mmdet之训练和推理
本文记录安装完mmdet后,如何进行训练和推理
一、数据准备
coco格式的,先用lableme将所有要处理的数据进行标注为json文件,然后通过如下脚本进行转换为coco格式,并可设置比例生成训练图片、训练标签、验证图片和验证标签。
labelme2coco.py:
import os
import json
import numpy as np
import glob
import shutil
from sklearn.model_selection import train_test_split
np.random.seed(41)
#0为背景
classname_to_id = {"flaw01": 2, "flaw02": 3, "flaw05": 4, "flaw07": 5, "other": 6, "watermark": 8}
classname_to_id = {"AZ03":1, "AZ06":2, "AZ07":3, "AZ08":4, "AZ09":5, "AZ11":6, "AZ12":7, "AZ14":8, "AZ17":9, "AZ18":10, "FUSION1":11, "FUSION2":12, "FUSION3":13, "FUSION4":14, "FUSION5":15, "FUSION6":16,"FUSION7":17, "FUSION8":18, "PHT07":19,"PLE04":20, "PVD02":21, "PVD04":22, "PVD05":23, "PVD06":24, "RES03":25,"RES04":26, "RES05":27, "RES07":28, "RES08":29, "STR06":30, "PLE04X":31}
class Lableme2CoCo:
def __init__(self):
self.images = []
self.annotations = []
self.categories = []
self.img_id = 0
self.ann_id = 0
def save_coco_json(self, instance, save_path):
json.dump(instance, open(save_path, 'w', encoding='utf-8'), ensure_ascii=False, indent=1) # indent=2 更加美观显示
# 由json文件构建COCO
def to_coco(self, json_path_list):
self._init_categories()
for json_path in json_path_list:
obj = self.read_jsonfile(json_path)
self.images.append(self._image(obj, json_path))
shapes = obj['shapes']
for shape in shapes:
annotation = self._annotation(shape)
self.annotations.append(annotation)
self.ann_id += 1
self.img_id += 1
instance = {}
instance['info'] = 'spytensor created'
instance['license'] = ['license']
instance['images'] = self.images
instance['annotations'] = self.annotations
instance['categories'] = self.categories
return instance
# 构建类别
def _init_categories(self):
for k, v in classname_to_id.items():
category = {}
category['id'] = v
category['name'] = k
self.categories.append(category)
# 构建COCO的image字段
def _image(self, obj, path):
image = {}
from labelme import utils
img_x = utils.img_b64_to_arr(obj['imageData'])
h, w = img_x.shape[:-1]
image['height'] = h
image['width'] = w
image['id'] = self.img_id
image['file_name'] = os.path.basename(path).replace(".json", ".jpg")
return image
# 构建COCO的annotation字段
def _annotation(self, shape):
label = shape['label']
points = shape['points']
annotation = {}
annotation['id'] = self.ann_id
annotation['image_id'] = self.img_id
annotation['category_id'] = int(classname_to_id[label])
annotation['segmentation'] = [np.asarray(points).flatten().tolist()]
annotation['bbox'] = self._get_box(points)
annotation['iscrowd'] = 0
annotation['area'] = 1.0
return annotation
# 读取json文件,返回一个json对象
def read_jsonfile(self, path):
with open(path, "r", encoding='utf-8') as f:
return json.load(f)
# COCO的格式: [x1,y1,w,h] 对应COCO的bbox格式
def _get_box(self, points):
min_x = min_y = np.inf
max_x = max_y = 0
for x, y in points:
min_x = min(min_x, x)
min_y = min(min_y, y)
max_x = max(max_x, x)
max_y = max(max_y, y)
return [min_x, min_y, max_x - min_x, max_y - min_y]
if __name__ == '__main__':
# json和影像放在一个文件夹下面
labelme_path = "data_labelme/"
saved_coco_path = "./"
# 创建文件
if not os.path.exists("%scoco/annotations/"%saved_coco_path):
os.makedirs("%scoco/annotations/"%saved_coco_path)
if not os.path.exists("%scoco/images/train2017/"%saved_coco_path):
os.makedirs("%scoco/images/train2017"%saved_coco_path)
if not os.path.exists("%scoco/images/val2017/"%saved_coco_path):
os.makedirs("%scoco/images/val2017"%saved_coco_path)
# 获取images目录下所有的joson文件列表
json_list_path = glob.glob(labelme_path + "/*.json")
# 数据划分,这里没有区分val2017和tran2017目录,所有图片都放在images目录下
train_path, val_path = train_test_split(json_list_path, test_size=0.2)
print("train_n:", len(train_path), 'val_n:', len(val_path))
# 把训练集转化为COCO的json格式
l2c_train = Lableme2CoCo()
train_instance = l2c_train.to_coco(train_path)
l2c_train.save_coco_json(train_instance, '%scoco/annotations/instances_train2017.json'%saved_coco_path)
for file in train_path:
shutil.copy(file.replace("json","jpg"),"%scoco/images/train2017/"%saved_coco_path)
for file in val_path:
shutil.copy(file.replace("json","jpg"),"%scoco/images/val2017/"%saved_coco_path)
# 把验证集转化为COCO的json格式
l2c_val = Lableme2CoCo()
val_instance = l2c_val.to_coco(val_path)
l2c_val.save_coco_json(val_instance, '%scoco/annotations/instances_val2017.json'%saved_coco_path)注:我这里的所有图片以及对应的labelme标注出来的json文件都一起放在data_labelme文件夹下。
二、准备配置文件
2.1 构建总体训练配置文件
在路径
/home/wt-yjy/project/code/mmdetection/configs/mask_rcnn下面新建一个配置文件,而不使用mask_rcnn_x101_64x4d_fpn_2x_coco.py这个配置文件,那么这是什么原因呢?
原因是:mask_rcnn_x101_64x4d_fpn_2x_coco.py这个配置文件打开后,我们就会发现其继承的路径非常复杂,如下:
(1)
_base_ = './mask_rcnn_x101_32x4d_fpn_2x_coco.py'
model = dict(
backbone=dict(
type='ResNeXt',
depth=101,
groups=64,
base_width=4,
num_stages=4,
out_indices=(0, 1, 2, 3),
frozen_stages=1,
norm_cfg=dict(type='BN', requires_grad=True),
style='pytorch',
init_cfg=dict(
type='Pretrained', checkpoint='open-mmlab://resnext101_64x4d')))这里可以看到其继承了mask_rcnn_x101_32x4d_fpn_2x_coco.py,因此我们又去这个py文件中看到:
(2)
_base_ = './mask_rcnn_r101_fpn_2x_coco.py'
model = dict(
backbone=dict(
type='ResNeXt',
depth=101,
groups=32,
base_width=4,
num_stages=4,
out_indices=(0, 1, 2, 3),
frozen_stages=1,
norm_cfg=dict(type='BN', requires_grad=True),
style='pytorch',
init_cfg=dict(
type='Pretrained', checkpoint='open-mmlab://resnext101_32x4d')))这里可以看到其继承了mask_rcnn_r101_fpn_2x_coco.py,因此我们又去这个py文件中看到:
(3)
_base_ = './mask_rcnn_r50_fpn_2x_coco.py'
model = dict(
backbone=dict(
depth=101,
init_cfg=dict(type='Pretrained',
checkpoint='torchvision://resnet101')))这里可以看到其继承了mask_rcnn_r50_fpn_2x_coco.py,因此我们又去这个py文件中看到:
(4)
_base_ = [
'../_base_/models/mask_rcnn_r50_fpn.py',
'../_base_/datasets/coco_instance.py',
'../_base_/schedules/schedule_2x.py', '../_base_/default_runtime.py'
]截至到这里就是基础模型'../_base_/models/mask_rcnn_r50_fpn.py',并且还给出了数据集加载,学习策略,运行调度方面的配置py文件。
我这里不想使用mask_rcnn_x101_64x4d_fpn_2x_coco.py这个配置文件,我想自己新建一个,并且直接没有中间这些模型继承,因此我新建的配置文件maskrcnn_tianma.py(放在/home/wt-yjy/project/code/mmdetection/configs/mask_rcnn下面)如下:
_base_ = [
'../_base_/models/mask_rcnn_r50_fpn.py',
'../_base_/datasets/tianma_maskrcnn_data.py',
'../_base_/schedules/schedule_2x.py', '../_base_/default_runtime.py'
]
#mask_rcnn_x101_64x4d_fpn_2x_coco.py
model = dict(
# 我们需要对头中的类别数量进行修改来匹配数据集的标注
roi_head=dict(bbox_head=dict(num_classes=31),
mask_head=dict(num_classes=31)),
backbone=dict(
type='ResNeXt',
depth=101,
groups=64,
base_width=4,
num_stages=4,
out_indices=(0, 1, 2, 3),
frozen_stages=1,
norm_cfg=dict(type='BN', requires_grad=True),
style='pytorch',
init_cfg=dict(
type='Pretrained', checkpoint='open-mmlab://resnext101_64x4d')))
# Re-config the sampler
# Re-config the optimizer
load_from = 'checkpoints/mask_rcnn_x101_64x4d_fpn_2x_coco.pth'
从上面也可以看出../_base_/datasets/tianma_maskrcnn_data.py文件如下:
# dataset settings
dataset_type = 'CocoDataset' #TianMaDataset
data_root = '/home/wt-yjy/project/code/mmdetection/custom_configs/dataset_root/tianma_dataset/timama_0616/'
img_norm_cfg = dict(
mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
train_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='LoadAnnotations', with_bbox=True, with_mask=True),
dict(type='Resize', img_scale=(1333, 800), keep_ratio=True),
dict(type='RandomFlip', flip_ratio=0.5),
dict(type='Normalize', **img_norm_cfg),
dict(type='Pad', size_divisor=32),
dict(type='DefaultFormatBundle'),
dict(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels', 'gt_masks']),
]
test_pipeline = [
dict(type='LoadImageFromFile'),
dict(
type='MultiScaleFlipAug',
img_scale=(1333, 800),
flip=False,
transforms=[
dict(type='Resize', keep_ratio=True),
dict(type='RandomFlip'),
dict(type='Normalize', **img_norm_cfg),
dict(type='Pad', size_divisor=32),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img']),
])
]
data = dict(
samples_per_gpu=2,
workers_per_gpu=2,
train=dict(
type=dataset_type,
ann_file=data_root + 'annotations/instances_train2017.json',
img_prefix=data_root + 'train2017/',
pipeline=train_pipeline),
val=dict(
type=dataset_type,
ann_file=data_root + 'annotations/instances_val2017.json',
img_prefix=data_root + 'val2017/',
pipeline=test_pipeline),
test=dict(
type=dataset_type,
ann_file=data_root + 'annotations/instances_val2017.json',
