments





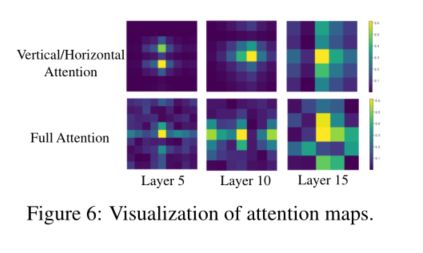
6 Conclusion
本文提出了一种硬件友好的DFC注意,并提出了一种新的移动应用的GhostNetV2体系结构。DFC注意可以捕捉到远距离空间位置上像素之间的依赖性,显著增强了轻量级模型的表达能力。它将一个FC层分解为水平FC和垂直FC,在两个方向上分别有较大的接受野。配备了这种计算高效和部署简单的模块,GhostNetV2可以在精度和速度之间实现更好的平衡。在基准数据集(如ImageNet、MS COCO)上的大量实验验证了GhostNetV2的优越性。