Python速学习成三节体验课(马士兵)
Python速学习成三节体验课(马士兵)
(Python我也是刚学的小白,写博客当做是自己做笔记了,也是第一次写,写的不好请多担待)
第一节:爬虫小白的进阶之路
任务:爬取一页JD平台销量第一的手机评论数据
初识爬虫
-什么是爬虫?
-爬取网络数据的虫子(Python程序)
-爬虫实质是什么呢?
-模拟浏览器的工作原理,向服务器请求相应的数据浏览器的工作原理
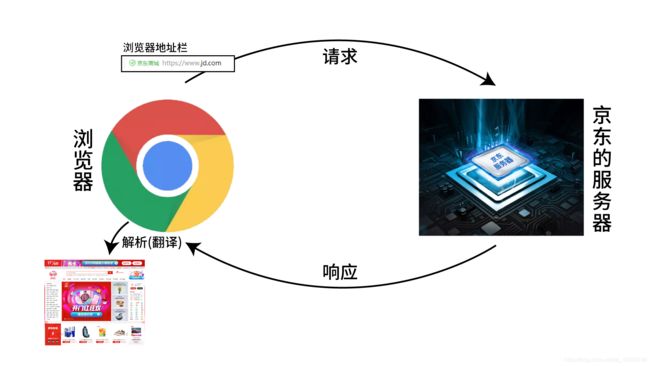
爬虫的工作原理如下图:
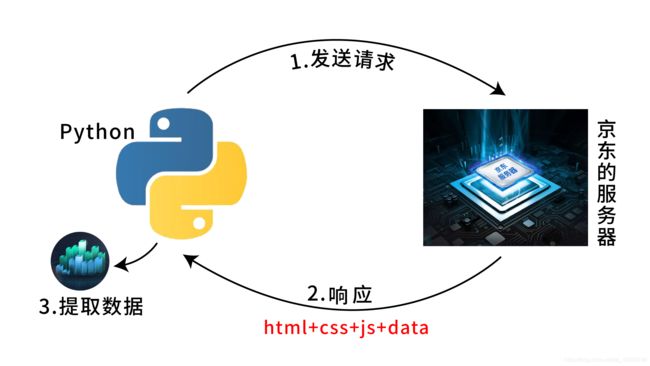
数据背后的秘密
-找不到这部手机的销售数据怎么办?
-曲线救国,通过评论数据间接得到鞋子的销售数据
-如何找到评论区内容背后的URL?
(1)鼠标右击选择检查,打开程序员调试窗口,点击network(网络)
(2)刷新当前页面
(3)复制一小段评论区内容,然后在程序员调试窗口点击放大镜,粘贴
(4)点击刷新小圆圈查找
(5)点击查询结果的第二行,跳转到对应的请求
(6)点击Headers,找到Request URL即几评论区数据背后的URL
(URL = https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98&productId=100004770263&score=0&sortType=5&page=0&pageSize=10&isShadowSku=0&fold=1)
3行代码爬取JD数据
梳理代码流程:
(1)引入Python工具包requests
(2)使用工具包中的get方法,向服务器发起请求
(3)打印输出请求回来的数据(print语法)
《代码展示》
# 1.引入工具包
import requests
# 2.使用get方法请求,并赋值给resp
resp = requests.get('https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98&productId=100004770263&score=0&sortType=5&page=0&pageSize=10&isShadowSku=0&fold=1')
# 3.打印文本数据
print(resp.text)
《部分结果展示》
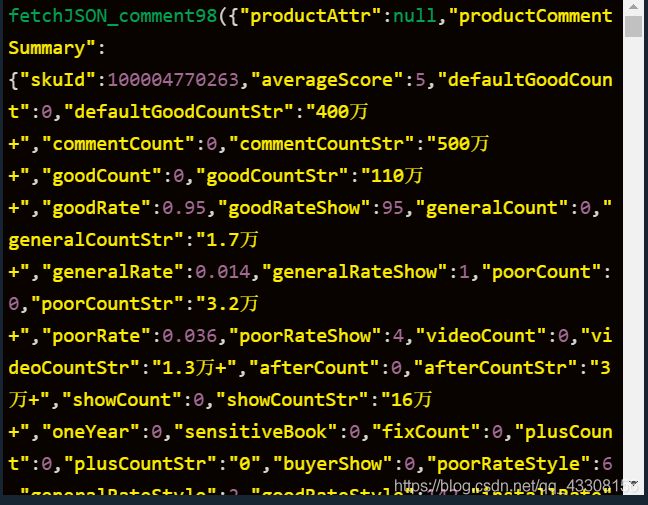

牛刀小试1
-爬取一页JD平台上销量最高的口红评论区数据
-----First class is over.------
第二节课:Python高手过招
利用for循环写一段代码,爬取评论中手机的颜色与内存大小
Python代码解析数据
-如何解析这堆杂乱无章的数据?
(1)打开网页工具 www.json.cn
(2)将数据整理成Json格式:**以大括号开头和结尾**
(3)找到目标数据值对应的名字Python replace语法
replace为替换的意思,可以使用replace把任何不想要的数据替换成一个新值
引入Python整理数据的工具包 json、获取手机颜色及鞋码数据
利用Json工具所获结果如下图所示

《代码展示》
import requests
import json
resp = requests.get('https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98&productId=100004770263&score=0&sortType=5&page=0&pageSize=10&isShadowSku=0&fold=1')
content = resp.text
rest = content.replace('fetchJSON_comment98(','').replace(');','') # json工具仅对“{}”内的数据有效,故删除大括号前后的数据
json_data = json.loads(rest)
comments = json_data['comments']
for item in comments:
color = item['productColor']
size = item['productSize']
print(color)
print(size)
《结果如下图所示》
白色
128GB
紫色
128GB
紫色
128GB
白色
128GB
黑色
128GB
紫色
128GB
紫色
128GB
绿色
64GB
黑色
128GB
黑色
64GB
牛刀小试2
利用for循环写一段代码,爬取评论中口红的色号数据
第三节课:化身数据分析师
四行代码带数据回家
-学会引用openpyxl工具包存储数据
(1)创建一个Excel表格
(2)创建一个sheet
(3)在sheet里面保存数据
(4)把表格保存在一个磁盘里
《代码展示》
import requests
import json
import openpyxl
wk = openpyxl.workbook()
sheet = wk.create_sheet()
resp = requests.get('https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98&productId=100004770263&score=0&sortType=5&page=0&pageSize=10&isShadowSku=0&fold=1')
content = resp.text
rest = content.replace('fetchJSON_comment98(','').replace(');','') # json工具仅对“{}”内的数据有效,故删除大括号前后的数据
json_data = json.loads(rest)
comments = json_data['comments']
for item in comments:
color = item['productColor']
size = item['productSize']
sheet.append([color,size])
wk.save('data/杜小帅-17331716899.xlsx')
编写不够完整,只用于自己的笔记参考。