img_prefix=data_root + 'val2017/',
pipeline=test_pipeline))
evaluation = dict(metric=['bbox', 'segm'])注:这里data_root是通过建立软链接的方法,将真正的图片和标注文件放在挂载盘中,
cd mmdetection/custom_configs
mkdir dataset_root #在mmdetection目录里新建data目录
export COCO_ROOT=/mnt/DATA/yjy/tianma_dataset #创建链接到自己数据集的环境变量
ln -s $COCO_ROOT data #创建新数据集到data目录的软连接
#如果方便,也可以直接把数据集移动到data目录里,如此则上两步可省略2.2 修改基础配置文件
(1)/home/wt-yjy/project/code/mmdetection/configs/_base_/datasets/tianma_maskrcnn_data.py
# dataset settings
dataset_type = 'CocoDataset' #TianMaDataset
data_root = '/home/wt-yjy/project/code/mmdetection/custom_configs/dataset_root/tianma_dataset/timama_0616/'
img_norm_cfg = dict(
mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
train_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='LoadAnnotations', with_bbox=True, with_mask=True),
dict(type='Resize', img_scale=(1333, 800), keep_ratio=True),
dict(type='RandomFlip', flip_ratio=0.5),
dict(type='Normalize', **img_norm_cfg),
dict(type='Pad', size_divisor=32),
dict(type='DefaultFormatBundle'),
dict(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels', 'gt_masks']),
]
test_pipeline = [
dict(type='LoadImageFromFile'),
dict(
type='MultiScaleFlipAug',
img_scale=(1333, 800),
flip=False,
transforms=[
dict(type='Resize', keep_ratio=True),
dict(type='RandomFlip'),
dict(type='Normalize', **img_norm_cfg),
dict(type='Pad', size_divisor=32),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img']),
])
]
data = dict(
samples_per_gpu=2,
workers_per_gpu=2,
train=dict(
type=dataset_type,
ann_file=data_root + 'annotations/instances_train2017.json',
img_prefix=data_root + 'train2017/',
pipeline=train_pipeline),
val=dict(
type=dataset_type,
ann_file=data_root + 'annotations/instances_val2017.json',
img_prefix=data_root + 'val2017/',
pipeline=test_pipeline),
test=dict(
type=dataset_type,
ann_file=data_root + 'annotations/instances_val2017.json',
img_prefix=data_root + 'val2017/',
pipeline=test_pipeline))
evaluation = dict(metric=['bbox', 'segm'])(2) /home/wt-yjy/project/code/mmdetection/configs/_base_/default_runtime.py
checkpoint_config = dict(interval=1)
# yapf:disable
log_config = dict(
interval=50,
hooks=[
dict(type='TextLoggerHook'),
# dict(type='TensorboardLoggerHook')
])
# yapf:enable
custom_hooks = [dict(type='NumClassCheckHook')]
dist_params = dict(backend='nccl')
log_level = 'INFO'
load_from = None
resume_from = None
workflow = [('train', 1)]
# disable opencv multithreading to avoid system being overloaded
opencv_num_threads = 0
# set multi-process start method as `fork` to speed up the training
mp_start_method = 'fork'
# Default setting for scaling LR automatically
# - `enable` means enable scaling LR automatically
# or not by default.
# - `base_batch_size` = (8 GPUs) x (2 samples per GPU).
auto_scale_lr = dict(enable=False, base_batch_size=16)注:这个默认的,我没有修改
(3)/home/wt-yjy/project/code/mmdetection/configs/_base_/models/mask_rcnn_r50_fpn.py
# model settings
model = dict(
type='MaskRCNN',
backbone=dict(
type='ResNet',
depth=50,
num_stages=4,
out_indices=(0, 1, 2, 3),
frozen_stages=1,
norm_cfg=dict(type='BN', requires_grad=True),
norm_eval=True,
style='pytorch',
init_cfg=dict(type='Pretrained', checkpoint='torchvision://resnet50')),
neck=dict(
type='FPN',
in_channels=[256, 512, 1024, 2048],
out_channels=256,
num_outs=5),
rpn_head=dict(
type='RPNHead',
in_channels=256,
feat_channels=256,
anchor_generator=dict(
type='AnchorGenerator',
scales=[8],
ratios=[0.5, 1.0, 2.0],
strides=[4, 8, 16, 32, 64]),
bbox_coder=dict(
type='DeltaXYWHBBoxCoder',
target_means=[.0, .0, .0, .0],
target_stds=[1.0, 1.0, 1.0, 1.0]),
loss_cls=dict(
type='CrossEntropyLoss', use_sigmoid=True, loss_weight=1.0),
loss_bbox=dict(type='L1Loss', loss_weight=1.0)),
roi_head=dict(
type='StandardRoIHead',
bbox_roi_extractor=dict(
type='SingleRoIExtractor',
roi_layer=dict(type='RoIAlign', output_size=7, sampling_ratio=0),
out_channels=256,
featmap_strides=[4, 8, 16, 32]),
bbox_head=dict(
type='Shared2FCBBoxHead',
in_channels=256,
fc_out_channels=1024,
roi_feat_size=7,
num_classes=31,
bbox_coder=dict(
type='DeltaXYWHBBoxCoder',
target_means=[0., 0., 0., 0.],
target_stds=[0.1, 0.1, 0.2, 0.2]),
reg_class_agnostic=False,
loss_cls=dict(
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0),
loss_bbox=dict(type='L1Loss', loss_weight=1.0)),
mask_roi_extractor=dict(
type='SingleRoIExtractor',
roi_layer=dict(type='RoIAlign', output_size=14, sampling_ratio=0),
out_channels=256,
featmap_strides=[4, 8, 16, 32]),
mask_head=dict(
type='FCNMaskHead',
num_convs=4,
in_channels=256,
conv_out_channels=256,
num_classes=31,
loss_mask=dict(
type='CrossEntropyLoss', use_mask=True, loss_weight=1.0))),
# model training and testing settings
train_cfg=dict(
rpn=dict(
assigner=dict(
type='MaxIoUAssigner',
pos_iou_thr=0.7,
neg_iou_thr=0.3,
min_pos_iou=0.3,
match_low_quality=True,
ignore_iof_thr=-1),
sampler=dict(
type='RandomSampler',
num=256,
pos_fraction=0.5,
neg_pos_ub=-1,
add_gt_as_proposals=False),
allowed_border=-1,
pos_weight=-1,
debug=False),
rpn_proposal=dict(
nms_pre=2000,
max_per_img=1000,
nms=dict(type='nms', iou_threshold=0.7),
min_bbox_size=0),
rcnn=dict(
assigner=dict(
type='MaxIoUAssigner',
pos_iou_thr=0.5,
neg_iou_thr=0.5,
min_pos_iou=0.5,
match_low_quality=True,
ignore_iof_thr=-1),
sampler=dict(
type='RandomSampler',
num=512,
pos_fraction=0.25,
neg_pos_ub=-1,
add_gt_as_proposals=True),
mask_size=28,
pos_weight=-1,
debug=False)),
test_cfg=dict(
rpn=dict(
nms_pre=1000,
max_per_img=1000,
nms=dict(type='nms', iou_threshold=0.7),
min_bbox_size=0),
rcnn=dict(
score_thr=0.05,
nms=dict(type='nms', iou_threshold=0.5),
max_per_img=100,
mask_thr_binary=0.5)))注意:这里需要修改两个部位的num_classes=31,且注意这个类别就是你真正标注的缺陷类别,并不是像分割mmseg那样是:类别+背景。
(4)/home/wt-yjy/project/code/mmdetection/configs/_base_/schedules/schedule_2x.py
# optimizer
optimizer = dict(type='SGD', lr=0.002, momentum=0.9, weight_decay=0.0001)
optimizer_config = dict(grad_clip=None)
# learning policy
lr_config = dict(
policy='step',
warmup='linear',
warmup_iters=500,
warmup_ratio=0.001,
step=[5, 8, 11, 14, 17, 20])
runner = dict(type='EpochBasedRunner', max_epochs=24)注:
1)这里我首先修改了lr=0.002,默认是0.02,但是我使用默认的0.02直接训练一会就出选NAN了,直接也就是梯度爆炸了。
这个学习率设定,可以参考:
lr=0.005 for 2 GPUs * 2 imgs/gpu
lr=0.01 for 4 GPUs * 2 imgs/gpu
lr=0.02 for 8 GPUs and 2 img/gpu (batch size = 8*2 = 16), DEFAULT
lr=0.08 for 16 GPUs * 4 imgs/gpu# 因为模型默认的是8块GPU,每块gpu的sample为2,所以它的学习率是0.02
# 如果你是单卡,samples_per_gpu=1 相当于总batch size=1,那这个地方lr= 0.02/16 = 0.00125
# 如果你是单卡,samples_per_gpu=2 相当于总batch size=2, 那这个地方lr= 0.02/4 = 0.005
#...依此类推

参考:MMdetection2.0使用记录(一) - 知乎 (zhihu.com)
2)另外这个step我自己修改:在epoch:5、8、11、14、17、20这些处进行学习率衰减到上次学习率的十分之一。
(5)修改类别文件
/home/wt-yjy/project/code/mmdetection/mmdet/datasets/coco.py
# Copyright (c) OpenMMLab. All rights reserved.
import contextlib
import io
import itertools
import logging
import os.path as osp
import tempfile
import warnings
from collections import OrderedDict
import mmcv
import numpy as np
from mmcv.utils import print_log
from terminaltables import AsciiTable
from mmdet.core import eval_recalls
from .api_wrappers import COCO, COCOeval
from .builder import DATASETS
from .custom import CustomDataset
@DATASETS.register_module()
class CocoDataset(CustomDataset):
CLASSES = ('PLE04X', 'AZ03', 'AZ06', 'AZ07', 'AZ08', 'AZ09', 'AZ11',
'AZ12', 'AZ14', 'AZ17', 'AZ18', 'FUSION1',
'FUSION2', 'FUSION3', 'FUSION4', 'FUSION5', 'FUSION6', 'FUSION7',
'FUSION8', 'PHT07', 'PLE04', 'PVD02', 'PVD04', 'PVD05', 'PVD06',
'RES03', 'RES04', 'RES05', 'RES07', 'RES08', 'STR06')
PALETTE = [(220, 20, 60), (119, 11, 32), (0, 0, 142), (0, 0, 230),
(106, 0, 228), (0, 60, 100), (0, 80, 100), (0, 0, 70),
(0, 0, 192), (250, 170, 30), (100, 170, 30), (220, 220, 0),
(175, 116, 175), (250, 0, 30), (165, 42, 42), (255, 77, 255),
(0, 226, 252), (182, 182, 255), (0, 82, 0), (120, 166, 157),
(110, 76, 0), (174, 57, 255), (199, 100, 0), (72, 0, 118),
(255, 179, 240), (0, 125, 92), (209, 0, 151), (188, 208, 182),
(0, 220, 176), (255, 99, 164), (92, 0, 73)]
def load_annotations(self, ann_file):
"""Load annotation from COCO style annotation file.
