【机器学习】(二)——如何评价模型的好坏
学习目标:
1、数据拆分:训练数据集&测试数据集
2、评价分类结果:精准度、混淆矩阵、精准率、召回率、F1 Score、ROC曲线等
3、评价回归结果:MSE、RMSE、MAE、R Squared
知识整理:
【1】
模型训练好之后,需要评价模型的好坏,但是测试数据也是需要有对应分类结果的,这时就需要从已有数据中分出测试集和训练集。
我们需要将原始数据中的一部分作为训练数据、另一部分作为测试数据。使用训练数据训练模型,再用测试数据看好坏。即通过测试数据判断模型好坏,然后再不断对模型进行修改。
鸢尾花数据集(简介)是UCI数据库中常用数据集。我们可以直接加载数据集,并尝试对数据进行一定探索:
iris_train_test.py:
import numpy as np
from sklearn import datasets
import matplotlib.pyplot as plt
iris = datasets.load_iris()
X = iris.data
y = iris.target
print(X.shape)
# 输出:(150, 4)
print(X.shape)
# 输出:(150,)
# 一般情况下我们按照0.8:0.2的比例拆分训练集与测试集
# 但是有时候我们不能简单地把前n个数据作为训练数据集,后n个作为测试数据集
# 比如数据集有序,那么取前n个数据集(可能都是同一类别)容易使测试不准确
# ****解决方案****
# 1、将X和y合并为同一个矩阵,然后对矩阵进行shuffle,之后再分解
# 2、对y的索引进行乱序,根据索引确定与X的对应关系,最后再通过乱序的索引进行赋值
# 方法一:
# 使用concatenate函数进行拼接,因为传入的矩阵必须具有相同的形状
# 因此需要对label进行reshape操作,reshape(-1,1)表示行数自动计算,1列。axis=1表示纵向拼接
tempConcat = np.concatenate((X, y.reshape(-1,1)), axis=1)
# 拼接好后,直接进行乱序操作
np.random.shuffle(tempConcat)
# 再将shuffle后的数组使用split方法拆分
shuffle_X,shuffle_y = np.split(tempConcat, [4], axis=1)
# 设置划分的比例
test_ratio = 0.2
test_size = int(len(X) * test_ratio)
X_train = shuffle_X[test_size:]
y_train = shuffle_y[test_size:]
X_test = shuffle_X[:test_size]
y_test = shuffle_y[:test_size]
print(X_train.shape)
print(X_test.shape)
print(y_train.shape)
print(y_test.shape)
# 方法二:
# 将x长度这么多的数,返回一个新的打乱顺序的数组
# 注意,数组中的元素不是原来的数据,而是混乱的索引
shuffle_index = np.random.permutation(len(X))
# 指定测试数据的比例
test_ratio = 0.2
test_size = int(len(X) * test_ratio)
test_index = shuffle_index[:test_size]
train_index = shuffle_index[test_size:]
X_train = X[train_index]
X_test = X[test_index]
y_train = y[train_index]
y_test = y[test_index]
print(X_train.shape)
print(X_test.shape)
print(y_train.shape)
print(y_test.shape)
封装train_test_split(model_selection.py):
import numpy as np
def train_test_split(X, y, test_ratio=0.2, seed=None):
"""将矩阵X和标签y按照test_ration分割成X_train, X_test, y_train, y_test"""
assert X.shape[0] == y.shape[0], \
"the size of X must be equal to the size of y"
assert 0.0 <= test_ratio <= 1.0, \
"test_train must be valid"
if seed:
# 是否使用随机种子,使随机结果相同,方便debug
np.random.seed(seed)
# permutation(n) 可直接生成一个随机排列的数组,含有n个元素
shuffle_index = np.random.permutation(len(X))
test_size = int(len(X) * test_ratio)
test_index = shuffle_index[:test_size]
train_index = shuffle_index[test_size:]
X_train = X[train_index]
X_test = X[test_index]
y_train = y[train_index]
y_test = y[test_index]
return X_train, X_test, y_train, y_test调用(test.py)
from kNN_test.model_selection import train_test_split
from sklearn import datasets
iris = datasets.load_iris()
X = iris.data
y = iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y)
print(X_train.shape)
print(X_test.shape)
print(y_train.shape)
print(y_test.shape)
sklearn中的train_test_split:
上面写的train_test_split也是在模仿sklearn的风格,我们可以直接在sklearn中调用:
from sklearn.model_selection import train_test_split
from sklearn import datasets
iris = datasets.load_iris()
X = iris.data
y = iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, 0.2, 666)
print(X_train.shape)
print(X_test.shape)
print(y_train.shape)
print(y_test.shape)【2】
[********测评手写数字识别*******]
精准度:
在划分出测试数据集后,我们就可以验证其模型准确率了(accuracy)
accuracy_score:函数计算分类准确率,返回被正确分类的样本比例(default)或者是数量(normalize=False)
[在多标签分类问题中,该函数返回子集的准确率,对于一个给定的多标签样本,如果预测得到的标签集合与该样本真正的标签集合严格吻合,则subset accuracy =1.0否则是0.0]
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
X_train, X_test, y_train, y_test = train_test_split(X, y)
knn_clf = KNeighborsClassifier(n_neighbors=3)
knn_clf.fit(X_train, y_train)
y_predict = knn_clf.predict(X_test)
# 比对y_predict和y_test结果是否一致
print(sum(y_predict == y_test) / len(y_test)) 在我们自己的工程文件中添加一个metrics.py,用来度量性能的各种指标:
mport numpy as np
from math import sqrt
def accuracy_score(y_true, y_predict):
"""计算y_true和y_predict之间的准确率"""
assert y_true.shape[0] != y_predict.shape[0], \
"the size of y_true must be equal to the size of y_predict"
return sum(y_true == y_predict) / len(y_true)调用:
from kNN_test.metrics import accuracy_score
accuracy_score(y_test, y_predict)更多的时候,我们还是使用sklearn中封装好的方法:
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
X_train, X_test, y_train, y_test = train_test_split(X, y, 0.2,666)
knn_clf = KNeighborsClassifier(n_neighbors=3)
knn_clf.fit(X_train, y_train)
y_predict = knn_clf.predict(X_test)
print(accuracy_score(y_test, y_predict))混淆矩阵:
{对于一个癌症预测系统,输入检查指标,判断是否患有癌症,预测准确度99.9%。这个系统是好是坏呢?
