模型越复杂越容易惰性
Hey, hope you are having a wonderful day!
嘿,希望您今天过得愉快!
Whenever I work on a new ML project. These lines always pop up in my mind every time
每当我从事新的ML项目时。 这些线每次都会在我的脑海中弹出
“I need to fit the data for every model then apply metrics to check which model has better accuracy for the available dataset ,then choose best model and also this process is time-consuming and even it might not be that much effective too“
“我需要为每个模型拟合数据,然后应用度量标准来检查哪个模型对可用数据集具有更好的准确性,然后选择最佳模型,而且此过程非常耗时,甚至可能效果也不那么好”
For this problem, I got a simple solution when surfing through python org, which is a small python library by name “lazypredict” and it does wonders
对于这个问题,我在通过python org进行浏览时得到了一个简单的解决方案,这是一个名为“ lazypredict”的小型python库,它的确令人惊讶
Let me tell you how it works:-
让我告诉你它是如何工作的:
安装库 (Install the library)
pip install lazypredict注意 (Note)
- lazypredict only works for python version≥3.6 lazypredict仅适用于Python版本≥3.6
- It's built on top of various other libraries so if you don't have those libraries in the system, python will throw ModuleError so interpret the error properly and install the required libraries. 它建立在其他各种库的基础上,因此,如果系统中没有这些库,则python会抛出ModuleError,从而正确解释错误并安装所需的库。
lazypredict comes only for supervised learning (Classification and Regression)
lazypredict仅用于监督学习(分类和回归)
I will be using jupyter notebook in this article
我将在本文中使用Jupyter Notebook
码 (Code)
# import necessary modules
import warnings
warnings.filterwarnings('ignore')
import time
from sklearn.datasets import load_iris,fetch_california_housing
from sklearn.model_selection import train_test_split
from lazypredict.Supervised import LazyClassifier,LazyRegressor- warnings: Package to handle warnings and ‘ignore’ is used when we need to filter out all the warnings 警告:处理警告和“忽略”的包在我们需要过滤掉所有警告时使用
- time: Package to handle time manipulation time:处理时间的软件包
- sklearn.datasets: Package to load datasets, today we gonna use the classic datasets which everyone works on it that are load_iris() for classification problem and fetch_california_housing() for a regression problem sklearn.datasets:打包以加载数据集,今天我们将使用每个人都可以处理的经典数据集,其中load_iris()用于分类问题,而fetch_california_housing()用于回归问题。
- sklearn.model_selection.train_test_split:Used to split the dataset into train and split sklearn.model_selection.train_test_split:用于将数据集拆分为训练并拆分
- lazypredict:this is the package we gonna learn today in lazypredict.Supervised there are two main functions LazyClassifier for Classification and LazyRegressor for Regression lazypredict:这是我们今天将要在lazypredict中学习的软件包。在监督下,有两个主要功能用于分类的LazyClassifier和用于回归的LazyRegressor
惰性分类器 (LazyClassifier)
# load the iris dataset
data=load_iris()
X=data.data
Y=data.target- The data is a variable with dictionary data type where there are two keys the data which contains independent features/column values and target which contains dependent feature value 数据是具有字典数据类型的变量,其中有两个键,数据包含独立的要素/列值,目标包含相关的要素值
- X has all the independent features values X具有所有独立特征值
- Y has all the dependent features values Y具有所有从属特征值
# split the dataset
X_train, X_test, Y_train, Y_test =train_test_split(X,Y,test_size=.3,random_state =23)
classi=LazyClassifier(verbose=0,predictions=True)- We will split the data into train and test using train_test_split() 我们将数据分为train和使用train_test_split()进行测试
- The test size will be 0.3(30%) of the dataset 测试大小将为数据集的0.3(30%)
- random_state will decide the splitting of data into train and test indices just choose any number you like! random_state将决定将数据拆分为训练索引和测试索引,只需选择您喜欢的任何数字即可!