Args:
ann_file (str): Path of annotation file.
Returns:
list[dict]: Annotation info from COCO api.
"""
self.coco = COCO(ann_file)
# The order of returned `cat_ids` will not
# change with the order of the CLASSES
self.cat_ids = self.coco.get_cat_ids(cat_names=self.CLASSES)
self.cat2label = {cat_id: i for i, cat_id in enumerate(self.cat_ids)}
self.img_ids = self.coco.get_img_ids()
data_infos = []
total_ann_ids = []
for i in self.img_ids:
info = self.coco.load_imgs([i])[0]
info['filename'] = info['file_name']
data_infos.append(info)
ann_ids = self.coco.get_ann_ids(img_ids=[i])
total_ann_ids.extend(ann_ids)
assert len(set(total_ann_ids)) == len(
total_ann_ids), f"Annotation ids in '{ann_file}' are not unique!"
return data_infos
def get_ann_info(self, idx):
"""Get COCO annotation by index.
Args:
idx (int): Index of data.
Returns:
dict: Annotation info of specified index.
"""
img_id = self.data_infos[idx]['id']
ann_ids = self.coco.get_ann_ids(img_ids=[img_id])
ann_info = self.coco.load_anns(ann_ids)
return self._parse_ann_info(self.data_infos[idx], ann_info)
def get_cat_ids(self, idx):
"""Get COCO category ids by index.
Args:
idx (int): Index of data.
Returns:
list[int]: All categories in the image of specified index.
"""
img_id = self.data_infos[idx]['id']
ann_ids = self.coco.get_ann_ids(img_ids=[img_id])
ann_info = self.coco.load_anns(ann_ids)
return [ann['category_id'] for ann in ann_info]
def _filter_imgs(self, min_size=32):
"""Filter images too small or without ground truths."""
valid_inds = []
# obtain images that contain annotation
ids_with_ann = set(_['image_id'] for _ in self.coco.anns.values())
# obtain images that contain annotations of the required categories
ids_in_cat = set()
for i, class_id in enumerate(self.cat_ids):
ids_in_cat |= set(self.coco.cat_img_map[class_id])
# merge the image id sets of the two conditions and use the merged set
# to filter out images if self.filter_empty_gt=True
ids_in_cat &= ids_with_ann
valid_img_ids = []
for i, img_info in enumerate(self.data_infos):
img_id = self.img_ids[i]
if self.filter_empty_gt and img_id not in ids_in_cat:
continue
if min(img_info['width'], img_info['height']) >= min_size:
valid_inds.append(i)
valid_img_ids.append(img_id)
self.img_ids = valid_img_ids
return valid_inds
def _parse_ann_info(self, img_info, ann_info):
"""Parse bbox and mask annotation.
Args:
ann_info (list[dict]): Annotation info of an image.
with_mask (bool): Whether to parse mask annotations.
Returns:
dict: A dict containing the following keys: bboxes, bboxes_ignore,\
labels, masks, seg_map. "masks" are raw annotations and not \
decoded into binary masks.
"""
gt_bboxes = []
gt_labels = []
gt_bboxes_ignore = []
gt_masks_ann = []
for i, ann in enumerate(ann_info):
if ann.get('ignore', False):
continue
x1, y1, w, h = ann['bbox']
inter_w = max(0, min(x1 + w, img_info['width']) - max(x1, 0))
inter_h = max(0, min(y1 + h, img_info['height']) - max(y1, 0))
if inter_w * inter_h == 0:
continue
if ann['area'] <= 0 or w < 1 or h < 1:
continue
if ann['category_id'] not in self.cat_ids:
continue
bbox = [x1, y1, x1 + w, y1 + h]
if ann.get('iscrowd', False):
gt_bboxes_ignore.append(bbox)
else:
gt_bboxes.append(bbox)
gt_labels.append(self.cat2label[ann['category_id']])
gt_masks_ann.append(ann.get('segmentation', None))
if gt_bboxes:
gt_bboxes = np.array(gt_bboxes, dtype=np.float32)
gt_labels = np.array(gt_labels, dtype=np.int64)
else:
gt_bboxes = np.zeros((0, 4), dtype=np.float32)
gt_labels = np.array([], dtype=np.int64)
if gt_bboxes_ignore:
gt_bboxes_ignore = np.array(gt_bboxes_ignore, dtype=np.float32)
else:
gt_bboxes_ignore = np.zeros((0, 4), dtype=np.float32)
seg_map = img_info['filename'].replace('jpg', 'png')
ann = dict(
bboxes=gt_bboxes,
labels=gt_labels,
bboxes_ignore=gt_bboxes_ignore,
masks=gt_masks_ann,
seg_map=seg_map)
return ann
def xyxy2xywh(self, bbox):
"""Convert ``xyxy`` style bounding boxes to ``xywh`` style for COCO
evaluation.
Args:
bbox (numpy.ndarray): The bounding boxes, shape (4, ), in
``xyxy`` order.
Returns:
list[float]: The converted bounding boxes, in ``xywh`` order.
"""
_bbox = bbox.tolist()
return [
_bbox[0],
_bbox[1],
_bbox[2] - _bbox[0],
_bbox[3] - _bbox[1],
]
def _proposal2json(self, results):
"""Convert proposal results to COCO json style."""
json_results = []
for idx in range(len(self)):
img_id = self.img_ids[idx]
bboxes = results[idx]
for i in range(bboxes.shape[0]):
data = dict()
data['image_id'] = img_id
data['bbox'] = self.xyxy2xywh(bboxes[i])
data['score'] = float(bboxes[i][4])
data['category_id'] = 1
json_results.append(data)
return json_results
def _det2json(self, results):
"""Convert detection results to COCO json style."""
json_results = []
for idx in range(len(self)):
img_id = self.img_ids[idx]
result = results[idx]
for label in range(len(result)):
bboxes = result[label]
for i in range(bboxes.shape[0]):
data = dict()
data['image_id'] = img_id
data['bbox'] = self.xyxy2xywh(bboxes[i])
data['score'] = float(bboxes[i][4])
data['category_id'] = self.cat_ids[label]
json_results.append(data)
return json_results
def _segm2json(self, results):
"""Convert instance segmentation results to COCO json style."""
bbox_json_results = []
segm_json_results = []
for idx in range(len(self)):
img_id = self.img_ids[idx]
det, seg = results[idx]
for label in range(len(det)):
# bbox results
bboxes = det[label]
for i in range(bboxes.shape[0]):
data = dict()
data['image_id'] = img_id
data['bbox'] = self.xyxy2xywh(bboxes[i])
data['score'] = float(bboxes[i][4])
data['category_id'] = self.cat_ids[label]
bbox_json_results.append(data)
# segm results
# some detectors use different scores for bbox and mask
if isinstance(seg, tuple):
segms = seg[0][label]
mask_score = seg[1][label]
else:
segms = seg[label]
mask_score = [bbox[4] for bbox in bboxes]
for i in range(bboxes.shape[0]):
data = dict()
data['image_id'] = img_id
data['bbox'] = self.xyxy2xywh(bboxes[i])
data['score'] = float(mask_score[i])
data['category_id'] = self.cat_ids[label]
if isinstance(segms[i]['counts'], bytes):
segms[i]['counts'] = segms[i]['counts'].decode()
data['segmentation'] = segms[i]
segm_json_results.append(data)
return bbox_json_results, segm_json_results
def results2json(self, results, outfile_prefix):
"""Dump the detection results to a COCO style json file.
There are 3 types of results: proposals, bbox predictions, mask
predictions, and they have different data types. This method will
automatically recognize the type, and dump them to json files.
Args:
results (list[list | tuple | ndarray]): Testing results of the
dataset.
outfile_prefix (str): The filename prefix of the json files. If the
prefix is "somepath/xxx", the json files will be named
"somepath/xxx.bbox.json", "somepath/xxx.segm.json",
"somepath/xxx.proposal.json".
Returns:
dict[str: str]: Possible keys are "bbox", "segm", "proposal", and \
values are corresponding filenames.
"""
result_files = dict()
if isinstance(results[0], list):
json_results = self._det2json(results)
result_files['bbox'] = f'{outfile_prefix}.bbox.json'
result_files['proposal'] = f'{outfile_prefix}.bbox.json'
mmcv.dump(json_results, result_files['bbox'])
elif isinstance(results[0], tuple):
json_results = self._segm2json(results)
result_files['bbox'] = f'{outfile_prefix}.bbox.json'
result_files['proposal'] = f'{outfile_prefix}.bbox.json'
result_files['segm'] = f'{outfile_prefix}.segm.json'
mmcv.dump(json_results[0], result_files['bbox'])
mmcv.dump(json_results[1], result_files['segm'])
elif isinstance(results[0], np.ndarray):
json_results = self._proposal2json(results)
result_files['proposal'] = f'{outfile_prefix}.proposal.json'
mmcv.dump(json_results, result_files['proposal'])
else:
raise TypeError('invalid type of results')
return result_files
def fast_eval_recall(self, results, proposal_nums, iou_thrs, logger=None):
gt_bboxes = []
for i in range(len(self.img_ids)):
ann_ids = self.coco.get_ann_ids(img_ids=self.img_ids[i])
ann_info = self.coco.load_anns(ann_ids)
if len(ann_info) == 0:
gt_bboxes.append(np.zeros((0, 4)))
continue
bboxes = []
for ann in ann_info:
if ann.get('ignore', False) or ann['iscrowd']:
continue
x1, y1, w, h = ann['bbox']
bboxes.append([x1, y1, x1 + w, y1 + h])
bboxes = np.array(bboxes, dtype=np.float32)
if bboxes.shape[0] == 0:
bboxes = np.zeros((0, 4))
gt_bboxes.append(bboxes)
recalls = eval_recalls(
gt_bboxes, results, proposal_nums, iou_thrs, logger=logger)
ar = recalls.mean(axis=1)
return ar
def format_results(self, results, jsonfile_prefix=None, **kwargs):
"""Format the results to json (standard format for COCO evaluation).