如果癌症产生的概率是0.1%,那其实根本不需要任何机器学习算法,只要系统预测所有人都是健康的,即可达到99.9%的准确率。也就是说对于极度偏斜(Skewed Data)的数据,只使用分类准确度是不能衡量。}
在此引入混淆矩阵(Confusion Matrix):
对于二分类问题来说,所有的问题被分为0和1两类,混淆矩阵是2*2的矩阵:
| 预测值0 | 预测值1 | |
|---|---|---|
| 真实值0 | TN | FP |
| 真实值1 | FN | TP |
-
TN:真实值是0,预测值也是0,即我们预测是negative,预测正确了。
-
FP:真实值是0,预测值是1,即我们预测是positive,但是预测错误了。
-
FN:真实值是1,预测值是0,即我们预测是negative,但预测错误了。
-
TP:真实值是1,预测值是1,即我们预测是positive,预测正确了。
现在假设有1万人进行预测,填入混淆矩阵如下:
| 预测值0 | 预测值1 | |
|---|---|---|
| 真实值0 | 9978 | 12 |
| 真实值1 | 2 | 8 |
对于1万个人中,有9978个人本身并没有癌症,我们的算法也判断他没有癌症;有12个人本身没有癌症,但是我们的算法却错误地预测他有癌症;有2个人确实有癌症,但我们算法预测他没有癌症;有8个人确实有癌症,而且我们也预测对了。
因为混淆矩阵表达的信息比简单的分类准确度更全面,因此可以通过混淆矩阵得到一些有效的指标。
代码实现:
import numpy as np
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
digits = datasets.load_digits()
X = digits.data
y = digits.target.copy()
# 要构造偏斜数据,将数字9的对应索引的元素设置为1,0~8设置为0
y[digits.target==9]=1
y[digits.target!=9]=0
# 使用逻辑回归做一个分类
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=666)
log_reg = LogisticRegression()
log_reg.fit(X_train,y_train)
# 得到X_test所对应的预测值
y_log_predict = log_reg.predict(X_test)
# 分类准确度
print(log_reg.score(X_test, y_test))
# 定义混淆指标:TN
def TN(y_true, y_predict):
assert len(y_true) == len(y_predict)
# (y_true == 0):向量与数值按位比较,得到的是一个布尔向量
# 向量与向量按位与,结果还是布尔向量
# np.sum 计算布尔向量中True的个数(True记为1,False记为0)
return np.sum((y_true == 0) & (y_predict == 0))
# 向量与向量按位与,结果还是向量
print(TN(y_test, y_log_predict))
# 定义混淆指标:FP
def FP(y_true, y_predict):
assert len(y_true) == len(y_predict)
# (y_true == 0):向量与数值按位比较,得到的是一个布尔向量
# 向量与向量按位与,结果还是布尔向量
# np.sum 计算布尔向量中True的个数(True记为1,False记为0)
return np.sum((y_true == 0) & (y_predict == 1)) # 向量与向量按位与,结果还是向量
print(FP(y_test, y_log_predict))
# 定义混淆指标:FN
def FN(y_true, y_predict):
assert len(y_true) == len(y_predict)
# (y_true == 0):向量与数值按位比较,得到的是一个布尔向量
# 向量与向量按位与,结果还是布尔向量
# np.sum 计算布尔向量中True的个数(True记为1,False记为0)
return np.sum((y_true == 1) & (y_predict == 0)) # 向量与向量按位与,结果还是向量
print(FN(y_test, y_log_predict))
# 定义混淆指标:TP
def TP(y_true, y_predict):
assert len(y_true) == len(y_predict)
# (y_true == 0):向量与数值按位比较,得到的是一个布尔向量
# 向量与向量按位与,结果还是布尔向量
# np.sum 计算布尔向量中True的个数(True记为1,False记为0)
return np.sum((y_true == 1) & (y_predict == 1)) # 向量与向量按位与,结果还是向量
print(TP(y_test, y_log_predict))
