基于生成式回放的流式图神经网络模型
丨目录:
· 摘要
· 背景
· 方法
· 实验
· 总结与展望
· 参考文献
1. 摘要
近些年来图神经网络模型在图数据的不同任务上取得了很大进展。然而真实世界的图数据往往是以流式形式存在的,已有一些方法对图神经网络模型进行更新,比如说在每个时间片上对全图进行重新训练,但是会导致很高的计算复杂度;而传统在线学习方法则会导致灾难性遗忘的发生,使得模型无法在全图上有无损的效果。在本文中,我们提出了一种在流式场景下高效地训练图神经网络模型的全新框架,通过一个额外的图生成模型来保存完整的历史分布,使得在图不断变化时模型可以同时学习图中出现的新模式并且巩固已有知识。
该项工作由阿里妈妈搜索广告算法团队和北京大学宋国杰副教授课题组合作完成,基于该项工作整理的论文已发表在 KDD 2022,欢迎阅读交流。
论文: Streaming Graph Neural Networks via Generative Replay
链接: https://dl.acm.org/doi/abs/10.1145/3534678.3539336
2. 背景
图是一种在现实世界中是非常重要的数据结构,比如电商网络、社交网络等。为了挖掘真实图数据中的各种信息,图神经网络模型(Graph neural networks,GNNs)在近年来被广泛研究 [1],它通过聚集邻居信息来得到表示向量,在不同应用场景中都取得了优异效果。但是现有和GNN模型相关的工作主要探讨在静态场景下的学习,即模型在一次训练之后不会再被更新。
然而真实世界的图数据往往是以流式形式存在的,也就是图结构会随时间发生变化,比如在以User、Query、Item构成的电商网络中,每天都有新User和Item加入导致图中不断出现新节点,同时用户每天的点击、购买等行为都是不同的,从而导致图中的连边和边权会不断更新。为了得到实时的节点表示向量,GNN模型进行高效更新是相当有必要的。
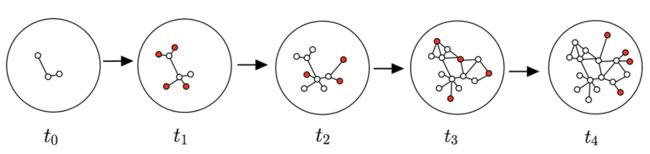 图1
图1
已有一些简单的对GNN模型进行更新的方法,例如可以在每个时间片对全图进行重新训练,但会面临很高的计算复杂度,或者采用传统的在线学习的方法,但会导致灾难性遗忘(当模型学习新模式时忘记了历史学习到的知识),使得模型无法在全图上有好的效果。最近,连续学习(Continual learning)作为一种序列化学习的方法被广泛研究 [2],已有一些基于连续学习的GNN模型来解决流式场景下的图学习问题,能使得GNN模型同时学习图中的新知识和保持旧知识。其中,ContinualGNN [3] 、ER-GNN [4] 、TWP [5] 等分别采用基于正则化和经验回放的方法来解决灾难性遗忘问题,但是基于正则项的方法往往难以得到令人满意的最优解,而经验式回放的方法通过保存部分节点来避免遗忘,往往遭遇空间开销大和难以刻画和更新完整的数据分布的问题。
为了解决上述问题,我们提出一种全新的生成式回放方法来高效地训练流式GNN模型,模型不需要保存和访问额外数据就可以有效地保持历史图数据分布,从而避免灾难性遗忘问题。
3. 方法
3.1 模型框架
我们提出了一种在流式场景下高效训练GNN模型的全新框架,使得图发生变化时,可以同时学习出现的新模式,并且巩固已有知识。模型由两个部分组成:一个GNN主模型和一个辅助的图生成模型,模型的训练也包含了训练主模型和图生成器两个互相独立的过程(如图2所示)。
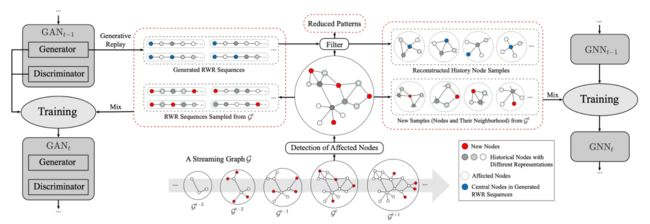 图2
图2
图生成模型: 在每个时刻,一个新的生成器接收中的新节点和历史图中的回放节点作为训练数据,其中历史网络的回放节点是从上一时刻的生成器生成的。基于GAN框架,图生成模型由一个生成器和一个判别器构成,通过二者的对抗训练使得生成器挖掘当前图数据的真实分布,从而能够生成与真实节点接近的仿真节点。因此图生成模型的优化目标如下:
GNN主模型: 一个新的GNN模型同样按照的比例融合变化节点和回放节点作为输入,注意到回放节点的标签则是由上一时刻的 GNN 模型得到,该软标签(即概率形式)可以为模型的训练提供更多信息。因此主模型的优化目标为:
总体而言,该生成式框架和已有的流式GNN相比有两个好处。第一,不需要重新历史图数据就可以保存完整的图数据分布,即通过生成器可以产生大量的历史伪造数据。第二,保存完整的数据分布有助于对分布的实时更新,尤其是在新增节点会对图中的其他节点造成影响的情况下,给定完整的数据分布可以更好地对行刻画。
3.2 图生成模型
我们训练一个生成模型来学习历史图数据的分布,它能生成伪造的历史节点(包含节点及其邻域信息),从而在每个时间片生成的仿真样本会和真实样本一起用于模型的增量更新,使得模型不再需要重新访问历史数据。但是生成模型主要在计算机视觉领域发展,在图领域遇到了困难,一些已有的图上的生成模型(比如NetGAN和GraphRNN)更关注生成全图的拓扑结构,而不是每个节点的邻域信息。
首先,我们将对中心网络(Ego network)的学习转换为对中心化随机游走(Random walks with restart,RWRs)的学习,并提出一个理论框架,通过分析随机游走序列遍历节点中心网络的期望步长,来证明RWRs对节点中心网络的表达能力(定理以及详细证明过程见论文)。
基于上述理论基础,我们基于对抗生成网络(Generative adversarial network,GAN)框架设计了对于节点中心网络的生成模型。
生成器负责生成仿真的随机游走序列,使得其分布和图上的真实游走序列尽可能接近。为了使生成器可以捕获游走序列中节点之间的依赖关系,我们利用 GRU对生成过程进行建模,其核心是保存一个图状态。给定上一个图状态和上一个输入(输入包含节点编号和节点属性),通过神经网络得到当前的图状态,然后再通过参数将状态上映射到和空间,生成下一个节点和它对应属性,具体更新形式如下:
判别器则去学习如何区别仿真的游走序列和从真实的中心网络上得到的游走序列。它通过一个神经网络输出该游走序列的分数,从而判断该游走序列是否是真实的:
3.3 图增量学习
在流式场景下,图数据的分布不断发生变化,需要对生成模型和主模型都进行相应的更新。对全图进行重新学习又是不可实现的;而只基于变化部分的新模式进行更新是不足的,因为图中任何部分的变化都是有可能影响到其他节点。一方面导致相关联的节点出现了一些新模式,另一方面导致旧模式消失。
为了使得生成模型能适应最新的图分布,我们设计了图的增量学习方式,它能对图中的新兴模式进行增量学习的同时,同时能对消亡模式也进行相应更新。具体而言,我们首先将节点邻域模式的变化量定义为相邻两个时间片上表示向量的变化量,基于此检测出受到图变化的影响而导致邻域模式发生偏移的节点。对于这些节点,它们将融入当前的训练数据,使得当前生成模型和当前 GNN 模型增量地学习到新模式。而另一方面,当一些变化节点转换为其他模式时,原有模式消失,生成模型不应该继续生成这种冗余模式。为了针对这种情况来对生成模型进行更新,我们设计了针对对伪造节点的过滤方法,间接地使得冗余模式不再参与训练并被不断被遗忘。
4. 实验
我们在四个开源数据集上进行实验以证明我们模型的有效性,总体的实验效果如表1和图3所示。
首先,从模型效果上看,我们的模型(SGNN-GR)的效果远好于已有的增量训练方法,实现了和模型上界(RetrainedSAGE)相当的表现。其次,SGNN-GR比模型上界(RetrainedSAGE)要更高效,平均每一轮的迭代时间快了 3-6 倍,总的运行时间(包括了生成器的训练时间)也快了 1.5-2 倍。
也就是说RetrainedGNN虽然效果好,但是训练复杂度过高,无法在真实的大规模网络上应用。而我们的模型是以增量方式进行训练的,在保持高效迭代的同时,通过额外学习一个设计精巧的生成模型避免了传统增量学习遇到的灾难性遗忘,因此给真实流式场景的应用 提高了一种很好的选择。