Args:
results (list[tuple | numpy.ndarray]): Testing results of the
dataset.
jsonfile_prefix (str | None): The prefix of json files. It includes
the file path and the prefix of filename, e.g., "a/b/prefix".
If not specified, a temp file will be created. Default: None.
Returns:
tuple: (result_files, tmp_dir), result_files is a dict containing \
the json filepaths, tmp_dir is the temporal directory created \
for saving json files when jsonfile_prefix is not specified.
"""
assert isinstance(results, list), 'results must be a list'
assert len(results) == len(self), (
'The length of results is not equal to the dataset len: {} != {}'.
format(len(results), len(self)))
if jsonfile_prefix is None:
tmp_dir = tempfile.TemporaryDirectory()
jsonfile_prefix = osp.join(tmp_dir.name, 'results')
else:
tmp_dir = None
result_files = self.results2json(results, jsonfile_prefix)
return result_files, tmp_dir
def evaluate_det_segm(self,
results,
result_files,
coco_gt,
metrics,
logger=None,
classwise=False,
proposal_nums=(100, 300, 1000),
iou_thrs=None,
metric_items=None):
"""Instance segmentation and object detection evaluation in COCO
protocol.
Args:
results (list[list | tuple | dict]): Testing results of the
dataset.
result_files (dict[str, str]): a dict contains json file path.
coco_gt (COCO): COCO API object with ground truth annotation.
metric (str | list[str]): Metrics to be evaluated. Options are
'bbox', 'segm', 'proposal', 'proposal_fast'.
logger (logging.Logger | str | None): Logger used for printing
related information during evaluation. Default: None.
classwise (bool): Whether to evaluating the AP for each class.
proposal_nums (Sequence[int]): Proposal number used for evaluating
recalls, such as recall@100, recall@1000.
Default: (100, 300, 1000).
iou_thrs (Sequence[float], optional): IoU threshold used for
evaluating recalls/mAPs. If set to a list, the average of all
IoUs will also be computed. If not specified, [0.50, 0.55,
0.60, 0.65, 0.70, 0.75, 0.80, 0.85, 0.90, 0.95] will be used.
Default: None.
metric_items (list[str] | str, optional): Metric items that will
be returned. If not specified, ``['AR@100', 'AR@300',
'AR@1000', 'AR_s@1000', 'AR_m@1000', 'AR_l@1000' ]`` will be
used when ``metric=='proposal'``, ``['mAP', 'mAP_50', 'mAP_75',
'mAP_s', 'mAP_m', 'mAP_l']`` will be used when
``metric=='bbox' or metric=='segm'``.
Returns:
dict[str, float]: COCO style evaluation metric.
"""
if iou_thrs is None:
iou_thrs = np.linspace(
.5, 0.95, int(np.round((0.95 - .5) / .05)) + 1, endpoint=True)
if metric_items is not None:
if not isinstance(metric_items, list):
metric_items = [metric_items]
eval_results = OrderedDict()
for metric in metrics:
msg = f'Evaluating {metric}...'
if logger is None:
msg = '\n' + msg
print_log(msg, logger=logger)
if metric == 'proposal_fast':
if isinstance(results[0], tuple):
raise KeyError('proposal_fast is not supported for '
'instance segmentation result.')
ar = self.fast_eval_recall(
results, proposal_nums, iou_thrs, logger='silent')
log_msg = []
for i, num in enumerate(proposal_nums):
eval_results[f'AR@{num}'] = ar[i]
log_msg.append(f'\nAR@{num}\t{ar[i]:.4f}')
log_msg = ''.join(log_msg)
print_log(log_msg, logger=logger)
continue
iou_type = 'bbox' if metric == 'proposal' else metric
if metric not in result_files:
raise KeyError(f'{metric} is not in results')
try:
predictions = mmcv.load(result_files[metric])
if iou_type == 'segm':
# Refer to https://github.com/cocodataset/cocoapi/blob/master/PythonAPI/pycocotools/coco.py#L331 # noqa
# When evaluating mask AP, if the results contain bbox,
# cocoapi will use the box area instead of the mask area
# for calculating the instance area. Though the overall AP
# is not affected, this leads to different
# small/medium/large mask AP results.
for x in predictions:
x.pop('bbox')
warnings.simplefilter('once')
warnings.warn(
'The key "bbox" is deleted for more accurate mask AP '
'of small/medium/large instances since v2.12.0. This '
'does not change the overall mAP calculation.',
UserWarning)
coco_det = coco_gt.loadRes(predictions)
except IndexError:
print_log(
'The testing results of the whole dataset is empty.',
logger=logger,
level=logging.ERROR)
break
cocoEval = COCOeval(coco_gt, coco_det, iou_type)
cocoEval.params.catIds = self.cat_ids
cocoEval.params.imgIds = self.img_ids
cocoEval.params.maxDets = list(proposal_nums)
cocoEval.params.iouThrs = iou_thrs
# mapping of cocoEval.stats
coco_metric_names = {
'mAP': 0,
'mAP_50': 1,
'mAP_75': 2,
'mAP_s': 3,
'mAP_m': 4,
'mAP_l': 5,
'AR@100': 6,
'AR@300': 7,
'AR@1000': 8,
'AR_s@1000': 9,
'AR_m@1000': 10,
'AR_l@1000': 11
}
if metric_items is not None:
for metric_item in metric_items:
if metric_item not in coco_metric_names:
raise KeyError(
f'metric item {metric_item} is not supported')
if metric == 'proposal':
cocoEval.params.useCats = 0
cocoEval.evaluate()
cocoEval.accumulate()
# Save coco summarize print information to logger
redirect_string = io.StringIO()
with contextlib.redirect_stdout(redirect_string):
cocoEval.summarize()
print_log('\n' + redirect_string.getvalue(), logger=logger)
if metric_items is None:
metric_items = [
'AR@100', 'AR@300', 'AR@1000', 'AR_s@1000',
'AR_m@1000', 'AR_l@1000'
]
for item in metric_items:
val = float(
f'{cocoEval.stats[coco_metric_names[item]]:.3f}')
eval_results[item] = val
else:
cocoEval.evaluate()
cocoEval.accumulate()
# Save coco summarize print information to logger
redirect_string = io.StringIO()
with contextlib.redirect_stdout(redirect_string):
cocoEval.summarize()
print_log('\n' + redirect_string.getvalue(), logger=logger)
if classwise: # Compute per-category AP
# Compute per-category AP
# from https://github.com/facebookresearch/detectron2/
precisions = cocoEval.eval['precision']
# precision: (iou, recall, cls, area range, max dets)
assert len(self.cat_ids) == precisions.shape[2]
results_per_category = []
for idx, catId in enumerate(self.cat_ids):
# area range index 0: all area ranges
# max dets index -1: typically 100 per image
nm = self.coco.loadCats(catId)[0]
precision = precisions[:, :, idx, 0, -1]
precision = precision[precision > -1]
if precision.size:
ap = np.mean(precision)
else:
ap = float('nan')
results_per_category.append(
(f'{nm["name"]}', f'{float(ap):0.3f}'))
num_columns = min(6, len(results_per_category) * 2)
results_flatten = list(
itertools.chain(*results_per_category))
headers = ['category', 'AP'] * (num_columns // 2)
results_2d = itertools.zip_longest(*[
results_flatten[i::num_columns]
for i in range(num_columns)
])
table_data = [headers]
table_data += [result for result in results_2d]
table = AsciiTable(table_data)
print_log('\n' + table.table, logger=logger)
if metric_items is None:
metric_items = [
'mAP', 'mAP_50', 'mAP_75', 'mAP_s', 'mAP_m', 'mAP_l'
]
for metric_item in metric_items:
key = f'{metric}_{metric_item}'
val = float(
f'{cocoEval.stats[coco_metric_names[metric_item]]:.3f}'
)
eval_results[key] = val
ap = cocoEval.stats[:6]
eval_results[f'{metric}_mAP_copypaste'] = (
f'{ap[0]:.3f} {ap[1]:.3f} {ap[2]:.3f} {ap[3]:.3f} '
f'{ap[4]:.3f} {ap[5]:.3f}')
return eval_results
def evaluate(self,
results,
metric='bbox',
logger=None,
jsonfile_prefix=None,
classwise=False,
proposal_nums=(100, 300, 1000),
iou_thrs=None,
metric_items=None):
"""Evaluation in COCO protocol.
Args:
results (list[list | tuple]): Testing results of the dataset.
metric (str | list[str]): Metrics to be evaluated. Options are
'bbox', 'segm', 'proposal', 'proposal_fast'.
logger (logging.Logger | str | None): Logger used for printing
related information during evaluation. Default: None.
jsonfile_prefix (str | None): The prefix of json files. It includes
the file path and the prefix of filename, e.g., "a/b/prefix".
If not specified, a temp file will be created. Default: None.
classwise (bool): Whether to evaluating the AP for each class.
proposal_nums (Sequence[int]): Proposal number used for evaluating
recalls, such as recall@100, recall@1000.
Default: (100, 300, 1000).
iou_thrs (Sequence[float], optional): IoU threshold used for
evaluating recalls/mAPs. If set to a list, the average of all
IoUs will also be computed. If not specified, [0.50, 0.55,
0.60, 0.65, 0.70, 0.75, 0.80, 0.85, 0.90, 0.95] will be used.