# 输出混淆矩阵
def confusion_matrix(y_true, y_predict):
return np.array([
[TN(y_true, y_predict), FP(y_true, y_predict)],
[FN(y_true, y_predict), TP(y_true, y_predict)]
])
print(confusion_matrix(y_test, y_log_predict))精准率(查准率):
因accuracy定义清洗、计算方法简单,因此经常被使用。但是它在某些情况下并不一定是评估模型的最佳工具。精度(查准率)和召回率(查全率)等指标对衡量机器学习的模型性能在某些场合下要比accuracy更好。
根据混淆矩阵可以求得指标:
| 预测值0 | 预测值1 | |
|---|---|---|
| 真实值0 | 9978(TN) | 12(FP) |
| 真实值1 | 2(FN) | 8(TP) |
精准率: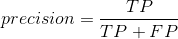 ,即精准率为8/(8+12)=40%。所谓的精准率是:分母为所有预测为1的个数,分子是其中预测对了的个数,即预测值为1,且预测对了的比例。
,即精准率为8/(8+12)=40%。所谓的精准率是:分母为所有预测为1的个数,分子是其中预测对了的个数,即预测值为1,且预测对了的比例。
为什么管它叫精准率呢?在有偏的数据中,我们通常更关注值为1的特征,比如“患病”,比如“有风险”。在100次结果为患病的预测,平均有40次预测是对的。即:精准率为我们关注的那个事件,预测的有多准。
代码实现:
def precision_score(y_true, y_predict):
tp = TP(y_true, y_predict)
fp = FP(y_true, y_predict)
try:
return tp / (tp + fp)
except:
return 0.0
print(precision_score(y_test, y_log_predict))召回率(查全率):
召回率: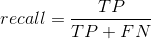 ,即精准率为8/(8+2)=80%。所谓召回率是:所有真实值为1的数据中,预测对了的个数。每当有100个癌症患者,算法可以成功的预测出8个 。也就是我们关注的那个事件真实的发生情况下,我们成功预测的比例是多少。
,即精准率为8/(8+2)=80%。所谓召回率是:所有真实值为1的数据中,预测对了的个数。每当有100个癌症患者,算法可以成功的预测出8个 。也就是我们关注的那个事件真实的发生情况下,我们成功预测的比例是多少。
那么为什么需要精准率和召回率呢?还是下面的这个例子,有10000个人,混淆矩阵如下:
| 预测值0 | 预测值1 | |
|---|---|---|
| 真实值0 | 9978 | 12 |
| 真实值1 | 2 | 8 |
如果我们粗暴的认为所有人都是健康的,那算法的准确率是99.78%,但这是毫无意义的。如果算精准率则是40%,召回率是80%。
有的时候,对于一个算法而言,精准率高一些,召回率低一些;或者召回率高一些,精准率低一些。该如何取舍呢?
【答:视场景而定】
比如我们做了一个股票预测系统,未来股票是还是这样一个二分类问题。很显然“涨”才是我们关注的焦点,那么我们肯定希望:系统预测上涨的股票中,真正上涨的比例越大越好,这就是希望查准率高。那么我们是否关注查全率呢?在大盘中有太多的真实上涨股票,虽然我们漏掉了一些上升周期,但是我们没有买进,也就没有损失。但是如果查准率不高,预测上涨的结果下跌了,那就是实实在在的亏钱了。所以在这个场景中,查准率更重要。
当然也有追求召回率的场景,在医疗领域做疾病诊断,如果召回率低,意味着本来有一个病人得病了,但是没有正确预测出来,病情就恶化了。我们希望尽可能地将所有有病的患者都预测出来,而不是在看在预测有病的样例中有多准。
代码实现:
def recall_score(y_true, y_predict):
tp = TP(y_true, y_predict)
fn = FN(y_true, y_predict)
try:
return tp / (tp + fn)
except:
return 0.0
print(recall_score(y_test, y_log_predict))
scikit-learn中的混淆矩阵,精准率和召回率:
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
digits = datasets.load_digits()
X = digits.data
y = digits.target.copy()
# 要构造偏斜数据,将数字9的对应索引的元素设置为1,0~8设置为0
y[digits.target==9]=1
y[digits.target!=9]=0
# 使用逻辑回归做一个分类
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=666)