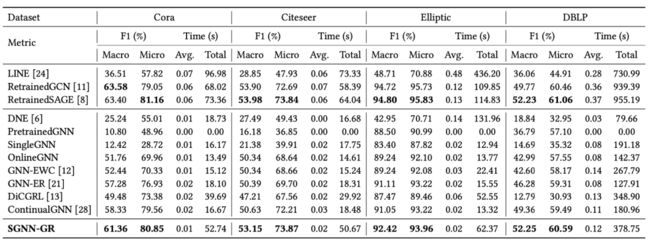 表1
表1 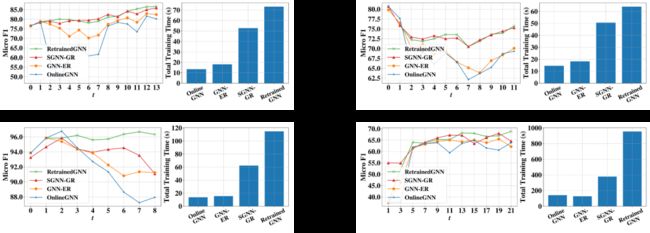 图3
图3
5. 总结与展望
本文主要研究了 GNN 模型在流式场景下的增量学习问题。我们结合连续学习方法,提出了一种基于生成式回放的流式图神经网络框架,能够高效地学习图中的新模式并巩固已有模式。我们在四个真实数据集上展开实验,结果证明了模型的有效性,并通过进一步的分析,证明了生成模型对图数据的表达能力。
尽管本文提出的方法已经在实验中被论证取得了不错的预测效果,但是在流式图神经网络领域未来仍存在更多可能的研究方向,比如连续图神经网络的模型自适应扩张方法、无监督场景下的连续图神经网络方法、连续图神经网络模型的可解释性问题等。
参考文献
[1] Will Hamilton, Zhitao Ying, and Jure Leskovec. 2017. Inductive representation learning on large graphs. In Advances in Neural Information Processing Systems. 1025–1035.
[2] James Kirkpatrick, Razvan Pascanu, Neil Rabinowitz, Joel Veness, Guillaume Desjardins, Andrei A Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszka Grabska-Barwinska, et al. 2017. Overcoming catastrophic forgetting in neural networks. Proceedings of the national academy of sciences 114, 13 (2017), 3521– 3526.
[3] Junshan Wang, Guojie Song, Yi Wu, and Liang Wang. 2020. Streaming Graph Neu- ral Networks via Continual Learning. In Proceedings of the 29th ACM International Conference on Information & Knowledge Management. 1515–15.
[4] Fan Zhou and Chengtai Cao. 2021. Overcoming Catastrophic Forgetting in Graph Neural Networks with Experience Replay. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 35. 4714–4722.
[5] Huihui Liu, Yiding Yang, and Xinchao Wang. 2021. Overcoming Catastrophic Forgetting in Graph Neural Networks. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 35. 8653–8661.
END

也许你还想看
丨图深度学习模型进展和在阿里搜索广告中的应用创新
丨基于对抗梯度的探索模型及其在点击预估中的应用
丨KDD'22 | CausalMTA: 基于因果推断的无偏广告多触点归因技术
丨KDD2022 | MUVCOG:多模态搜索会话下的用户意图刻画
丨SIGIR 2021 | PCF-GNN:基于预训练图神经网络的显式交叉语义建模方案


喜欢要“分享”,好看要“点赞”哦ღ~
↓欢迎留言参与讨论↓