python数据挖掘之K-Means 二分K-means K-means++ 以及DBSCAN算法的实战应用(超详细必看)
需要完整代码和数据集请点赞关注收藏后评论区留言
二分K-means以及K-means++是K-means的两种变体,可以解决K-means算法质心敏感,过拟合等等问题
运行环境是anaconda+pytorch
项目结构如下
scutVec.npy中存放数据集
main函数中你可以用不同的方法去跑不同的数据集来观察他们之间的区别
其他几个python文件的代码请点赞关注收藏请评论区留言
main函数代码如下
import numpy as np
from sklearn.preprocessing import StandardScaler, MinMaxScaler
import matplotlib.pyplot as plt
import sklearn.datasets as datasets
import DBSCAN
import KMeansRelevant
def show_cluster_result(cluster, normal_data, cluster_method):
# 第一幅图展示原始图
plt.figure(figsize=(24, 10), dpi=80)
plt.subplot(1, 2, 1)
plt.scatter(normal_data[:, 0], normal_data[:, 1], color='black')
plt.title('raw graph')
# 第二幅图聚类结果
plt.subplot(1, 2, 2)
plt.scatter(normal_data[:, 0], normal_data[:, 1], c=cluster, marker='o')
plt.title(cluster_method)
plt.legend(labels=['x', 'y'])
plt.show()
def show_K_dis(data, K):
distance = DBSCAN.k_nearest_neighbour_distance(dataSet, K)
x = [i for i in range(distance.shape[0])]
plt.scatter(x, distance)
plt.title("Points Sorted by Distance to %ith Nearest Neighbor" % K)
plt.legend()
plt.show()
scutJPG = np.load("scutVec.npy") # 窝工校徽
n_samples = 2500
noisy_circles, _ = datasets.make_circles(n_samples=n_samples, factor=0.5, noise=0.05,random_state=8)
noisy_moons, _ = datasets.make_moons(n_samples=n_samples, noise=0.05,random_state=8)
blobs, _ = datasets.make_blobs(n_samples=n_samples, random_state=8)
# 1,选择不同的数据集
dataSet = scutJPG # ['noisy_circles', 'noisy_moons', 'blobs', 'scutJPG']
# 2, 对数据进行处理
scaler = StandardScaler()
normal_data = scaler.fit_transform(dataSet)
# 3, 选择并运行聚类算法
cluster_method = "kMeans" # ['kMeans', 'biKMeans', 'kMeans++', 'DBSCAN']
if cluster_method == "DBSCAN":
# DBSCAN的参数设置与运行, 请根据K-dis图像来获得大致的eps值
min_pts = 8
# 查看k-dist
show_K_dis(normal_data, min_pts)
eps = 0.08 # 0.09
cluster = DBSCAN.dbscan(normal_data, eps, min_pts)
elif cluster_method == "biKMeans": # 运行二分K-means算法,请指定k值
cluster = KMeansRelevant.biKMeans(normal_data, 10)
elif cluster_method == "kMeans++": # 运行K-means++算法,请指定k值
cluster = KMeansRelevant.kMeansPP(normal_data, 10)
else: # 默认其他跑KMeans
cluster = KMeansRelevant.origin_kMeans(normal_data, 10)
# 4, 输出聚类结果
num = cluster.max(0)
print("cluster num is:", num + 1)
show_cluster_result(cluster, normal_data, cluster_method)
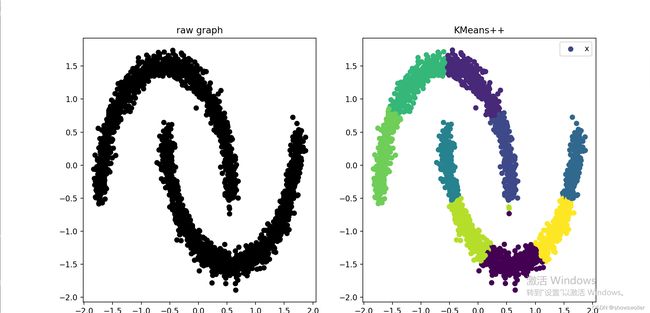
运行结果如下
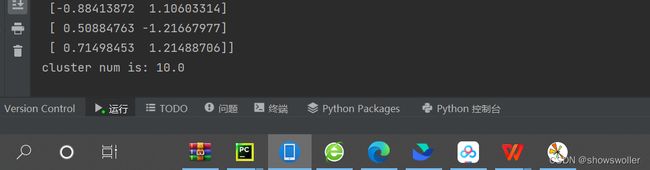
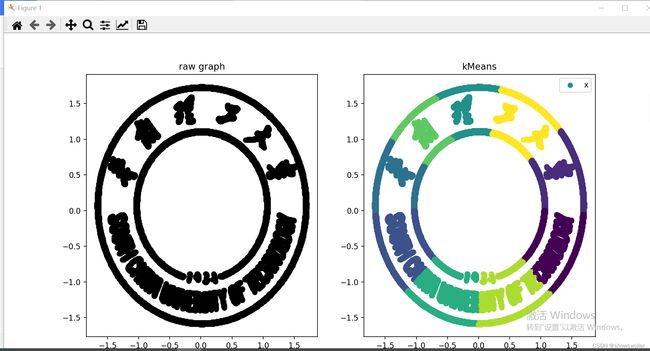
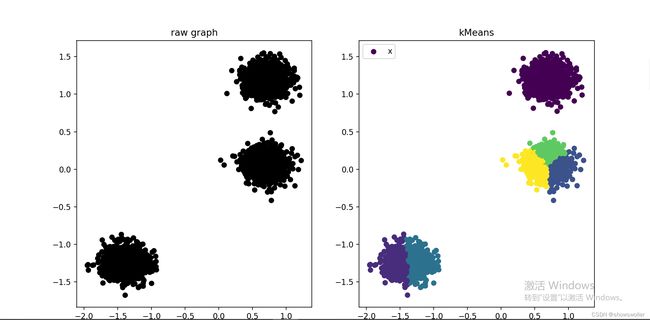
结果可视化如下

需要完整代码和数据集请点赞关注收藏后评论区留言