log_reg = LogisticRegression()
log_reg.fit(X_train,y_train)
# 得到X_test所对应的预测值
y_log_predict = log_reg.predict(X_test)
# 混淆矩阵
from sklearn.metrics import confusion_matrix
print(confusion_matrix(y_test, y_log_predict))
# 输出:
# array([[403, 2],
# [ 9, 36]])
# 精准率
from sklearn.metrics import precision_score
print(precision_score(y_test, y_log_predict))
# 输出:
# 0.947368421053
# 召回率
from sklearn.metrics import recall_score
print(recall_score(y_test, y_log_predict))
# 输出:
# 0.8但是,在实际业务场景中,也有很多没有这么明显的选择。那么在同时需要关注精准率和召回率,如何在两个指标中取得平衡呢?在这种情况下,我们使用一种新的指标:F1 Score。
F1 Score(二者兼顾):
如果要我们综合精准率和召回率这两个指标,我们可能会想到取平均值这样的方法。F1 Score的思想也差不多:
F1 Score 是精准率和召回率的调和平均值:![]()
什么是调和平均值?为什么要取调和平均值?调和平均值的特点是如果二者极度不平衡,如某一个值特别高、另一个值特别低时,得到的F1 Score值也特别低;只有二者都非常高,F1才会高。这样才符合我们对精准率和召回率的衡量标准。
![]()
代码实现:
def f1_score(precision, recall):
try:
return 2 * precision * recall / (precision + recall)
except:
return 0.0
print(f1_score(precision_score(y_test, y_log_predict),recall_score(y_test, y_log_predict)))ROC曲线:
基础概念:
1、分类阈值,即设置判断样本为正例的阈值thr,
如果某个逻辑回归模型对某封电子邮件进行预测时返回的概率为 0.9995,则表示该模型预测这封邮件非常可能是垃圾邮件。相反,在同一个逻辑回归模型中预测分数为 0.0003 的另一封电子邮件很可能不是垃圾邮件。可如果某封电子邮件的预测分数为 0.6 呢?为了将逻辑回归值映射到二元类别,您必须指定分类阈值(也称为判定阈值)。如果值高于该阈值,则表示“垃圾邮件”;如果值低于该阈值,则表示“非垃圾邮件”。人们往往会认为分类阈值应始终为 0.5,但阈值取决于具体问题,因此您必须对其进行调整。
2、TPR:预测为1,且预测对了的数量,占真实值为1的数据百分比。很好理解,就是召回率。
![]()
3、FPR:预测为1,但预测错了的数量,占真实值不为1的数据百分比。与TPR相对应,FPR除以真实值为0的这一行所有的数字和 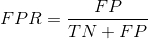
TPR和FPR之间是成正比的,TPR高,FPR也高。ROC曲线就是刻画这两个指标之间的关系。
[ROC曲线]:
ROC曲线(Receiver Operation Characteristic Cureve),描述TPR和FPR之间的关系。x轴是FPR,y轴是TPR。
我们已经知道,TPR就是所有正例中,有多少被正确地判定为正;FPR是所有负例中,有多少被错误地判定为正。 分类阈值取不同值,TPR和FPR的计算结果也不同,最理想情况下,我们希望所有正例 & 负例 都被成功预测 TPR=1,FPR=0,即 所有的正例预测值 > 所有的负例预测值,此时阈值取最小正例预测值与最大负例预测值之间的值即可。
TPR越大越好,FPR越小越好,但这两个指标通常是矛盾的。为了增大TPR,可以预测更多的样本为正例,与此同时也增加了更多负例被误判为正例的情况。
代码实现:
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
digits = datasets.load_digits()
X = digits.data
y = digits.target.copy()
# 要构造偏斜数据,将数字9的对应索引的元素设置为1,0~8设置为0
y[digits.target == 9] = 1
y[digits.target != 9] = 0
# 使用逻辑回归做一个分类
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=666)
log_reg = LogisticRegression()
log_reg.fit(X_train, y_train)