Default: None.
metric_items (list[str] | str, optional): Metric items that will
be returned. If not specified, ``['AR@100', 'AR@300',
'AR@1000', 'AR_s@1000', 'AR_m@1000', 'AR_l@1000' ]`` will be
used when ``metric=='proposal'``, ``['mAP', 'mAP_50', 'mAP_75',
'mAP_s', 'mAP_m', 'mAP_l']`` will be used when
``metric=='bbox' or metric=='segm'``.
Returns:
dict[str, float]: COCO style evaluation metric.
"""
metrics = metric if isinstance(metric, list) else [metric]
allowed_metrics = ['bbox', 'segm', 'proposal', 'proposal_fast']
for metric in metrics:
if metric not in allowed_metrics:
raise KeyError(f'metric {metric} is not supported')
coco_gt = self.coco
self.cat_ids = coco_gt.get_cat_ids(cat_names=self.CLASSES)
result_files, tmp_dir = self.format_results(results, jsonfile_prefix)
eval_results = self.evaluate_det_segm(results, result_files, coco_gt,
metrics, logger, classwise,
proposal_nums, iou_thrs,
metric_items)
if tmp_dir is not None:
tmp_dir.cleanup()
return eval_results修改:/home/wt-yjy/project/code/mmdetection/mmdet/core/evaluation/class_names.py
我这里只用了coco格式标注文件,因此只需要更改coco_classes函数。
def coco_classes():
return [
'PLE04X', 'AZ03', 'AZ06', 'AZ07', 'AZ08', 'AZ09', 'AZ11',
'AZ12', 'AZ14', 'AZ17', 'AZ18', 'FUSION1',
'FUSION2', 'FUSION3', 'FUSION4', 'FUSION5', 'FUSION6', 'FUSION7',
'FUSION8', 'PHT07', 'PLE04', 'PVD02', 'PVD04', 'PVD05', 'PVD06',
'RES03', 'RES04', 'RES05', 'RES07', 'RES08', 'STR06'
]
注意:coco.py与要class_names.py中的缺陷名称要完全对应,包括顺序!
2.3 开始训练
~/project/code/mmdetection$ python tools/train.py configs/mask_rcnn/maskrcnn_tianma.py --work-dir work_dirs/
注:在mmdetection文件目录下新建文件夹work_dirs,这个文件夹后续后存放我们训练的log和权重文件。
2.4 开始推理无标注图片
官方的代码是在demo文件夹下,我自己从网上找了如下代码:
image_inference.py
from argparse import ArgumentParser
import os
from mmdet.apis import inference_detector, init_detector #, show_result_pyplot
import cv2
def show_result_pyplot(model, img, result, score_thr=0.3, fig_size=(15, 10)):
"""Visualize the detection results on the image.
Args:
model (nn.Module): The loaded detector.
img (str or np.ndarray): Image filename or loaded image.
result (tuple[list] or list): The detection result, can be either
(bbox, segm) or just bbox.
score_thr (float): The threshold to visualize the bboxes and masks.
fig_size (tuple): Figure size of the pyplot figure.
"""
if hasattr(model, 'module'):
model = model.module
img = model.show_result(img, result, score_thr=score_thr, show=False)
return img
# plt.figure(figsize=fig_size)
# plt.imshow(mmcv.bgr2rgb(img))
# plt.show()
def main():
# config文件
config_file = '../configs/mask_rcnn/maskrcnn_tianma.py'
# 训练好的模型
checkpoint_file = '../work_dirs/maskrcnn_x101_64d/epoch_21.pth'
# model = init_detector(config_file, checkpoint_file)
model = init_detector(config_file, checkpoint_file, device='cuda:0')
# 图片路径
img_dir = 'demo_pic/'
# 检测后存放图片路径
out_dir = 'infer_result/'
if not os.path.exists(out_dir):
os.mkdir(out_dir)
# 测试集的图片名称txt
test_path = './img.txt'
fp = open(test_path, 'r')
test_list = fp.readlines()
count = 0
imgs = []
for test in test_list:
test = test.replace('\n', '')
test = test.split('.')[0] # 如果test里面内容的名字是xxx.jpg,需要这行语句,是因为生成的图片会出现.jpg.jpg,否则不需要。
name = img_dir + test + '.jpg'
count += 1
print('model is processing the {}/{} images.'.format(count, len(test_list)))
# result = inference_detector(model, name)
# model = init_detector(config_file, checkpoint_file, device='cuda:0')
result = inference_detector(model, name)
img = show_result_pyplot(model, name, result, score_thr=0.5)
cv2.imwrite("{}/{}.jpg".format(out_dir, test), img)
if __name__ == '__main__':
main()注:这段代码我后面还要修改,因为这种要增加一个img.txt的方式太麻烦了!还是通过glob模块获取图片路径的集合更加方便!
另外注意这里传递进去的是一个图片的路径,根据追踪发现其进入mmdetection/mmdet/apis/inference.py中:
# Copyright (c) OpenMMLab. All rights reserved.
import warnings
from pathlib import Path
import mmcv
import numpy as np
import torch
from mmcv.ops import RoIPool
from mmcv.parallel import collate, scatter
from mmcv.runner import load_checkpoint
from mmdet.core import get_classes
from mmdet.datasets import replace_ImageToTensor
from mmdet.datasets.pipelines import Compose
from mmdet.models import build_detector
def init_detector(config, checkpoint=None, device='cuda:0', cfg_options=None):
"""Initialize a detector from config file.
Args:
config (str, :obj:`Path`, or :obj:`mmcv.Config`): Config file path,
:obj:`Path`, or the config object.
checkpoint (str, optional): Checkpoint path. If left as None, the model
will not load any weights.
cfg_options (dict): Options to override some settings in the used
config.
Returns:
nn.Module: The constructed detector.
"""
if isinstance(config, (str, Path)):
config = mmcv.Config.fromfile(config)
elif not isinstance(config, mmcv.Config):
raise TypeError('config must be a filename or Config object, '
f'but got {type(config)}')
if cfg_options is not None:
config.merge_from_dict(cfg_options)
if 'pretrained' in config.model:
config.model.pretrained = None
elif 'init_cfg' in config.model.backbone:
config.model.backbone.init_cfg = None
config.model.train_cfg = None
model = build_detector(config.model, test_cfg=config.get('test_cfg'))
if checkpoint is not None:
checkpoint = load_checkpoint(model, checkpoint, map_location='cpu')
if 'CLASSES' in checkpoint.get('meta', {}):
model.CLASSES = checkpoint['meta']['CLASSES']
else:
warnings.simplefilter('once')
warnings.warn('Class names are not saved in the checkpoint\'s '
'meta data, use COCO classes by default.')
model.CLASSES = get_classes('coco')
model.cfg = config # save the config in the model for convenience
model.to(device)
model.eval()
return model
class LoadImage:
"""Deprecated.
A simple pipeline to load image.
"""
def __call__(self, results):
"""Call function to load images into results.
Args:
results (dict): A result dict contains the file name
of the image to be read.
Returns:
dict: ``results`` will be returned containing loaded image.
"""
warnings.simplefilter('once')
warnings.warn('`LoadImage` is deprecated and will be removed in '
'future releases. You may use `LoadImageFromWebcam` '
'from `mmdet.datasets.pipelines.` instead.')
if isinstance(results['img'], str):
results['filename'] = results['img']
results['ori_filename'] = results['img']
else:
results['filename'] = None
results['ori_filename'] = None
img = mmcv.imread(results['img'])
results['img'] = img
results['img_fields'] = ['img']
results['img_shape'] = img.shape
results['ori_shape'] = img.shape
return results
def inference_detector(model, imgs):
"""Inference image(s) with the detector.
Args:
model (nn.Module): The loaded detector.
imgs (str/ndarray or list[str/ndarray] or tuple[str/ndarray]):
Either image files or loaded images.
Returns:
If imgs is a list or tuple, the same length list type results
will be returned, otherwise return the detection results directly.
"""
if isinstance(imgs, (list, tuple)):
is_batch = True
else:
imgs = [imgs]
is_batch = False
cfg = model.cfg
device = next(model.parameters()).device # model device
if isinstance(imgs[0], np.ndarray):
cfg = cfg.copy()
# set loading pipeline type
cfg.data.test.pipeline[0].type = 'LoadImageFromWebcam'
cfg.data.test.pipeline = replace_ImageToTensor(cfg.data.test.pipeline)
test_pipeline = Compose(cfg.data.test.pipeline)
datas = []
for img in imgs:
# prepare data
if isinstance(img, np.ndarray):
# directly add img
data = dict(img=img)
else:
# add information into dict
data = dict(img_info=dict(filename=img), img_prefix=None)
# build the data pipeline
data = test_pipeline(data)
datas.append(data)
data = collate(datas, samples_per_gpu=len(imgs))
# just get the actual data from DataContainer
data['img_metas'] = [img_metas.data[0] for img_metas in data['img_metas']]
data['img'] = [img.data[0] for img in data['img']]
if next(model.parameters()).is_cuda:
# scatter to specified GPU
data = scatter(data, [device])[0]
else:
for m in model.modules():
assert not isinstance(
m, RoIPool
), 'CPU inference with RoIPool is not supported currently.'
# forward the model
with torch.no_grad():
results = model(return_loss=False, rescale=True, **data)
if not is_batch:
return results[0]
else:
return results
async def async_inference_detector(model, imgs):
"""Async inference image(s) with the detector.
Args:
model (nn.Module): The loaded detector.
img (str | ndarray): Either image files or loaded images.
Returns:
Awaitable detection results.
"""
if not isinstance(imgs, (list, tuple)):
imgs = [imgs]
cfg = model.cfg
device = next(model.parameters()).device # model device
if isinstance(imgs[0], np.ndarray):
cfg = cfg.copy()
# set loading pipeline type
cfg.data.test.pipeline[0].type = 'LoadImageFromWebcam'
cfg.data.test.pipeline = replace_ImageToTensor(cfg.data.test.pipeline)
test_pipeline = Compose(cfg.data.test.pipeline)
datas = []
for img in imgs:
# prepare data
if isinstance(img, np.ndarray):
# directly add img
data = dict(img=img)
else:
# add information into dict
data = dict(img_info=dict(filename=img), img_prefix=None)
# build the data pipeline
data = test_pipeline(data)
datas.append(data)
data = collate(datas, samples_per_gpu=len(imgs))
# just get the actual data from DataContainer
data['img_metas'] = [img_metas.data[0] for img_metas in data['img_metas']]
data['img'] = [img.data[0] for img in data['img']]
if next(model.parameters()).is_cuda:
# scatter to specified GPU
data = scatter(data, [device])[0]
else:
for m in model.modules():
assert not isinstance(
m, RoIPool
), 'CPU inference with RoIPool is not supported currently.'
