使用 Sklearn 构建随机森林的最简单代码及调参说明
使用 Sklearn 构建随机森林的最简单代码及调参说明
#废话不多说,直接上代码!
#重要的部分有注释,所有的参数都有参数说明,可以直接运行,适合小白。
#未经许可,禁止转载。
#转自本人知乎https://zhuanlan.zhihu.com/p/279729932
#1、最简代码
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_wine
#使用sklearn自带的红酒数据集
wine = load_wine() #数据集加载
Xtrain, Xtest, Ytrain, Ytest = train_test_split(wine.data,wine.target,test_size=0.3) #划分训练集和验证集
#构建模型
rfc = RandomForestClassifier(n_estimators=20) #森林中树木的数量,即基评估器的数量先随便给个20,需要进一步调参来确定最优值
#打分
score_r1 = rfc.score(Xtrain,Ytrain)
score_r2 = rfc.score(Xtest,Ytest)
-----------------------------------------------------------------------------------------------
#2、选学:调整参数
#在随机森林中最重要的参数就是n_estimators、max_depth
#分别代表森林中树的数量、树的最大深度
其他的参数对随机森林的影响不大,一般不会特意去调。
#2.1 调整参数n_estimators
scores = []
for i in range(0,200,10):
rfc = RandomForestClassifier(n_estimators=i+1)
score1 = cross_val_score(rfc,data.data,data.target,cv=10).mean() #交叉验证得平均分
scores .append(score1)
print(max(scores ),(scores .index(max(scores))*10)+1) #打印最高分数,及其索引
plt.figure(figsize=[20,5])
plt.plot(range(1,201,10),scores)
plt.show()
#结果:
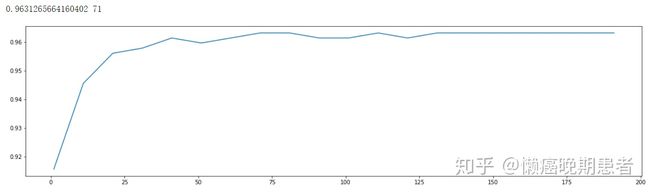
#可以得到最优值在71左右
#在71左右,进一步细化学习曲线
scores = []
for i in range(65,75):
rfc = RandomForestClassifier(n_estimators=i+1)
score1 = cross_val_score(rfc,data.data,data.target,cv=10).mean() #交叉验证得平均分
scores .append(score1)
print(max(scores ),(scores .index(max(scores))*10)+1) #打印最高分数,及其索引
plt.figure(figsize=[20,5])
plt.plot(range(1,201,10),scores)
plt.show()
#结果:
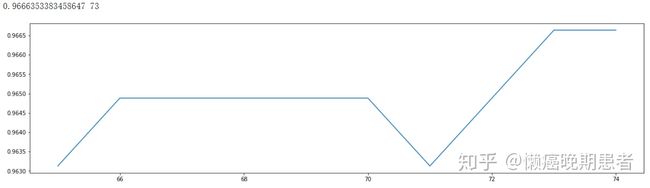
#得到最优:n_estimators=73
#2.2 调整参数max_depth
#网格搜索:按照参数对模型整体准确率的影响程度进行调参
param_grid = {'max_depth':np.arange(1, 20, 1)}
rfc = RandomForestClassifier(n_estimators=73)
#网格搜索模型,参数1:随机森林模型;参数2:待调整的参数;参数3:交叉验证的次数
GS1 = GridSearchCV(rfc,param_grid,cv=10)
GS1.fit(data.data,data.target)
print("最佳参数:")
print(GS1.best_params_)
print("参数得分:")
print(GS1.best_score_)
#结果:
