注意力机制 神经网络_GNN|三种注意力机制在图神经网络中的应用和总结
引言
在前两篇推文(图神经网络Graph Convolutional Network(GCN):从问题到理论分析; 论文详解|浅谈GraphSage之图学习中的Inductive learning 和 Transductive learning)中,我们讨论了基本的图神经网络算法GCN, 使用采样和聚合构建的inductive learning框架GraphSAGE, 然而图结构数据常常含有噪声,意味着节点与节点之间的边有时不是那么可靠,邻居的相对重要性也有差异,解决这个问题的方式是在图算法中引入“注意力”机制(attention mechanism), 通过计算当前节点与邻居的“注意力系数”(attention coefficient), 在聚合邻居embedding的时候进行加权,使得图神经网络能够更加关注重要的节点,以减少边噪声带来的影响。
图注意力机制的类型
目前主要有三种注意力机制算法,它们分别是:学习注意力权重(Learn attention weights),基于相似性的注意力(Similarity-based attention),注意力引导的随机游走(Attention-guided walk)。这三种注意力机制都可以用来生成邻居的相对重要性,下文会阐述他们之间的差异。
首先我们对“图注意力机制”做一个数学上的定义:
定义(图注意力机制):给定一个图中节点 和的邻居节点 (这里的 和GraphSAGE博文中的 表示一个意思)。注意力机制被定义为将中每个节点映射到相关性得分(relevance score)的函数,相关性得分表示该邻居节点的相对重要性。满足:
下面再来看看这三种不同的图注意力机制的具体细节
1 学习注意力权重
学习注意力权重的方法来自于Velickovic et al. 2018 其核心思想是利用参数矩阵学习节点和邻居之间的相对重要性。
给定节点相应的特征(embedding) ,节点和节点注意力权重可以通过以下公式计算:
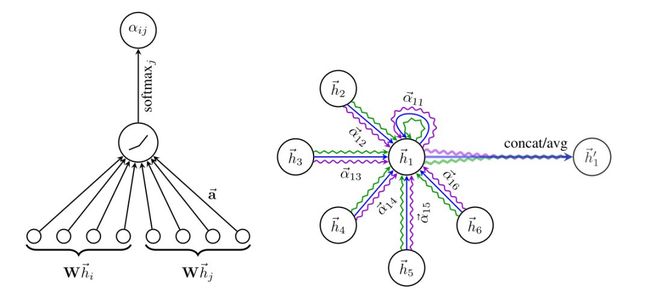
其中, 表示节点对节点的相对重要性。在实践中,可以利用节点的属性结合softmax函数来计算间的相关性。比如,GAT 中是这样计算的(公式可以左右滑动):
其中, 表示一个可训练的参数向量, 用来学习节点和邻居之间的相对重要性, 也是一个可训练的参数矩阵,用来对输入特征做线性变换,表示向量拼接(concate)。

如上图,对于一个目标对象, 表示它和邻居的相对重要性权重。可以根据 和 的 embedding 和 计算,比如图中 是由 共同计算得到的。
2 基于相似性的注意力
上面这种方法使用一个参数向量学习节点和邻居的相对重要性,其实另一个容易想到的点是:既然我们有节点的特征表示,假设和节点自身相像的邻居节点更加重要,那么可以通过直接计算之间相似性的方法得到节点的相对重要性。这种方法称为基于相似性的注意力机制,比如说论文 TheKumparampil et al. 2018 是这样计算的:
其中, 表示可训练偏差(bias),函数用来计算余弦相似度,和上一个方法类似, 是一个可训练的参数矩阵,用来对输入特征做线性变换。
这个方法和上一个方法的区别在于,这个方法显示地使用函数计算节点之间的相似性作为相对重要性权重,而上一个方法使用可学习的参数学习节点之间的相对重要性。
3 注意力引导的游走法
前两种注意力方法主要关注于选择相关的邻居信息,并将这些信息聚合到节点的embedding中。第三种注意力的方法的目的不同,我们以Lee et al. 2018 作为例子:
GAM方法在输入图进行一系列的随机游走,并且通过RNN对已访问节点进行编码,构建子图embedding。时间的RNN隐藏状态 编码了随机游走中 步访问到的节点。然后,注意力机制被定义为函数 ,用于将输入的隐向量映射到一个维向量中,可以通过比较这维向量每一维的数值确定下一步需要优先游走到哪种类型的节点(假设一共有种节点类型)。下图做了形象的阐述:
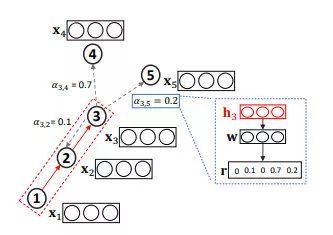
如上图,聚合了长度的随机游走得到的信息,我们将该信息输入到排序函数中,以确定各个邻居节点的重要性并用于影响下一步游走。
后话 至此,图注意力机制就讲完了,还有一些细节没有涉及,比如在 GAT论文 中讨论了对一个节点使用多个注意力机制(multi-head attention), 在AGNN论文中分析了注意力机制是否真的有效,详细的可以参考原论文。
Reference
- Attention Models in Graphs: A Survey
- Graph Attention Networks
- Attention-based Graph Neural Network for Semi-supervised Learning
- Graph Classification using Structural Attention
论文详解|浅谈GraphSage之图学习中的Inductive learning 和 Transductive learning
图神经网络Graph Convolutional Network(GCN):从问题到理论分析
 深度学习与PyTorch更多关于该话题的讨论可以加入微信讨论群,欢迎~
深度学习与PyTorch更多关于该话题的讨论可以加入微信讨论群,欢迎~