# We don't restore `torch.is_grad_enabled()` value during concurrent
# inference since execution can overlap
torch.set_grad_enabled(False)
results = await model.aforward_test(rescale=True, **data)
return results
def show_result_pyplot(model,
img,
result,
score_thr=0.3,
title='result',
wait_time=0,
palette=None,
out_file=None):
"""Visualize the detection results on the image.
Args:
model (nn.Module): The loaded detector.
img (str or np.ndarray): Image filename or loaded image.
result (tuple[list] or list): The detection result, can be either
(bbox, segm) or just bbox.
score_thr (float): The threshold to visualize the bboxes and masks.
title (str): Title of the pyplot figure.
wait_time (float): Value of waitKey param. Default: 0.
palette (str or tuple(int) or :obj:`Color`): Color.
The tuple of color should be in BGR order.
out_file (str or None): The path to write the image.
Default: None.
"""
if hasattr(model, 'module'):
model = model.module
model.show_result(
img,
result,
score_thr=score_thr,
show=True,
wait_time=wait_time,
win_name=title,
bbox_color=palette,
text_color=(200, 200, 200),
mask_color=palette,
out_file=out_file)这个inference.py中让我们可以看到:可以进行批推理(用list或者tuple包裹进去)、可以使用opencv读取图片成为numpy array传入推理。
另外注意很多时候使用的都是

这个正是来源于处理数据的/home/wt-yjy/project/code/mmdetection/configs/_base_/datasets/tianma_maskrcnn_data.py:
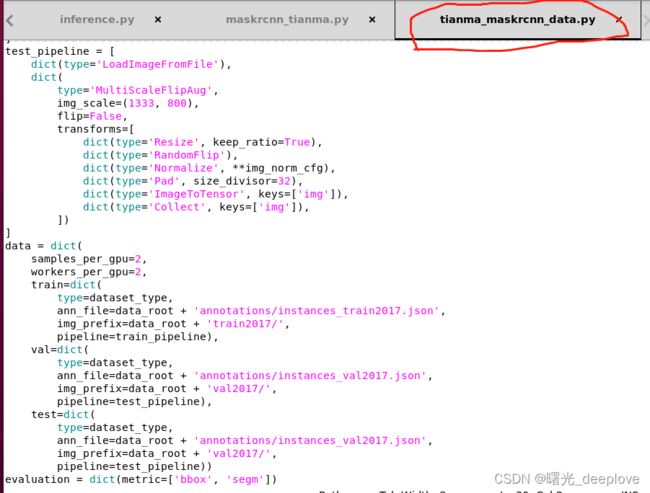
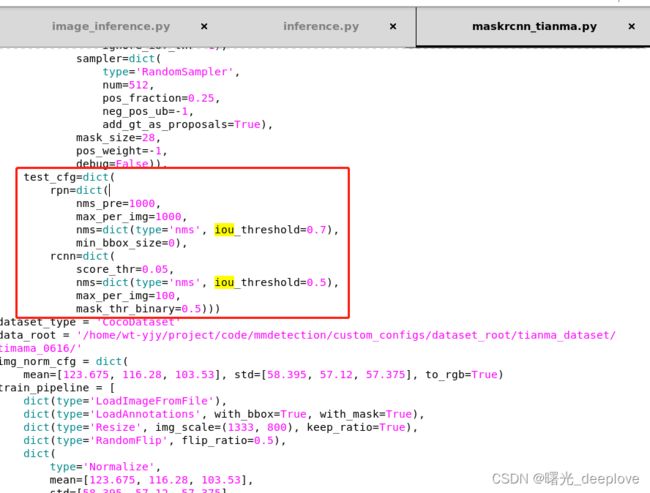
另外注意关于模型的配置(比如nms的iou阈值)也是有的:


三、训练命令、推理命令
训练:
![]()
推理:
四、补充
4.1
参考:
mmdetection使用自定义数据集进行训练 - 知乎
MMDetection 快速开始,训练自定义数据集 - 知乎
MMDetection2(四):训练自己的数据集 - 知乎 (zhihu.com)
本节是我发现我们的配置文件可以更加简单一些,
(1)
# 这个新的配置文件继承自一个原始配置文件,只需要突出必要的修改部分即可
#_base_ = '../mask_rcnn/mask_rcnn_r50_caffe_fpn_mstrain-poly_1x_coco.py' # 相对路径 (原始的配置文件模块)
_base_ = 'H:\mmdetection\configs/mask_rcnn/mask_rcnn_r50_caffe_fpn_mstrain-poly_1x_coco.py' # 绝对路径
# 我们需要对头中的类别数量进行修改来匹配数据集的标注
model = dict(
roi_head=dict(bbox_head=dict(num_classes=1),
mask_head=dict(num_classes=1)))
# 修改数据集相关设置
dataset_type = 'COCODataset' # 数据类型
classes = ('balloon',) # 检测类别为balloon
# img_prefix: 影像的路径,
# classes: 数据类别
# ann_file: 标注的信息文件,也是就是之前生成的json文件
# 注意这里的路径根据自己的实际路径来进行修改
data = dict(
train=dict(
img_prefix='H:\mmdetection\Aproject_doc/ball_detection\data/balloon/train/',
classes=classes,
ann_file='H:\mmdetection\Aproject_doc/ball_detection\data/balloon/train/annotation_coco.json'),
val=dict(
img_prefix='H:\mmdetection\Aproject_doc/ball_detection\data/balloon/val/',
classes=classes,
ann_file='H:\mmdetection\Aproject_doc/ball_detection\data/balloon/val/annotation_coco.json'),
test=dict(
img_prefix='H:\mmdetection\Aproject_doc/ball_detection\data/balloon/val/',
classes=classes,
ann_file='H:\mmdetection\Aproject_doc/ball_detection\data/balloon/val/annotation_coco.json'))
# 我们可以使用预训练的 Mask R-CNN 来获取更好的性能
# 该模型参数文件为下载好的pth,也可以用自己训练的模型参数
load_from = r'H:\mmdetection\Aproject_doc\ball_detection\checkpoints\mask_rcnn_r50_caffe_fpn_mstrain-poly_3x_coco_bbox_mAP-0.408__segm_mAP-0.37_20200504_163245-42aa3d00.pth'(2)
# The new config inherits a base config to highlight the necessary modification
_base_ = [
'../_base_/models/faster_rcnn_r50_fpn.py',
'../_base_/datasets/coco_detection.py',
'../_base_/schedules/schedule_1x.py', '../_base_/default_runtime.py'
]
# We also need to change the num_classes in head to match the dataset's annotation
model = dict(
roi_head=dict(
bbox_head=dict(num_classes=1)))
# Modify dataset related settings
dataset_type = 'COCODataset'
classes = ('cat',)
data_root = '/home/john/datasets/'
data = dict(
train=dict(
img_prefix=data_root + 'VOC2012/JPEGImages/',
classes=classes,
ann_file=data_root + 'coco_voc2012_cat/annotations/instances_train.json'),
val=dict(
img_prefix=data_root + 'VOC2012/JPEGImages/',
classes=classes,
ann_file=data_root + 'coco_voc2012_cat/annotations/instances_val.json'),
test=dict(
img_prefix=data_root + 'VOC2012/JPEGImages/',
classes=classes,
ann_file=data_root + 'coco_voc2012_cat/annotations/instances_val.json'))
evaluation = dict(interval=100)
# Modify schedule related settings
optimizer = dict(type='SGD', lr=0.005, momentum=0.9, weight_decay=0.0001)
total_epochs = 10000
# Modify runtime related settings
checkpoint_config = dict(interval=10)
# We can use the pre-trained model to obtain higher performance
# load_from = 'checkpoints/*.pth'(3)
# 1、这个新的配置文件继承了基础的配置文件(下面这一行就是继承父类配置文件的意思)
_base_ = 'mask_rcnn/mask_rcnn_r50_caffe_fpn_mstrain-poly_1x_coco.py'
# 2、我们需要对类别数进行一下修改 num_classes的数目按照自己项目来
# 注意一下num_classes填写的数目不包括背景(例如如果你是总共32个类别,加上背景33个类别,这个地方只需要填32就好了)
model = dict(
roi_head=dict(
bbox_head=dict(num_classes=1),
mask_head=dict(num_classes=1)))
# 3、更改数据集的参数
dataset_type = 'CocoDataset' #数据集的格式类型COCODataset 它会按照COCO的格式来读取导入数据
classes = ('balloon',) # 自己数据集中各个类别的名称(背景的名称不用写上去)
data = dict(
samples_per_gpu=2, #每块GPU上的sample的个数,batch_size = gpu数目*samples_per_gpu
workers_per_gpu=2, #每块GPU上的workers的个数
train=dict(
img_prefix='balloon/train/', #自己转为COCO数据集中train文件夹路径
classes=classes,
ann_file='balloon/train/annotation_coco.json'), #自己转化为COCO数据集train中的标签文件路径
val=dict(
img_prefix='balloon/val/', #自己转为COCO数据集中val文件夹路径
classes=classes,
ann_file='balloon/val/annotation_coco.json'), #自己转为COCO数据集中val中标签文件路径
# 这个地方的测试集信息和val是一样的,如果自己单独还做了测试集,可以改成自己测试集的路径,没有的话,就和上面val保持一致。
test=dict(
img_prefix='balloon/val/', #自己转为COCO数据集中val文件夹路径
classes=classes,
ann_file='balloon/val/annotation_coco.json')) #自己转为COCO数据集中val中标签文件路径
# 4、设置优化器的学习率
# 因为模型默认的是8块GPU,每块gpu的sample为2,所以它的学习率是0.02
# 如果你是单卡,samples_per_gpu=1 相当于总batch size=1,那这个地方lr= 0.02/16 = 0.00125
# 如果你是单卡,samples_per_gpu=2 相当于总batch size=2, 那这个地方lr= 0.02/4 = 0.005
#...依此类推
optimizer = dict(type='SGD', lr=0.02, momentum=0.9, weight_decay=0.0001)
# 5、使用预训练的Mask RCNN model来获取更高的精度(从github上clone下来的项目里面是没有checkpoints文文件夹的,需要自己创建以及下载相应的预训练文件,详情请看我下面的步骤)
load_from = 'checkpoints/mask_rcnn_r50_caffe_fpn_mstrain-poly_3x_coco_bbox_mAP-0.408__segm_mAP-0.37_20200504_163245-42aa3d00.pth'上面进行继承py文件,后面重写就会对其相关属性重写、覆盖。
(4)实际还可以通过work_dir下生成的py文件,稍加修改作为未来训练的配置文件!