Tip 1:If you want to see source code behind any function or object in the jupyter notebook then just add ? or ?? after the object or the function you want to check out and excute it
提示1:如果要查看jupyter笔记本中任何函数或对象背后的源代码,则只需添加? 要么 ?? 在要检出并执行的对象或功能之后
- Next, we will call LazyClassifier() and initialize to classic with two parameters verbose and prediction 接下来,我们将调用LazyClassifier()并使用详细信息和预测两个参数将其初始化为经典
- verbose: int data type, if non zero, progress messages are printed. Above 50, the output is sent to stdout. The frequency of the messages increases with the verbosity level. If it more than 10, all iterations are reported. I would suggest you try different values based on your depth of analysis 详细:int数据类型,如果非零,则显示进度消息。 高于50时,输出将发送到stdout。 消息的频率随着详细程度而增加。 如果大于10,则报告所有迭代。 我建议您根据您的分析深度尝试其他值
- predictions: boolean data type if it is set to True then it will return all the predicted values from the models 预测:布尔数据类型,如果将其设置为True,则它将返回模型中的所有预测值
# fit and train the model
start_time_1=time.time()
models_c,predictions_c=classi.fit(X_train, X_test, Y_train, Y_test)
end_time_1=time.time()- we gonna fit train and test data to the classi object 我们将训练和测试数据拟合到classi对象
- classic will return two values: 经典版将返回两个值:
- models_c: will have all the models and with some metrics models_c:将具有所有模型并具有一些指标
predictions_c: will have all the predicted values that is ŷ
projections_c :将具有所有预测值ŷ
# to check which model did better on the iris dataset
models_c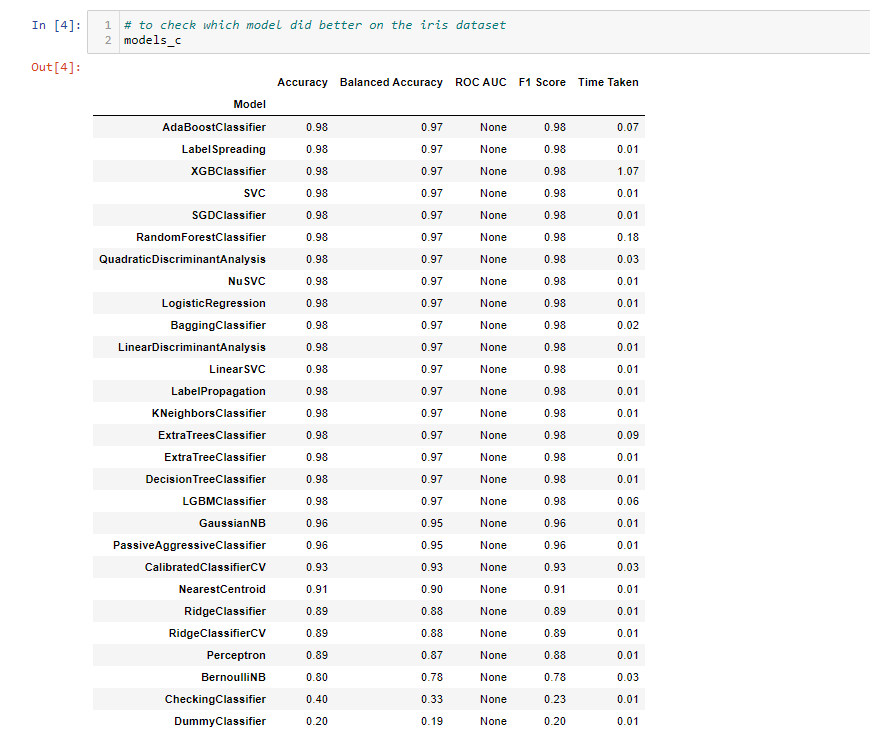
- To be honest I didn't know some of these models even exist for classification until I saw this 老实说,我不知道其中一些模型可以分类,直到我看到了