# 计算逻辑回归给予X_test样本的决策数据值
# 通过decision_function可以调整精准率和召回率
decision_scores = log_reg.decision_function(X_test)
def TN(y_true, y_predict):
assert len(y_true) == len(y_predict)
# (y_true == 0):向量与数值按位比较,得到的是一个布尔向量
# 向量与向量按位与,结果还是布尔向量
# np.sum 计算布尔向量中True的个数(True记为1,False记为0)
return np.sum((y_true == 0) & (y_predict == 0))
# 向量与向量按位与,结果还是向量
# 定义混淆指标:FP
def FP(y_true, y_predict):
assert len(y_true) == len(y_predict)
# (y_true == 0):向量与数值按位比较,得到的是一个布尔向量
# 向量与向量按位与,结果还是布尔向量
# np.sum 计算布尔向量中True的个数(True记为1,False记为0)
return np.sum((y_true == 0) & (y_predict == 1)) # 向量与向量按位与,结果还是向量
# 定义混淆指标:FN
def FN(y_true, y_predict):
assert len(y_true) == len(y_predict)
# (y_true == 0):向量与数值按位比较,得到的是一个布尔向量
# 向量与向量按位与,结果还是布尔向量
# np.sum 计算布尔向量中True的个数(True记为1,False记为0)
return np.sum((y_true == 1) & (y_predict == 0)) # 向量与向量按位与,结果还是向量
# 定义混淆指标:TP
def TP(y_true, y_predict):
assert len(y_true) == len(y_predict)
# (y_true == 0):向量与数值按位比较,得到的是一个布尔向量
# 向量与向量按位与,结果还是布尔向量
# np.sum 计算布尔向量中True的个数(True记为1,False记为0)
return np.sum((y_true == 1) & (y_predict == 1)) # 向量与向量按位与,结果还是向量
# TPR
def TPR(y_true, y_predict):
tp = TP(y_true, y_predict)
fn = FN(y_true, y_predict)
try:
return tp / (tp + fn)
except:
return 0.0
# FPR
def FPR(y_true, y_predict):
fp = FP(y_true, y_predict)
tn = TN(y_true, y_predict)
try:
return fp / (fp + tn)
except:
return 0.0
fprs = []
tprs = []
# 以0.1为步长,遍历decision_scores中的最小值到最大值的所有数据点,将其作为阈值集合
thresholds = np.arange(np.min(decision_scores), np.max(decision_scores), 0.1)
for threshold in thresholds:
# decision_scores >= threshold 是布尔型向量,用dtype设置为int
# 大于等于阈值threshold分类为1,小于为0,用这种方法得到预测值
y_predict = np.array(decision_scores >= threshold, dtype=int)
# print(y_predict)
# print(y_test)
# print(FPR(y_test, y_predict))
# 对于每个阈值,所得到的FPR和TPR都添加到相应的队列中
fprs.append(FPR(y_test, y_predict))
tprs.append(TPR(y_test, y_predict))
# 绘制ROC曲线,x轴是fpr的值,y轴是tpr的值
plt.plot(fprs, tprs)
plt.show() 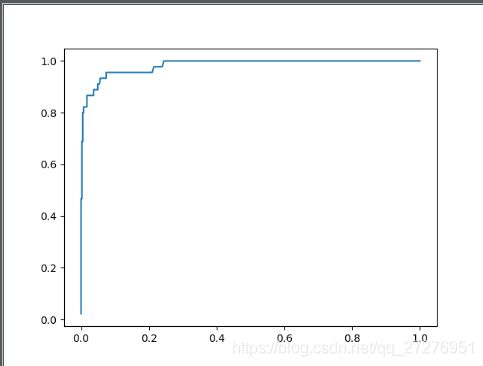
sklearn中的ROC曲线:
from sklearn.metrics import roc_curve
import matplotlib.pyplot as plt
# 计算逻辑回归给予X_test样本的决策数据值
# 通过decision_function可以调整精准率和召回率
decision_scores = log_reg.decision_function(X_test)
fprs, tprs, thresholds = roc_curve(y_test, decision_scores)
plt.plot(fprs, tprs)
