pytorch实现Cosine learning rate& warmup step decay(代码&plot图都已注释,方便调试拷贝)
Cosine learning rate decay
学习率不断衰减是一个提高精度的好方法。其中有step decay和cosine decay等,前者是随着epoch增大学习率不断减去一个小的数,后者是让学习率随着训练过程曲线下降。
对于cosine decay,假设总共有T个batch(不考虑warmup阶段),在第t个batch时,学习率η_t为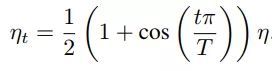
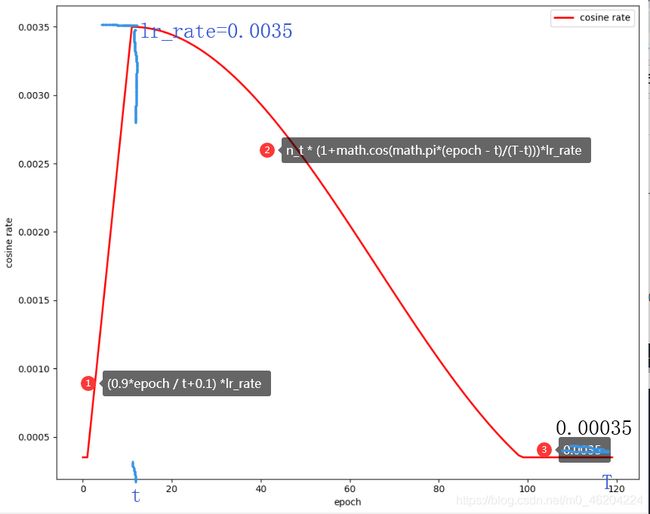
注意:
- 图中的lr是lambda1*lr_rate的结果
- 便于工程上的运用,起始学习率=0.00035,尾端防止学习率为0,当lr小于0.00035时,也设成0.00035
lambda1 = lambda epoch: (0.9*epoch / t+0.1) if epoch < t else 0.1 if n_t * (1+math.cos(math.pi*(epoch - t)/(T-t)))<0.1 else n_t * (1+math.cos(math.pi*(epoch - t)/(T-t)))
# -*- coding:utf-8 -*-
import math
import matplotlib.pyplot as plt
import torch.optim as optim
from torchvision.models import resnet18
t=10#warmup
T=120#共有120个epoch,则用于cosine rate的一共有110个epoch
lr_rate = 0.0035
n_t=0.5
model = resnet18(num_classes=10)
lambda1 = lambda epoch: (0.9*epoch / t+0.1) if epoch < t else 0.1 if n_t * (1+math.cos(math.pi*(epoch - t)/(T-t)))<0.1 else n_t * (1+math.cos(math.pi*(epoch - t)/(T-t)))
optimizer = optim.SGD(model.parameters(), lr=lr_rate, momentum=0.9, nesterov=True)
scheduler = optim.lr_scheduler.LambdaLR(optimizer, lr_lambda=lambda1)
index = 0
x = []
y = []
for epoch in range(T):
x.append(index)
y.append(optimizer.param_groups[0]['lr'])
index += 1
scheduler.step()
plt.figure(figsize=(10, 8))
plt.xlabel('epoch')
plt.ylabel('cosine rate')
plt.plot(x, y, color='r', linewidth=2.0, label='cosine rate')
plt.legend(loc='best')
plt.show()
warmup step decay


# -*- coding:utf-8 -*-
"""
在build_optimizer.py中可查看学习率的模样
学习率控制,主要设置在于lr_sheduler.py,这个WarmupMultiStepLR需要传入一个optimizer,目的为了获取optimizer的base_lr
"""
from bisect import bisect_right
import torch
import matplotlib.pyplot as plt
import numpy as np
"""
args:
milestones:在多少个epoch时进行一次衰减
gamma:衰减1/10
last_epoch=-1:从第0个epoch开始,在for循环中是0,1,2,3变动的
"""
class WarmupMultiStepLR(torch.optim.lr_scheduler._LRScheduler):
def __init__(
self,
optimizer,
milestones, # [40,70]
gamma=0.1, #
warmup_factor=0.01,
warmup_iters=10,
warmup_method="linear",
last_epoch=-1,
):
if not list(milestones) == sorted(milestones): # 保证输入的list是按前后顺序放的
raise ValueError(
"Milestones should be a list of" " increasing integers. Got {}",
milestones,
)
if warmup_method not in ("constant", "linear"):
raise ValueError(
"Only 'constant' or 'linear' warmup_method accepted",
" but got {}".format(warmup_method)
)
self.milestones = milestones
self.gamma = gamma
self.warmup_factor = warmup_factor
self.warmup_iters = warmup_iters
self.warmup_method = warmup_method
super(WarmupMultiStepLR, self).__init__(optimizer, last_epoch)
'''
self.last_epoch是一直变动的[0,1,2,3,,,50]
self.warmup_iters=10固定(表示线性warm up提升10个epoch)
'''
def get_lr(self):
warmup_factor = 1
list = {}
if self.last_epoch < self.warmup_iters: # 0<10
if self.warmup_method == "constant":
warmup_factor = self.warmup_factor # 1/3
elif self.warmup_method == "linear":
alpha = self.last_epoch / self.warmup_iters # self.last_epoch是一直变动的[0,1,2,3,,,50]/10
warmup_factor = self.warmup_factor * (1 - alpha) + alpha # self.warmup_factor=1/3
list = {"last_epoch": self.last_epoch, "warmup_iters": self.warmup_iters, "alpha": alpha,
'warmup_factor': warmup_factor}
# print(base_lr for base_lr in self.base_lrs)
# print(base_lr* warmup_factor* self.gamma ** bisect_right(self.milestones, self.last_epoch) for base_lr in self.base_lrs)
return [base_lr * warmup_factor * self.gamma ** bisect_right(self.milestones, self.last_epoch) for base_lr in
self.base_lrs] # self.base_lrs,optimizer初始学习率weight_lr=0.0003,bias_lr=0.0006
if __name__ == '__main__':
from torch import nn
import torch
import torch.optim as optim
from torchvision.models import resnet18
base_lrs=0.0035
model = resnet18(num_classes=10)
optimizer = optim.SGD(model.parameters(), lr=base_lrs, momentum=0.9, nesterov=True)
lr_scheduler = WarmupMultiStepLR(optimizer, [40, 70], warmup_iters=10, )
y = []
for epoch in range(120):
optimizer.zero_grad() # 优化器optimizer一遍,学习率也变一次
optimizer.step()
y.append(optimizer.param_groups[0]['lr'])
print('epoch:', epoch, 'lr:', optimizer.param_groups[0]['lr'])
lr_scheduler.step()
plt.plot(y, c='r', label='warmup step_lr', linewidth=1)
plt.legend(loc='best')
plt.xticks(np.arange(0, 120, 5))
plt.show()
两者性能对比
图(a)是学习率随epoch增大而下降的图,可以看出cosine decay比step decay更加平滑一点。图(b)是准确率随epoch的变化图,两者最终的准确率没有太大差别,不过cosine decay的学习过程更加平滑。至于哪个效果好,可能对于不同问题答案是不一样的,要具体实验。
