python网络爬虫及数据可视化
广东某学校的期末python作业
一、设计内容及要求
设计内容:对中国大学专业排名网站中2021年,计算机科学与技术专业,进行数据爬取和数据可视化。
URL: https://www.shanghairanking.cn/rankings/bcmr/2021/080901
设计要求:
- 使用requests库中的get方法获取网页。
- 提取出该专业的前15所大学的数据(排名、学校名称、总分),并保存到数据库。
- 使用matplotlib库绘制柱状图,实现数据可视化。
二、相关代码
先获取网页上类似json数据的排名、学校名称、总分
def getHTMLText(url, headers):
try:
r = requests.get(url=url, headers=headers, timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
# soup = BeautifulSoup(r.text,"html.parser")
data_json = json.loads(r.text)
return data_json["data"]["rankings"]
except:
print("爬取失败")下方主函数就会把headers,url;headers里的地址根据你使用的浏览器的地址是不同的,具体如何找到对应地址如下:
headers = {
"User-Agent": "Mozilla/5.0 (iPhone; CPU iPhone OS 13_2_3 like Mac OS X) AppleWebKit/605.1.15 "
"(KHTML, like Gecko) Version/13.0.3 Mobile/15E148 Safari/604.1"
}
url = "https://www.shanghairanking.cn/api/pub/v1/bcmr/rank?year=2021&majorCode=080901"打开网页后,按住F12,然后点击步骤1刷新界面,然后点击步骤2XHR,点击左边Name下方第一行,然后可以看到步骤3的URL和步骤4的user-agent了。
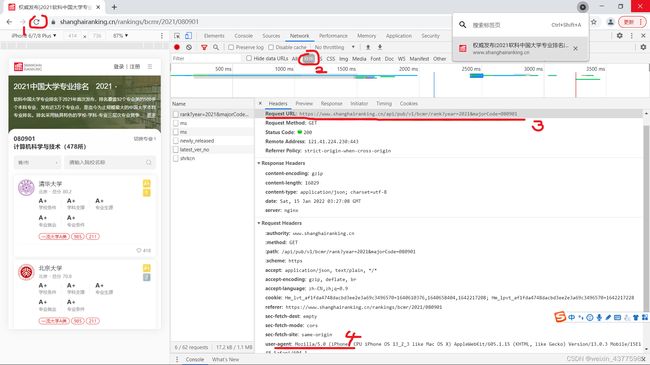
获取json文件的排名、大学、总分
def get_data(jdata):
rank = pd.DataFrame([i["ranking"] for i in jdata])
school = pd.DataFrame([i["univNameCn"] for i in jdata])
score = pd.DataFrame([i["score"] for i in jdata])
df = pd.concat([rank, school, score], axis=1,) # 按照行索引进行
df.columns = ["排名", "学校名称", "总分"]
return df打印爬取数据
def printRank(uinfo,num):
tplt = "{0:^10}\t{1:^10}\t{2:^10}\t"# {1:^10} 1表示位置,^表示居中,10表示占10个位置
print(tplt.format("排名", "学校名称", "总分"))
for i in range(num):
u = uinfo.loc[i]
print(tplt.format(u[0], u[1], u[2]))写入数据库,数据库自行设置
def writeDB(uinfo,num):
"""写入MySQL数据库"""
# host,user,password,database
db = pymysql.connect(host="localhost", user="root",password="123456",database="library",charset="utf8")
cur = db.cursor() #开启游标功能,创建游标对象
try:
tplt = "{0:^10}\t{1:^10}\t{2:^10}\t"
for i in range(num):
u = uinfo.loc[i]
sql = "INSERT INTO `school1` (rank,schoolname,score) VALUES (%s,'%s',%f)" \
% (str(u[0]), str(u[1]), float(u[2]))
cur.execute(sql)
db.commit()
except:
db.rollback() # 若发生错误则回滚
cur.close()
db.close()
print("数据库写入成功!")数据可视化
def shujukeshihua():
db = pymysql.connect(host="localhost", user="root", password="123456", database="library", charset="utf8")
cur = db.cursor()
sqls = 'select schoolname,score from school1 ' # 创建sql指令
cur.execute(sqls) # 执行sql指令
rows = cur.fetchall()
print(rows)
x=[]
y=[]
for r in rows:
x.append(r[0])
y.append(r[1])
plt.bar(x, y, width=0.5, align="center", label="得分", color="blue")
plt.title("全国前15大学专业分数情况")
for a, b in zip(x, y):
plt.text(a, b, b, ha='center', va="bottom", fontsize=10)
plt.xlabel('大学名称')
plt.ylabel('得分')
plt.legend()
plt.show()
cur.close()
# 关闭数据库连接+
db.close()
print("数据可视化成功!")主函数
if __name__ == "__main__":
# info = []
headers = {
"User-Agent": "Mozilla/5.0 (iPhone; CPU iPhone OS 13_2_3 like Mac OS X) AppleWebKit/605.1.15 "
"(KHTML, like Gecko) Version/13.0.3 Mobile/15E148 Safari/604.1"
}
url = "https://www.shanghairanking.cn/api/pub/v1/bcmr/rank?year=2021&majorCode=080901"
html = getHTMLText(url,headers)
info = get_data(html)
# printRank(info,15) # 注释的内容可根据不同的函数进行调用,也可自行做个switch循环,python没有自带这个循环,需要自行编写
# writeDB(info,15)
# deldteDB(info,15)
# shujukeshihua()三、相关截图
网页爬取的数据
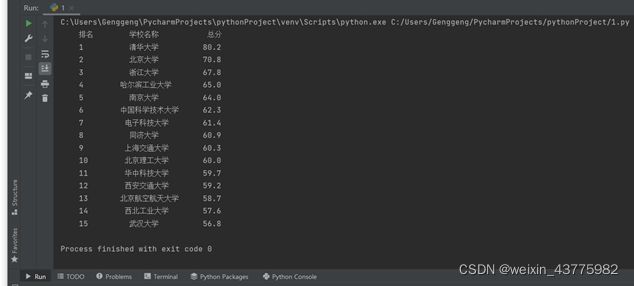
数据库写入的数据

数据可视化功能
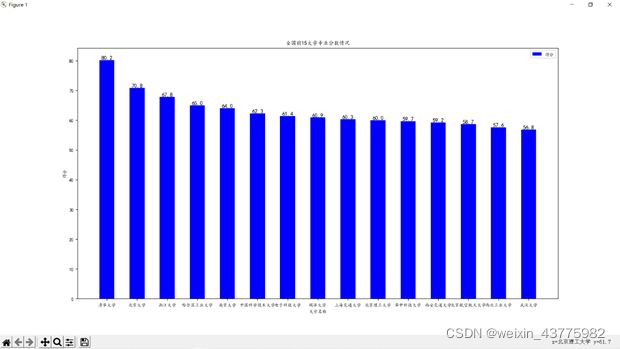
补充一下放在最前面的import
import requests
import json
import pandas as pd
import pymysql
import numpy as np
import matplotlib.pyplot as plt
from pylab import mpl
mpl.rcParams['font.sans-serif'] = ['KaiTi']
mpl.rcParams['font.size'] = 8