plt.show()ROC曲线距离左上角越近,证明分类器效果越好。如果一条算法1的ROC曲线完全包含算法2,则可以断定性能算法1>算法2。这很好理解,此时任做一条 横线(纵线),任意相同TPR(FPR) 时,算法1的FPR更低(TPR更高),故显然更优。
很多时候两个分类器的ROC曲线交叉,无法判断哪个分类器性能更好,这时可以计算曲线下的面积AUC,作为性能度量。
AUC(曲线下面积):
一般在ROC曲线中,我们关注是曲线下面的面积, 称为AUC(Area Under Curve)。这个AUC是横轴范围(0,1 ),纵轴是(0,1)所以总面积是小于1的。
ROC和AUC的主要应用:比较两个模型哪个好?主要通过AUC能够直观看出来。
ROC曲线下方由梯形组成,矩形可以看成特征的梯形。因此,AUC的面积可以这样算:(上底+下底)* 高 / 2,曲线下面的面积可以由多个梯形面积叠加得到。AUC越大,分类器分类效果越好。
-
AUC = 1,是完美分类器,采用这个预测模型时,不管设定什么阈值都能得出完美预测。绝大多数预测的场合,不存在完美分类器。
-
0.5 < AUC < 1,优于随机猜测。这个分类器(模型)妥善设定阈值的话,能有预测价值。
-
AUC = 0.5,跟随机猜测一样,模型没有预测价值。
-
AUC < 0.5,比随机猜测还差;但只要总是反预测而行,就优于随机猜测。
可以在sklearn中求出AUC值:
from sklearn.metrics import roc_auc_score
print(roc_auc_score(y_test, decision_scores))【3】
[******代码基于波士顿房产预测的实际例子******]
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
# 查看数据集描述
boston = datasets.load_boston()
print(boston.DESCR)
# 查看数据集的特征列表
print(boston.feature_names)
# 取出数据中的第六例的所有行(房间数量)
x = boston.data[:, 5]
print(x.shape)
# 取出样本标签
y = boston.target
print(y.shape)
plt.scatter(x, y)
plt.show() 
# 在图中我们可以看到 50W 美元的档分布着一些点
# 这些点可能是超出了限定范围
# 比如在问卷调查中,价格的最高档位是“50万及以上”,那么就全都划到50W上了,因此在本例中,可以将这部分数据去除
np.max(y)
x = x[y < 50.0]
y = y[y < 50.0]
plt.scatter(x,y)
plt.show()简单线性回归:
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
# 查看数据集描述
boston = datasets.load_boston()
# 取出数据中的第六例的所有行(房间数量)
x = boston.data[:, 5]
# 取出样本标签
y = boston.target
# 在本例中,去除“50万及以上”的数据
np.max(y)
x = x[y < 50.0]
y = y[y < 50.0]
from kNN_test.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y, seed=666)
print(x_train.shape) # (392,)
print(y_train.shape) #(392,)
print(x_test.shape) #(98,)
print(y_test.shape) #(98,)
from kNN_test.SimpleLinearRegression import SimpleLinearRegression
reg = SimpleLinearRegression()
reg.fit(x_train,y_train)
print(reg.a_) # 7.8608543562689555
print(reg.b_) # -27.459342806705543
plt.scatter(x_train,y_train)
plt.plot(x_train, reg.predict(x_train),color='r')
plt.show()
y_predict = reg.predict(x_test)
print(y_predict)SimpleLinearRegression.py:
import numpy as np
from .metrics import r2_score
class SimpleLinearRegression:
def __init__(self):
"""模型初始化函数"""
self.a_ = None
self.b_ = None
def fit(self, x_train, y_train):
"""根据训练数据集x_train,y_train训练模型"""
assert x_train.ndim ==1, \
