数据导入与预处理-拓展-pandas筛选与修改
数据导入与预处理-拓展-pandas筛选与修改
- 1. 数据筛选与修改
-
- 1.1 加载数据
- 1.2 数据修改
-
- 1. 数据修改--修改列名
- 2. 数据修改--修改行索引
- 3. 数据修改--修改值
- 4. 数据修改--替换值
- 5. 数据修改-修改数据类型
- 1.3 数据新增
-
- 1. 数据新增-增加列 固定值
- 2. 数据新增-增加列 计算值
- 3. 数据新增-增加列 比较值
- 4. 数据新增-新增多列
- 5. 数据新增-增加列引用变量
- 6. 数据新增-新增行 指定位置
- 1.4 数据删除
-
- 1. 数据删除-删除指定行
- 2. 数据删除-指定多行(条件)
- 3. 数据删除-删除列
- 4. 数据删除-删除多列
- 1.5 数据筛选
-
- 1. 数据筛选-筛选指定列号
- 2. 数据筛选-筛选指定列名
- 4. 数据筛选-筛选指定行
- 4. 数据筛选-筛选行号+列名
- 2. 总结
1. 数据筛选与修改
数据的增删改查是 pandas 数据分析中最高频的操作,在分组、聚合、透视、可视化等多个操作中,数据的筛选、修改操作也会不断出现。
本文内容参考:微信公众号「早起Python」
1.1 加载数据
数据集下载
import sys
import os
import pandas as pd
df = pd.read_csv("东京奥运会奖牌数据.csv")
df
输出为:

1.2 数据修改
1. 数据修改–修改列名
把Unnamed: 2 Unnamed: 3 Unnamed: 4 分别代表 金牌数 银牌数 铜牌数
rename_dict = {'Unnamed: 2':'金牌数','Unnamed: 3':'银牌数','Unnamed: 4':'铜牌数'}
df.rename(columns=rename_dict,inplace=True)
df
输出为:

2. 数据修改–修改行索引
将第(国家奥委会)一列设置为索引
# 数据修改--修改行索引 将第(国家奥委会)一列设置为索引
df.set_index("国家奥委会").head()
输出为:

# 数据修改--修改行索引 将第(排名)一列设置为索引
df.set_index("排名").head()
输出为:

数据修改–修改索引名为 金牌排名:
# 数据修改--修改索引名为 金牌排名
df_new = df.set_index("排名").rename_axis("金牌排名")
df_new.head()
输出为:

3. 数据修改–修改值
# 将 ROC(第一列第五行)修改为 俄奥委会
df_new.iloc[4,0] = '俄奥委会'
df_new
输出为:

4. 数据修改–替换值
替换值(单值)
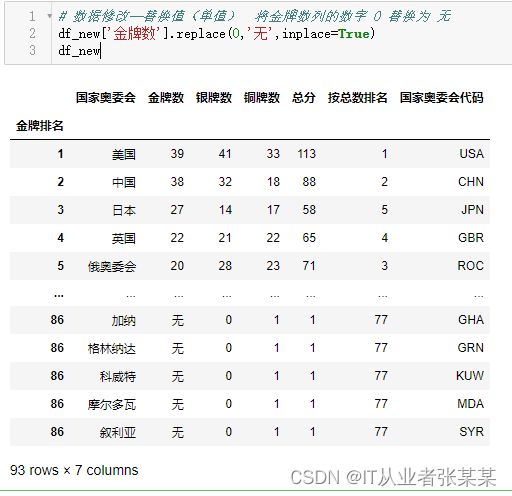
# 数据修改--替换值(单值) 将金牌数列的数字 0 替换为 无
df_new['金牌数'].replace(0,'无',inplace=True)
df_new
输出为:
替换值(多值)
# 数据修改--替换值(多值)
# 将 无 替换为 缺失值 将 0 替换为 None
import numpy as np
df_new.replace(['无',0],[np.nan,'None'],inplace = True)
df_new
输出为:

# 数据查看--看各列数据类型
df_new.info()
输出为:

5. 数据修改-修改数据类型
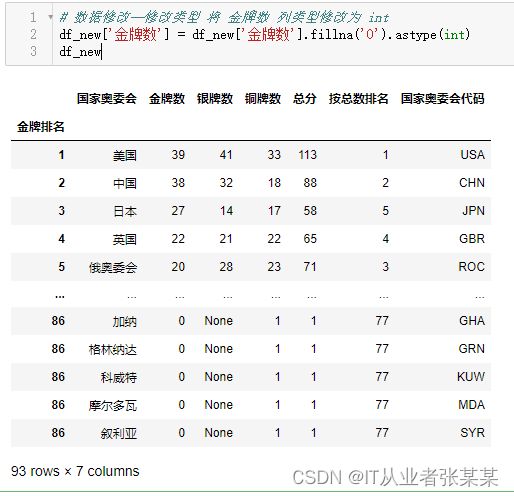
** 将 金牌数 列类型修改为 int**
# 数据修改--修改类型 将 金牌数 列类型修改为 int
df_new['金牌数'] = df_new['金牌数'].fillna('0').astype(int)
df_new
输出为:
1.3 数据新增
1. 数据新增-增加列 固定值
固定值 新增一列 比赛地点,值为 东京
# 重新加载数据 并 新增一列 比赛地点,值为 东京
df_new['比赛地点'] = '东京'
df_new
输出为:

2. 数据新增-增加列 计算值
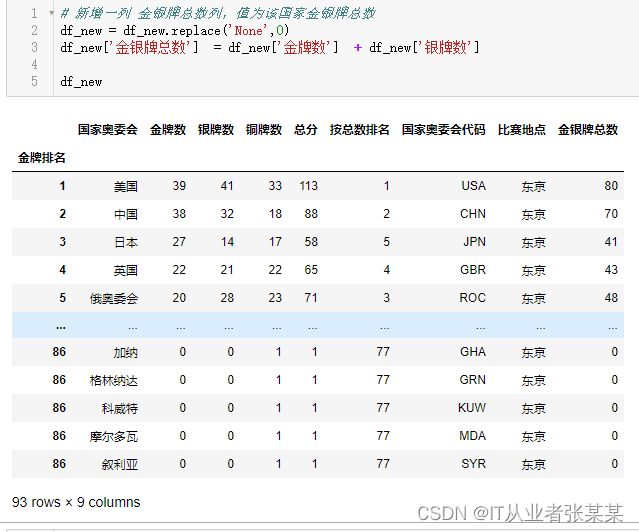
计算值 新增一列 金银牌总数列,值为该国家金银牌总数
# 新增一列 金银牌总数列,值为该国家金银牌总数
df_new = df_new.replace('None',0)
df_new['金银牌总数'] = df_new['金牌数'] + df_new['银牌数']
df_new
输出为:
# 查看指定列的最大值
df_new[["金牌数", "银牌数",'铜牌数']].max(0)
输出为:
金牌数 39
银牌数 41
铜牌数 33
dtype: int64
查看行数据中指定多列中的最大值
如果查看每个国家中金牌数银牌数铜牌数的最大值
df_new.bfill(1)[["金牌数", "银牌数",'铜牌数']].max(1)
输出为:
0 41.0
1 38.0
2 27.0
3 22.0
4 28.0
...
88 1.0
89 1.0
90 1.0
91 1.0
92 1.0
Length: 93, dtype: float64
新增一列计算值,值为每行中[“金牌数”, “银牌数”,‘铜牌数’]几列的最大值
df_new['最多奖牌数量'] = df_new.bfill(1)[["金牌数", "银牌数",'铜牌数']].max(1)
df_new
输出为:

3. 数据新增-增加列 比较值
新增一列比较值,如果一个国家的金牌数大于 20 则值为 是,反之为 否
df_new['金牌大于20'] = np.where(df_new['金牌数'] > 20, '是', '否')
df_new
输出为:

4. 数据新增-新增多列
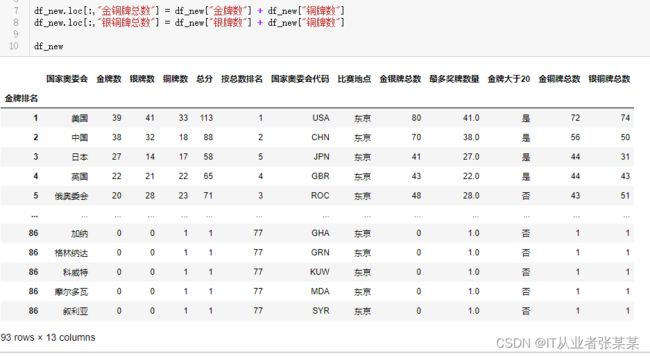
金铜牌总数(金牌数+铜牌数) 银铜牌总数(银牌数+铜牌数)
# 金铜牌总数(金牌数+铜牌数)
# 银铜牌总数(银牌数+铜牌数)
df_new.loc[:,"金铜牌总数"] = df_new["金牌数"] + df_new["铜牌数"]
df_new.loc[:,"银铜牌总数"] = df_new["银牌数"] + df_new["铜牌数"]
df_new
输出为:
5. 数据新增-增加列引用变量
计算金牌总数
# 新增一列金牌占比,为各国金牌数除以总金牌数(gold_sum)
gold_sum = df_new['金牌数'].sum()
gold_sum
输出为:
340
新增一列,金牌占比
df_new['金牌占比'] = df_new['金牌数'] / df_new['金牌数'].sum()
# del df['金牌占比1']
df_new
输出为:

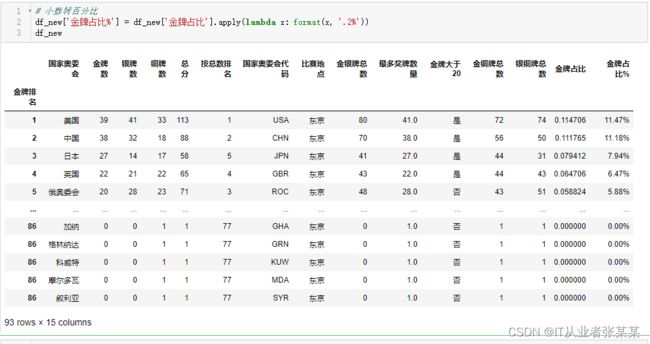
小数转百分比
# 小数转百分比
df_new['金牌占比%'] = df_new['金牌占比'].apply(lambda x: format(x, '.2%'))
df_new
输出为:
6. 数据新增-新增行 指定位置
在第2行新增一行数据
df1 = df_new.iloc[:1, :]
df2 = df_new.iloc[1:, :]
df3 = pd.DataFrame([[i for i in range(len(df_new.columns))]], columns=df_new.columns)
df3
输出为:

df_new = pd.concat([df1, df3, df2], ignore_index=True) # 索引会重新生成
df_new
输出为:

1.4 数据删除
1. 数据删除-删除指定行
# 数据删除|删除行
# 删除 df 第一行
df_new.drop(1)
输出为:

2. 数据删除-指定多行(条件)
# 数据删除|删除行(条件)
df_new.drop(df_new[df_new.金牌数<20].index)
输出为:

3. 数据删除-删除列
# 数据删除|删除列
# 删除刚刚新增的 比赛地点 列
df_new.drop(columns=['比赛地点'])
输出为:

4. 数据删除-删除多列
删除 df 的 7、8、9、10 列
df_new.drop(df_new.columns[[7,8,9,10]], axis=1)
输出为:

1.5 数据筛选
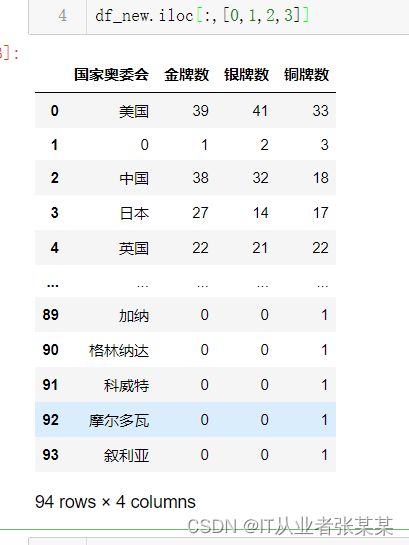
1. 数据筛选-筛选指定列号
提取第 1、2、3、4 列
# 提取第 1、2、3、4 列
df_new.iloc[:,[0,1,2,3]]
输出为:
提取第 奇数列
# 筛选全部 奇数列
df_new.iloc[:,[i % 2 != 0 for i in range(len(df_new.columns))]]
输出为:

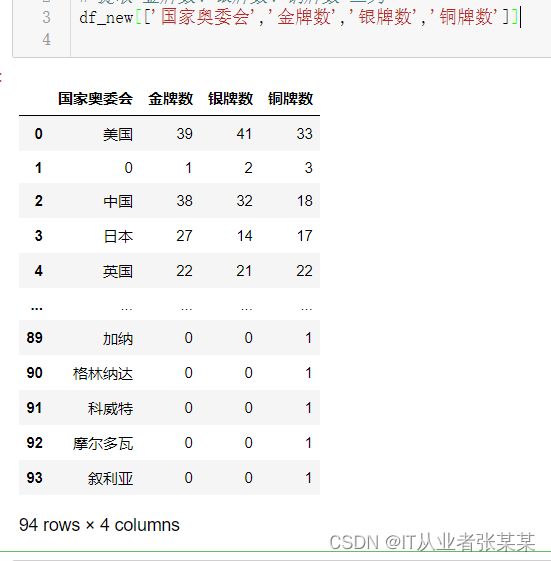
2. 数据筛选-筛选指定列名
# 提取 金牌数、银牌数、铜牌数 三列
df_new[['国家奥委会','金牌数','银牌数','铜牌数']]
输出为:
提取全部列名中以 “数” 结尾的列
# 提取全部列名中以 “数” 结尾的列
df_new.loc[:, df_new.columns.str.endswith('数')]
输出为:

4. 数据筛选-筛选指定行
提取 金牌数 不等于 39 的行
# 提取 金牌数 不等于 39 的行
df_new.loc[~(df_new['金牌数'] == 39)]
输出为:

提取全部 奇数行
# 提取全部 奇数行
df_new[[i%2==1 for i in range(len(df_new.index))]]
输出为:

提取 中国、美国、英国、日本、巴西 五行数据
# 筛选行|条件(指定值)
# 提取 中国、美国、英国、日本、巴西 五行数据
country_list = ["中国","美国","英国","日本","巴西"]
df_new.loc[df_new["国家奥委会"].isin(country_list)]
输出为:

提取 中国、美国、英国、日本、巴西 五行数据 并金牌数小于30
# 筛选行|多条件
# 提取 中国、美国、英国、日本、巴西 五行数据 并金牌数小于30
df_new.loc[(df_new['金牌数'] < 30) & (df_new['国家奥委会'].isin(['中国','美国','英国','日本','巴西']))]
输出为:

提取 国家奥委会 列中,所有包含 国的行
# 筛选行|条件(包含指定值)
# 提取 国家奥委会 列中,所有包含 国的行
df_new[df_new.国家奥委会.str.contains('国',na=False)] # 如果列中有字符串和数字类型需要家na=False
输出为:

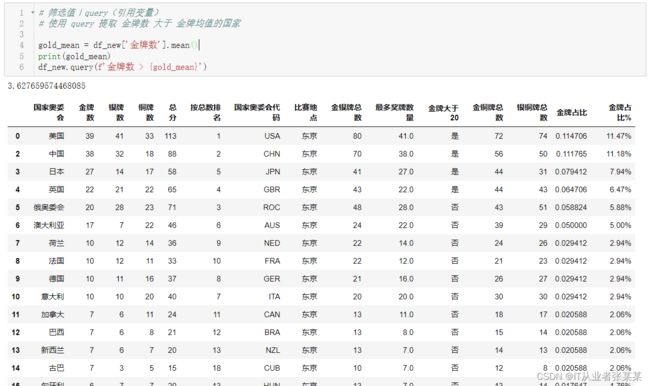
** 使用 query 提取 金牌数 大于 金牌均值的国家**
# 筛选值|query(引用变量)
# 使用 query 提取 金牌数 大于 金牌均值的国家
gold_mean = df_new['金牌数'].mean()
print(gold_mean)
df_new.query(f'金牌数 > {gold_mean}')
输出为:
4. 数据筛选-筛选行号+列名
# 提取10-20行,列名为"银铜牌总数"以及之后的数据
df_new.loc[10:20,"银铜牌总数":]
输出为:

2. 总结
本文主要完成了数据的增删改查操作,十分高效,可以点赞关注评论收藏,多谢查看。