- I know that your mind would be thinking why is ROC AUC is None is this function not giving proper output nope that's not the case here, ROC AUC is None because we have taken multi-classification dataset 我知道您的大脑会在思考为什么ROC AUC为None是该函数没有提供适当的输出空间吗,这里不是这种情况,ROC AUC为None是因为我们采用了多分类数据集
Tip 2: For the above dataset or multi-classification we can use roc_auc_score rather than ROC AUC
提示2:对于上述数据集或多分类,我们可以使用roc_auc_score而不是ROC AUC
# to check the predications for the models
predictions_c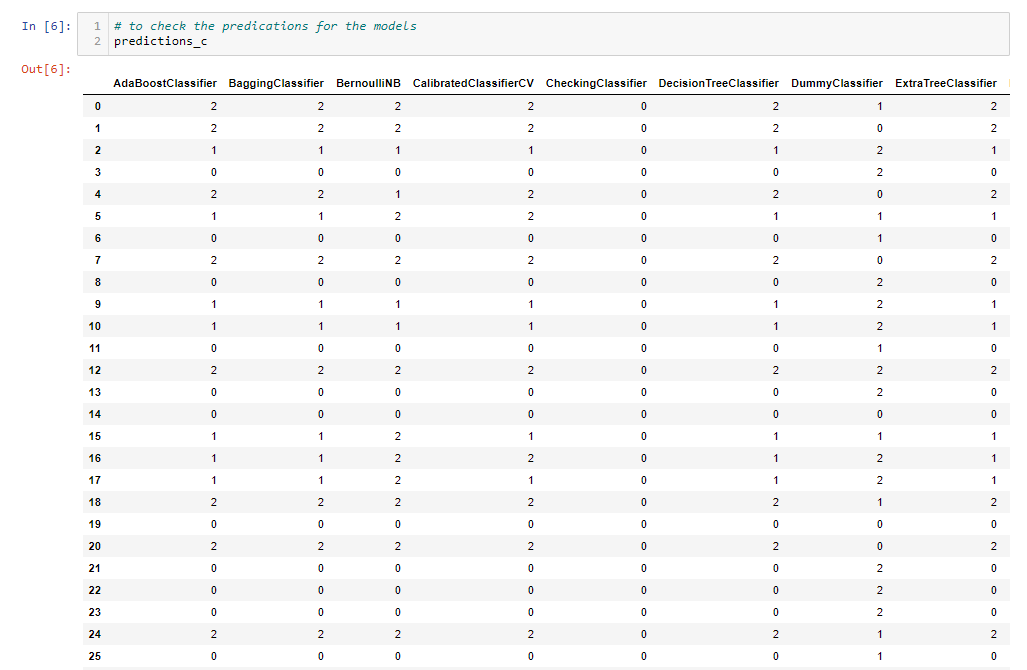
- This is just a few sample predictions from the models 这只是来自模型的一些样本预测
惰性回归器 (LazyRegressor)
- So we checked out LazyClassifier it will be sad if we didn't pay some attention to LazyRegressor 因此,我们检查了LazyClassifier,如果我们不注意LazyRegressor将会很可惜
- The following code is similar to LazyClassifier so let's pick up the phase and skip some explanations 以下代码与LazyClassifier相似,因此让我们开始阶段并跳过一些解释。
# load the fetch_california_housing dataset
data1=fetch_california_housing()
X1=data1.data
Y1=data1.target- data1 is dict data type with data and target as keys data1是dict数据类型,数据和目标为键
# split the dataset
X_train1, X_test1, Y_train1, Y_test1 =train_test_split(X1,Y1,test_size=.3,random_state =23)
regr=LazyRegressor(verbose=0,predictions=True)- after fitting the model next we will train 拟合模型之后,我们将进行训练
# fit and train the model
start_time_2=time.time()
models_r,predictions_r=regr.fit(X_train1, X_test1, Y_train1, Y_test1)
end_time_2=time.time()注意 (Note)
1. Before running the above cell make sure you clear all the unnecessary background process because it takes a lot of computation power
1.在运行上面的单元格之前,请确保清除所有不必要的后台进程,因为这需要大量的计算能力
2. I would suggest if you have low computation power(RAM, GPU) then use Google Colab, This is the simplest solution you can get
2.我建议如果您的计算能力(RAM,GPU)低,那么请使用Google Colab,这是您可以获得的最简单的解决方案
