最新综述:自动驾驶中的多模态三维目标检测

©PaperWeekly 原创 · 作者 | 张一帆
学校 | 华南理工大学本科生
研究方向 | CV,Causality

Abstract
在过去几年,自动驾驶取得了蓬勃的发展,但是由于驾驶环境的复杂多变,实现完全自动依然是一个非常艰巨的任务。自动驾驶汽车往往配备了一系列复杂的传感器来进行准确、稳健的环境感知。这大量的类型不同的传感器如何互补,融合来促进感知依然是一个有待研究的问题。
本文致力于回顾最近的基于融合的 3D 检测深度学习模型,这些模型有一个共同的特点:多个传感器数据源,比如摄像机和激光雷达。本文首先介绍了各种常见传感器的背景和通用数据表示,以及针对每种传感器数据开发的目标检测网络。然后,本文讨论了一些用于多模态 3D 目标检测的流行数据集,特别关注数据集中的传感器数据。
接下来作者对近几年的多模态 3D 目标检测网络从三个方面进行了深入的调研:融合定位、融合数据表示和融合粒度。最后作者讨论了开放式挑战并指出了可能的解决方案。

论文标题:
Multi-Modal 3D Object Detection in Autonomous Driving: a Survey
论文作者:
Yingjie Wang, Qiuyu Mao, Hanqi Zhu, Yu Zhang, Jianmin Ji, Yanyong Zhang
论文链接:
https://arxiv.org/abs/2106.12735

Introduction
自动驾驶的普及有很多好处,但是由于现实场景中的感知性能还不够好,现阶段依然很难在城市或者其他复杂场景下部署。一个自动驾驶汽车要完成的感知任务是非常多的,比如定位,检测,对其他车/人移动的估计,对场景的理解(红绿灯),如下图所示,需要大量的传感器来完成这些功能。比如摄像机,LiDARs(光探测和测距传感器),Radar(无线电探测),GPS,IMUs(惯性测量装置)等。

在这大量的功能中,有三个功能最为重要:1)对环境的准确描述;2)在各种不同的恶劣环境中可以稳健运行;3)实时性。为了满足上述要求,感知子系统同时执行多个重要任务,如目标检测、跟踪、同步局部化和映射(SLAM)等。
2.1 3D Object Detection through Single Sensor Modality
物体检测即检测物体的位置与类别,2D 目标检测已经发展的很成熟了,但是 2D 并不能给自动驾驶提供足够的信息,只能标注一个框和类别的置信度。在 3D 物体检测任务中,需要更多的输出参数来指定物体周围的边界框。
如下图所示,我们需要预测物体的中心三维坐标 、长度、宽度、高度和偏转角度 ,从而绘制出红色的三维边界框。显然,由于缺乏真实世界坐标系统中的物体位置,二维物体检测不能满足自主驾驶环境感知的要求。本文主要研究自动驾驶的三维目标检测任务,根据传感器的使用类型,可以进一步分为以下几类。

2.1.1 3D Object Detection Using Cameras
虽然 camera 只能提供 2D 图像,但是很多研究工作直接用 2D 那套方法来预测三维信息,近期的研究表明基于图像的三维目标检测方法也可以在低成本下获得满意的性能。但是显然单个 image 是不可能提供可靠的空间信息的,而且单个摄像机很可能出现高遮挡,计算成本高等问题。此外,如图 4 所示,基于摄像头的感知子系统在不利条件下提供的 image 质量很差,如光线差或大雾天气,这限制了它们的全天候能力。

2.1.2 3D Object Detection Using LiDARs
更流行的方法是使用 LiDARs 提供的点云数据,不像图像,点云提供了丰富的三维空间信息。激光雷达的优势还在于其强大的测距能力和穿透能力,可以提供高质量的空间信息,而不存在目标遮挡问题。此外,激光雷达还能抵抗不利的照明条件。在激光雷达的帮助下,自动驾驶汽车可以看得更远、更清楚。
目前,基于 LiDARs 的方法比基于相机的方法获得了更好的检测精度和更高的查全率。比如在 KITTI 3D 数据集上,目前的 sota MonoFlex 如果输入 image 只能得到 mAP,但是如果输入点云数据能得到超过 80 的 mAP。
目前 LiDARs 还没有被自动驾驶广泛采用,主要原因如下:
激光雷达既昂贵又笨重,尤其是与照相机相比;
激光雷达捕获的点云分辨率较低(16~128通道),刷新率较低,不能满足实时检测的要求;
激光雷达的工作距离相当有限,远离激光雷达的点云非常稀疏;
激光雷达在极端恶劣的天气条件下不能正常工作,如大雨或大雪,因为激光的传输距离受到很大的影响。
2.1.3 3D Object Detection Using Other Sensors.
相比于相机和雷达,有一些传感器对环境更为鲁棒,比如毫米波雷达和红外摄像机。毫米波雷达通过多普勒效应来测量速度,提供对周围环境的远距离和精确测量。它们比激光雷达便宜很多,可以抵抗恶劣的天气条件,对照明变化也不敏感。
然而,与其他两种传感器相比,包含毫米波雷达数据的大规模公共数据集有限。此外,由于毫米波雷达的低分辨率和高高光性,很难获得上下文或感知信息,不能直接检测物体的形状。与激光雷达和相机相比,毫米波雷达识别物体的能力相对较差。
为了进一步填补夜间自动驾驶可靠解决方案的空白,红外摄像机已成为不可或缺的工具。红外摄像机采用红外热成像技术,不受夜间、反光表面、大雨等恶劣环境的影响。红外摄像机可以探测 300 米以外的物体。有了它们,司机有更多的时间对交通状况的突然变化做出反应,从而大大提高了驾驶安全。与价格高达数万美元的激光雷达传感器相比,红外摄像头还是比较划算的。
2.2 3D Object Detection through Multi-modal Fusion
在现实的自动驾驶情况下,通过单一类型的传感器进行目标检测是远远不够的。首先,每种传感器都有其固有的缺点。例如,只使用相机很可能遭受物体遮挡;与图像相比,激光雷达的输入数据分辨率较低,特别是在远距离时,这一问题阻碍了激光雷达的应用。
图 5 清楚地说明了两种情况。其次,要实现真正的自动驾驶,我们需要考虑广泛的天气、道路和交通条件。感知子系统必须在所有不同的条件下都能提供良好的感知结果,这是依靠单一类型的传感器难以实现的。例如进入隧道时,由于光线的突然变化,相机会出现曝光不足和过度曝光的问题。LiDAR 传感器也会受到雨天和大雾天气的影响。很明显,单传感器系统在不利条件下不能很好地工作