我自己训练文件夹产生的配置文件/home/wt-yjy/project/code/mmdetection/work_dirs/maskrcnn_x101_64d/maskrcnn_tianma.py如下:
model = dict(
type='MaskRCNN',
backbone=dict(
type='ResNeXt',
depth=101,
num_stages=4,
out_indices=(0, 1, 2, 3),
frozen_stages=1,
norm_cfg=dict(type='BN', requires_grad=True),
norm_eval=True,
style='pytorch',
init_cfg=dict(
type='Pretrained', checkpoint='open-mmlab://resnext101_64x4d'),
groups=64,
base_width=4),
neck=dict(
type='FPN',
in_channels=[256, 512, 1024, 2048],
out_channels=256,
num_outs=5),
rpn_head=dict(
type='RPNHead',
in_channels=256,
feat_channels=256,
anchor_generator=dict(
type='AnchorGenerator',
scales=[8],
ratios=[0.5, 1.0, 2.0],
strides=[4, 8, 16, 32, 64]),
bbox_coder=dict(
type='DeltaXYWHBBoxCoder',
target_means=[0.0, 0.0, 0.0, 0.0],
target_stds=[1.0, 1.0, 1.0, 1.0]),
loss_cls=dict(
type='CrossEntropyLoss', use_sigmoid=True, loss_weight=1.0),
loss_bbox=dict(type='L1Loss', loss_weight=1.0)),
roi_head=dict(
type='StandardRoIHead',
bbox_roi_extractor=dict(
type='SingleRoIExtractor',
roi_layer=dict(type='RoIAlign', output_size=7, sampling_ratio=0),
out_channels=256,
featmap_strides=[4, 8, 16, 32]),
bbox_head=dict(
type='Shared2FCBBoxHead',
in_channels=256,
fc_out_channels=1024,
roi_feat_size=7,
num_classes=31,
bbox_coder=dict(
type='DeltaXYWHBBoxCoder',
target_means=[0.0, 0.0, 0.0, 0.0],
target_stds=[0.1, 0.1, 0.2, 0.2]),
reg_class_agnostic=False,
loss_cls=dict(
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0),
loss_bbox=dict(type='L1Loss', loss_weight=1.0)),
mask_roi_extractor=dict(
type='SingleRoIExtractor',
roi_layer=dict(type='RoIAlign', output_size=14, sampling_ratio=0),
out_channels=256,
featmap_strides=[4, 8, 16, 32]),
mask_head=dict(
type='FCNMaskHead',
num_convs=4,
in_channels=256,
conv_out_channels=256,
num_classes=31,
loss_mask=dict(
type='CrossEntropyLoss', use_mask=True, loss_weight=1.0))),
train_cfg=dict(
rpn=dict(
assigner=dict(
type='MaxIoUAssigner',
pos_iou_thr=0.7,
neg_iou_thr=0.3,
min_pos_iou=0.3,
match_low_quality=True,
ignore_iof_thr=-1),
sampler=dict(
type='RandomSampler',
num=256,
pos_fraction=0.5,
neg_pos_ub=-1,
add_gt_as_proposals=False),
allowed_border=-1,
pos_weight=-1,
debug=False),
rpn_proposal=dict(
nms_pre=2000,
max_per_img=1000,
nms=dict(type='nms', iou_threshold=0.7),
min_bbox_size=0),
rcnn=dict(
assigner=dict(
type='MaxIoUAssigner',
pos_iou_thr=0.5,
neg_iou_thr=0.5,
min_pos_iou=0.5,
match_low_quality=True,
ignore_iof_thr=-1),
sampler=dict(
type='RandomSampler',
num=512,
pos_fraction=0.25,
neg_pos_ub=-1,
add_gt_as_proposals=True),
mask_size=28,
pos_weight=-1,
debug=False)),
test_cfg=dict(
rpn=dict(
nms_pre=1000,
max_per_img=1000,
nms=dict(type='nms', iou_threshold=0.7),
min_bbox_size=0),
rcnn=dict(
score_thr=0.05,
nms=dict(type='nms', iou_threshold=0.5),
max_per_img=100,
mask_thr_binary=0.5)))
dataset_type = 'CocoDataset'
data_root = '/home/wt-yjy/project/code/mmdetection/custom_configs/dataset_root/tianma_dataset/timama_0616/'
img_norm_cfg = dict(
mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
train_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='LoadAnnotations', with_bbox=True, with_mask=True),
dict(type='Resize', img_scale=(1333, 800), keep_ratio=True),
dict(type='RandomFlip', flip_ratio=0.5),
dict(
type='Normalize',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
to_rgb=True),
dict(type='Pad', size_divisor=32),
dict(type='DefaultFormatBundle'),
dict(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels', 'gt_masks'])
]
test_pipeline = [
dict(type='LoadImageFromFile'),
dict(
type='MultiScaleFlipAug',
img_scale=(1333, 800),
flip=False,
transforms=[
dict(type='Resize', keep_ratio=True),
dict(type='RandomFlip'),
dict(
type='Normalize',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
to_rgb=True),
dict(type='Pad', size_divisor=32),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img'])
])
]
data = dict(
samples_per_gpu=2,
workers_per_gpu=2,
train=dict(
type='CocoDataset',
ann_file=
'/home/wt-yjy/project/code/mmdetection/custom_configs/dataset_root/tianma_dataset/timama_0616/annotations/instances_train2017.json',
img_prefix=
'/home/wt-yjy/project/code/mmdetection/custom_configs/dataset_root/tianma_dataset/timama_0616/train2017/',
pipeline=[
dict(type='LoadImageFromFile'),
dict(type='LoadAnnotations', with_bbox=True, with_mask=True),
dict(type='Resize', img_scale=(1333, 800), keep_ratio=True),
dict(type='RandomFlip', flip_ratio=0.5),
dict(
type='Normalize',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
to_rgb=True),
dict(type='Pad', size_divisor=32),
dict(type='DefaultFormatBundle'),
dict(
type='Collect',
keys=['img', 'gt_bboxes', 'gt_labels', 'gt_masks'])
]),
val=dict(
type='CocoDataset',
ann_file=
'/home/wt-yjy/project/code/mmdetection/custom_configs/dataset_root/tianma_dataset/timama_0616/annotations/instances_val2017.json',
img_prefix=
'/home/wt-yjy/project/code/mmdetection/custom_configs/dataset_root/tianma_dataset/timama_0616/val2017/',
pipeline=[
dict(type='LoadImageFromFile'),
dict(
type='MultiScaleFlipAug',
img_scale=(1333, 800),
flip=False,
transforms=[
dict(type='Resize', keep_ratio=True),
dict(type='RandomFlip'),
dict(
type='Normalize',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
to_rgb=True),
dict(type='Pad', size_divisor=32),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img'])
])
]),
test=dict(
type='CocoDataset',
ann_file=
'/home/wt-yjy/project/code/mmdetection/custom_configs/dataset_root/tianma_dataset/timama_0616/annotations/instances_val2017.json',
img_prefix=
'/home/wt-yjy/project/code/mmdetection/custom_configs/dataset_root/tianma_dataset/timama_0616/val2017/',
pipeline=[
dict(type='LoadImageFromFile'),
dict(
type='MultiScaleFlipAug',
img_scale=(1333, 800),
flip=False,
transforms=[
dict(type='Resize', keep_ratio=True),
dict(type='RandomFlip'),
dict(
type='Normalize',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
to_rgb=True),
dict(type='Pad', size_divisor=32),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img'])
])
]))
evaluation = dict(metric=['bbox', 'segm'])
optimizer = dict(type='SGD', lr=0.002, momentum=0.9, weight_decay=0.0001)
optimizer_config = dict(grad_clip=None)
lr_config = dict(
policy='step',
warmup='linear',
warmup_iters=500,
warmup_ratio=0.001,
step=[5, 8, 11, 14, 17, 20])
runner = dict(type='EpochBasedRunner', max_epochs=24)
checkpoint_config = dict(interval=1)
log_config = dict(interval=50, hooks=[dict(type='TextLoggerHook')])
custom_hooks = [dict(type='NumClassCheckHook')]
dist_params = dict(backend='nccl')
log_level = 'INFO'
load_from = 'checkpoints/mask_rcnn_x101_64x4d_fpn_2x_coco.pth'
resume_from = None
workflow = [('train', 1)]
opencv_num_threads = 0
mp_start_method = 'fork'
auto_scale_lr = dict(enable=False, base_batch_size=16)
work_dir = 'work_dirs/'
auto_resume = False
gpu_ids = [0]我们可以使用上面这个文件,直接作为配置文件进行训练!
4.2
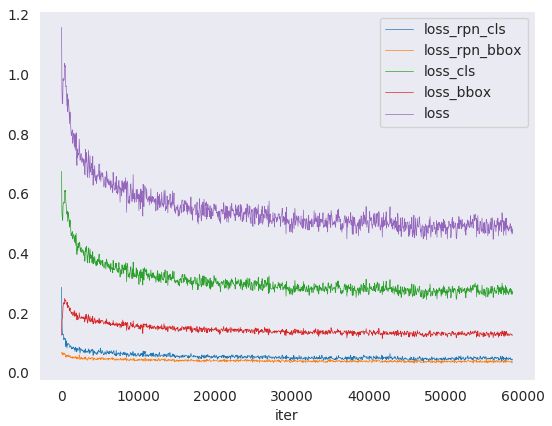
使用tools/analysis_tools/analyze_logs.py文件对一些数据plot,其中包括loss_rpn_cls、loss_rpn_bbox、loss_cls、loss_bbox以及loss
4.3 多GPU分布式训练和单GPU训练
# single-gpu training
python tools/train.py \
configs/faster_rcnn/faster_rcnn_r50_fpn_1x_coco.py \
--work-dir _train
# multi-gpu training
bash ./tools/dist_train.sh \
configs/faster_rcnn/faster_rcnn_r50_fpn_1x_coco.py \
2 \
--work-dir _train
4.4 预训练模型文件加载用于训练
init_cfg=dict(
type='Pretrained', checkpoint='open-mmlab://resnext101_64x4d')
可以将checkpoint='open-mmlab://resnext101_64x4d'这个直接换掉为我们指定路径下面的权重文件,从而作为预训练模型文件!!!