# to check which model did better on the fetch_california_housing dataset
models_r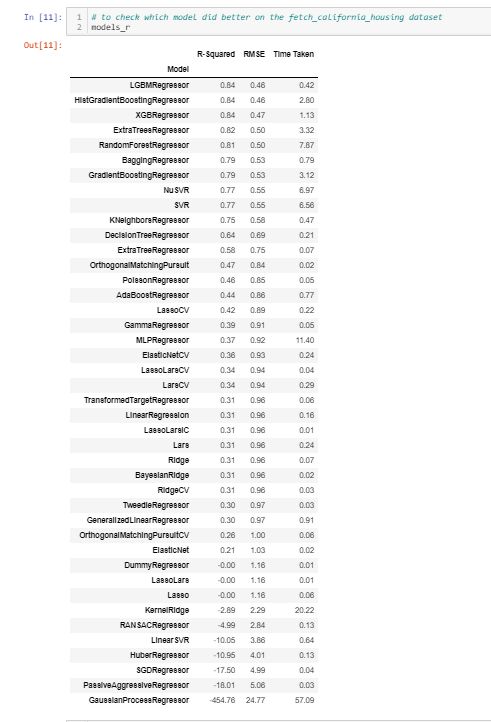
- And again I didn't know there were so many models for regression 再一次,我不知道有这么多回归模型
# to check the predications for the models
predictions_r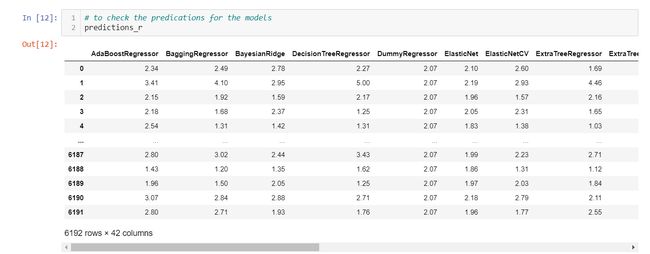
时间复杂度 (Time Complexity)
- We should talk about time complexity because that's the main goal for all us to reduce it as much as possible 我们应该谈论时间复杂性,因为这是我们所有人尽可能降低时间的主要目标
# time complexity
print("The time taken by LazyClassifier for {0} samples is {1} ms".format(len(data.data),round(end_time_1-start_time_1,0)))
print("The time taken by LazyRegressor for {0} samples is {1} ms".format(len(data1.data),round(end_time_2-start_time_2,0)))
Tip 3: Add %%time to check the execution time of the current jupyter cell
提示3:添加%% time以检查当前jupyter单元的执行时间
注意 (Note)
- Use this library in the first iteration of your ML project before hypertunning models 在对模型进行超调整之前,请在ML项目的第一个迭代中使用此库
- lazypredict only works for Python versions ≥3.6 lazypredict仅适用于Python版本≥3.6
- If you don’t have the computational power just use Google colab 如果您没有计算能力,请使用Google colab
The Github link is here for the code.
Github链接在此处提供代码。
If you want to read the official docs
如果您想阅读官方文档
That's all the things you need to know about lazypredict library for now
这就是您现在需要了解的关于lazypredict库的所有信息
Hope you learned new things from this article today and will help you to make your ML projects a bit easier
希望您今天从本文中学到了新东西,并可以帮助您简化ML项目
Thank you for dedicating a few mins of your day
感谢您奉献您的几分钟时间
If you have any doubts just comment down below I will be happy to help you out!
如果您有任何疑问,请在下方留言,我们将竭诚为您服务!
Thank you!
谢谢!
-Mani
-马尼
翻译自: https://medium.com/swlh/lazy-predict-for-ml-models-c513a5daf792
模型越复杂越容易惰性