为了缓解这些问题,许多基于融合的三维检测方案已经被提出来了。在这些方法中,来自具有互补特性的多种类型传感器的数据被用来提高性能和降低成本。虽然传感器融合带来了好处,但进行高效的融合对底层系统设计提出了严峻的挑战。
本文接下来就来讨论这些挑战。一方面,不同类型的传感器在时间和空间上不同步;在时域上,由于不同传感器的采集周期是相互独立的,很难保证同时采集数据。在空间域内,传感器在部署时具有不同的视角。另一方面,在设计一种融合方法时,我们需要密切关注几个问题,比如:
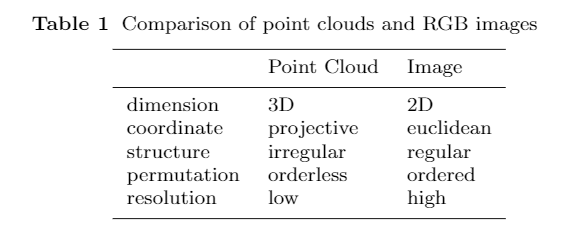
多传感器校准和数据对齐:由于多模态数据的异质性(如表 1 所示),无论是在原始输入空间还是在特征空间,都很难对它们进行精确对齐。
信息丢失:为了将传感器数据转换成能够以计算成本进行对齐和处理的格式,信息丢失是不可避免的
跨模态数据增强:数据增强在三维目标检测中起着至关重要的作用,可以减少模型过拟合,这种过拟合通常是由训练数据不足引起的。全局旋转和随机翻转等增强策略在单模态融合方法中得到了广泛的应用,但由于多传感器一致性的问题,在许多多传感器融合方法中缺乏这种方法。
数据集和评测标准:高质量、公共可用的多模态数据集数量有限。即使是现有的数据集也存在规模小、类别不平衡、标记错误等问题。此外,目前还没有针对数据集的指标来具体评估多传感器融合的有效性,这给多传感器融合方法之间的比较带来了困难。
综上所述,传感器融合已成为感知子系统实现满意性能的必要模块,但在真正享受其带来的好处之前,还需要解决许多设计和实现上的挑战。为了实现这一目标,本文开始对最近基于融合的 3D 目标检测方法进行系统的回顾。这样的回顾可以帮助确定传感器融合中的技术挑战,并帮助我们比较和对比各种模型提出的解决方案。特别是,由于摄像头和激光雷达是自动驾驶中最常见的传感器,该综述主要关注这两种传感器数据的融合。
之前关于基于深度学习的多模态融合方法的调查涵盖了大量的传感器,包括雷达,摄像头,激光雷达,超声波传感器等,并提供了一个简短的综述,包括多目标检测,跟踪,环境重建等广泛的主题。本综述具有明显不同的目的:它针对的是想仔细研究多模态 3D 检测领域的研究人员,本文的贡献总结如下:
根据输入传感器数据的不同组合,本文回顾了基于多模态的三维目标检测方法。特别是距离图像,它是激光雷达点云的一种信息完整形式,在过去的综述文章中没有被讨论。此外,伪激光雷达(由相机图像生成)的表示也没有讨论;
本文从多个角度仔细研究了基于多模态的三维目标检测策略的发展。特别关注这些方法如何实现跨模式数据对齐、如何减少信息丢失等关键问题;
本文详细讨论了最近的相机-激光雷达融合检测方法。同时还总结了近年来可用于三维目标检测的多模态数据集;
仔细讨论了一些具有挑战性的问题以及可能的解决方案,以期对未来的研究有所启发。

Conclusion
由于三维视觉在自动驾驶等应用中的重要性日益增加,本文调研了近年来的多模态三维目标检测网络,特别是相机图像和激光雷达点云的融合。首先作者仔细比较了常用的传感器,讨论了它们的优缺点,总结了单模态方法的常见问题。然后,本文提供了几个常用的自动驾驶数据集。
为了提供一个系统的回顾,本文从以下三个维度将多模态融合方法进行分类:1)融合发生在模型中的位置;1)每个融合输入使用数据表示的形式;3)融合算法的粒度。最后,本文讨论了多模三维目标检测中的开放式挑战和潜在的解决方案。
特别鸣谢
感谢 TCCI 天桥脑科学研究院对于 PaperWeekly 的支持。TCCI 关注大脑探知、大脑功能和大脑健康。
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
???? 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
???? 投稿通道:
• 投稿邮箱:[email protected]
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
????
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。