当然我们直接在配置文件后面写的load_from也可以。
4.5 测试(test是测试带有标注信息的文件,不是inference无标注图片)时保存pkl还是json
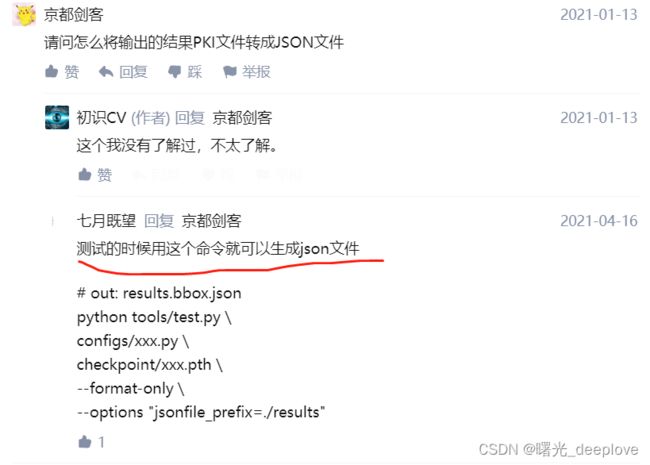
4.6 mmdetection中的图片输入大小解析
mmdetection中的图片输入大小解析 - 知乎 (zhihu.com)



4.7 混合精度训练
引自:入门mmdetection(捌)---聊一聊FP16 - 知乎 (zhihu.com)
训了个目标检测网络mAP不高呀,我说你换个backbone呗。第二天,他跑来说,哎呀,我换了个ResneXt,涨点了,但是觉得还不够好;我说,你把图像放大输进去呗;第三天,他跑来说,哎呀,cuda out of memory了,这时候,就该祭出神器FP16了。
基于FP16的混合精度训练在mmdetection中的实现(由于很多大神对FP16已经有入门的介绍了,我这里就不再浪费时间重复一遍,见参考文献即可)。
在mmdetection中,使用FP16非常方便,只需要在config里添加一行即可:
# loss_scale你可以自己指定,几百到1000比较合适,这里取512
fp16 = dict(loss_scale=512.)加了上面这一行训练的时候就可以用了(当然前提是你的gpu得支持才行)。接下来我们来看mmdetection是怎么读取这个配置的,以下代码是从train.py里_non_dist_train这个函数截取的:
# 从config里读取fp16字段,如果没有为None;
fp16_cfg = cfg.get('fp16', None)
if fp16_cfg is not None:
# 如果我们设置了,则会生成一个Fp16OptimizerHook的实例
optimizer_config = Fp16OptimizerHook(
**cfg.optimizer_config, **fp16_cfg, distributed=False)
else:
# 如果我们没有设置,则正常从config里面读取optimizer_config
# 如设置grad_clip: optimizer_config = dict(grad_clip=dict(max_norm=35, norm_type=2))
optimizer_config = cfg.optimizer_config
# 然后注册训练的hooks,optimizer_config会被当参数传进去
runner.register_training_hooks(cfg.lr_config, optimizer_config,
cfg.checkpoint_config, cfg.log_config)我们来看下runner(在mmcv工程里)的register_training_hooks这个函数:
def register_training_hooks(self,lr_config, optimizer_config=None,
checkpoint_config=None,log_config=None):
self.register_lr_hook(lr_config)
# 这里注册传进来的optimizer_config,其他hook不需要关注
self.register_optimizer_hook(optimizer_config)
self.register_checkpoint_hook(checkpoint_config)
self.register_hook(IterTimerHook())
self.register_logger_hooks(log_config)
def register_optimizer_hook(self, optimizer_config):
if optimizer_config is None:
return
# 如果是dict,则生成OptimizerHook的实例,这个第六章我已经讲过了,就是正常的反传和更新参数
if isinstance(optimizer_config, dict):
optimizer_config.setdefault('type', 'OptimizerHook')
hook = mmcv.build_from_cfg(optimizer_config, HOOKS)
# 如果不是dict,那就是我们之前传进来的Fp16OptimizerHook的实例了
else:
hook = optimizer_config
# 注册这个hook,就是添加到hook_list里,待训练的时候某个指定时间节点使用
self.register_hook(hook)所以接下来就轮到Fp16OptimizerHook的代码了,这里是实现的核心所在。在看这段代码之前我们梳理一下我们大概要做的和需要理解的事情。
(1) 我们需要拷贝一份FP32的权重用来更新。为什么呢?我们把模型半精度化了,这样权重和梯度都是用FP16保存的,大大节省了显存。但是问题出在更新权重的时候,学习率和梯度的乘积这个数值一般会很小,如果这个这个数比FP16的极限表达能力还小,那么就会被舍弃掉,这次计算就白算了,所以我们想用FP32来计算step操作。
(2) 我们需要把loss放大(这也是我们在config里面需要指定的scale)。为什么呢?(1)里面讲过虽然我们更新已经用FP32来计算了,但是存储仍然还是用的FP16的。如果梯度很小(这个由于激活函数的存在其实是非常常见的),那么FP16的比特数根本不足以表达到这么精确,梯度就都变成0了。所以把loss放大,梯度也会跟着放大,即可用FP16存储了。
(3) pytorch中权重存储在model中,可以通过parameters()获取(包含weight和bias)。optimizer为了用来更新权重,所以“复制”了一份权重在optimizer类的成员变量param_groups里(这里其实不能说是复制,因为他们其实是同一份内存地址,改了一个另外一个也跟着改)。按照前面两点说的,我们用FP16来存储,肯定是存在model里;用FP32来更新,肯定是更新在optimizer里,更新完再往model里拷贝。所以我们将两者解耦,即深拷贝一份。有人会问,这深拷贝了不是额外的内存么,怎么还说能节省显存呢?其实权重的内存和特征图比微不足道,特征图都是FP16进行存储的,省下的远远大于这点额外开销。
class Fp16OptimizerHook(OptimizerHook):
def __init__(self,
grad_clip=None,
coalesce=True,
bucket_size_mb=-1,
loss_scale=512.,
distributed=True):
self.grad_clip = grad_clip
self.coalesce = coalesce
self.bucket_size_mb = bucket_size_mb
self.loss_scale = loss_scale
self.distributed = distributed
def before_run(self, runner):
# 这里param_groups是pytorch里optimizer的成员变量,
# 它是一个dict,包含了权重(以'params'为键),学习率、momentum、weight_decay等信息
# 其中权重本来是和model里面的权重同一块内存,可以用id()验证,
# 做了这个deepcopy之后optimizer里面的权重就和model里面的权重解耦了。
# 所以这里就是训练之前在optimizer里拷贝一份FP32的权重,因为之前说了更新要用
runner.optimizer.param_groups = copy.deepcopy(
runner.optimizer.param_groups)
# 然后把模型的权重都转为FP16(wrap_fp16_model函数里主要是执行model.half()这句)
wrap_fp16_model(runner.model)
# 这个函数就这么简单,就是在model里存的是FP16的权重,optimizer里是FP32的权重
# 这个函数是forward完了后调用,为了算梯度和更新参数
def after_train_iter(self, runner):
# 首先把之前的梯度清零,注意before_run里已经将model里的权重和optimizer里的权重解耦
# 所以这里要分别做梯度清零
runner.model.zero_grad()
runner.optimizer.zero_grad()
# 这里就是上面我们讲的把loss放大,乘一个loss_scale(你来设置)
# 由于链式法则,之后的梯度也会有这个因子
scaled_loss = runner.outputs['loss'] * self.loss_scale
# 由于模型已经half了,所以这里算梯度都是FP16存储的
# 而且因为乘了scale,所以FP16足够存储
scaled_loss.backward()
fp32_weights = []
for param_group in runner.optimizer.param_groups:
fp32_weights += param_group['params']
# 拷贝FP16的梯度的数值进FP32的梯度的数值里,供后面更新用
# 此刻optimizer里面的网络即将更新的权重和算出来的梯度都是FP32了
self.copy_grads_to_fp32(runner.model, fp32_weights)
# 这里如果是分布式训练,要做reduce操作,不是我们的关注对象先不看
if self.distributed:
allreduce_grads(fp32_weights, self.coalesce, self.bucket_size_mb)
# 因为已经梯度的数值已经是用FP32存储了,所以可以scale回去,精度也足够表达
for param in fp32_weights:
if param.grad is not None:
param.grad.div_(self.loss_scale)
if self.grad_clip is not None:
self.clip_grads(fp32_weights)
# optimizer更新参数,以FP32进行计算
runner.optimizer.step()
# 算完之后把optimizer里面的数值拷贝到model里,以FP16进行存储
self.copy_params_to_fp16(runner.model, fp32_weights)
def copy_grads_to_fp32(self, fp16_net, fp32_weights):
"""Copy gradients from fp16 model to fp32 weight copy."""
for fp32_param, fp16_param in zip(fp32_weights, fp16_net.parameters()):
if fp16_param.grad is not None:
if fp32_param.grad is None:
fp32_param.grad = fp32_param.data.new(fp32_param.size())
fp32_param.grad.copy_(fp16_param.grad)
def copy_params_to_fp16(self, fp16_net, fp32_weights):
"""Copy updated params from fp32 weight copy to fp16 model."""
for fp16_param, fp32_param in zip(fp16_net.parameters(), fp32_weights):
fp16_param.data.copy_(fp32_param.data)参考文献:
Micikevicius, Paulius, Narang, Sharan, Alben, Jonah,等. Mixed Precision Training[J].
Dreaming.O:浅谈混合精度训练
Nicolas:【PyTorch】唯快不破:基于Apex的混合精度加速