"简单线性回归模型仅能够处理一维特征向量"
assert len(x_train) == len(y_train), \
"特征向量的长度和标签的长度相同"
x_mean = np.mean(x_train)
y_mean = np.mean(y_train)
num = (x_train - x_mean).dot(y_train - y_mean) # 分子
d = (x_train - x_mean).dot(x_train - x_mean) # 分母
self.a_ = num / d
self.b_ = y_mean - self.a_ * x_mean
return self
def predict(self, x_predict):
"""给定待预测数据集x_predict,返回表示x_predict的结果向量"""
assert x_predict.ndim == 1, \
"简单线性回归模型仅能够处理一维特征向量"
assert self.a_ is not None and self.b_ is not None, \
"先训练之后才能预测"
return np.array([self._predict(x) for x in x_predict])
def _predict(self, x_single):
"""给定单个待预测数据x_single,返回x_single的预测结果值"""
return self.a_ * x_single + self.b_
def score(self, x_test, y_test):
"""根据测试数据x_test、y_test计算简单线性回归准确度(R方)"""
y_predict = self.predict(x_test)
return r2_score(y_test, y_predict)
def __repr__(self):
"""返回一个可以用来表示对象的可打印字符串"""
return "SimpleLinearRegression()" 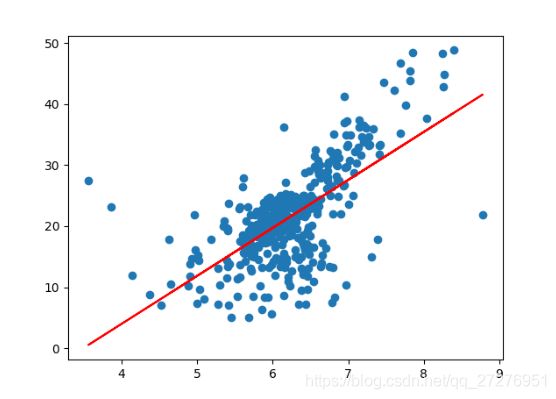
简单线性回归的目标是:已知训练数据样本x、y,找到a和b的值,使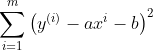 尽可能小
尽可能小
实际上是找到训练数据集中![]() 最小。
最小。
衡量标准是看在测试数据集中y的真实值与预测值之间的差距。
因此我们可以使用下面公式作为衡量标准:![]()
但是这里有一个问题,这个衡量标准是和m相关的。在具体衡量时,测试数据集不同将会导致误差的累积量不同。
首先我们从“使损失函数尽量小”这个思路出发:
对于训练数据集合来说,使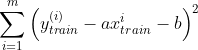 尽可能小
尽可能小
在得到a和b之后将 代入a、b中。可以使用
代入a、b中。可以使用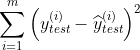 来作为衡量回归算法好坏的标准。
来作为衡量回归算法好坏的标准。
MSE(均方误差):
测试集中的数据量m不同,因为有累加操作,所以随着数据的增加 ,误差会逐渐积累;因此衡量标准和 m 相关。为了抵消掉数据量的形象,可以除去数据量,抵消误差。通过这种处理方式得到的结果叫做 均方误差MSE(Mean Squared Error):
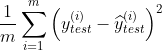
代码实现:
# MSE
mse_test = np.sum((y_predict - y_test) ** 2) / len(y_test)
print(mse_test)RMSE(均方根误差):
但是使用均方误差MSE收到量纲的影响。例如在衡量房产时,y的单位是(万元),那么衡量标准得到的结果是(万元平方)。为了解决量纲的问题,可以将其开方(为了解决方差的量纲问题,将其开方得到平方差)得到均方根误差RMSE(Root Mean Squarde Error):
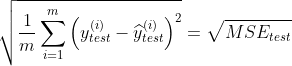
代码实现:
# RMSE
from math import sqrt
rmse_test = sqrt(mse_test)
print(rmse_test)MAE(平均绝对误差):
对于线性回归算法还有另外一种非常朴素评测标准。要求真实值![]() 与 预测结果
与 预测结果![]() 之间的距离最小,可以直接相减做绝对值,加m次再除以m,即可求出平均距离,被称作平均绝对误差MAE(Mean Absolute Error):
之间的距离最小,可以直接相减做绝对值,加m次再除以m,即可求出平均距离,被称作平均绝对误差MAE(Mean Absolute Error):
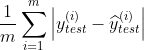
在之前确定损失函数时,我们提过,绝对值函数不是处处可导的,因此没有使用绝对值。但是在评价模型时不影响。因此模型的评价方法可以和损失函数不同。
# MAE
mae_test = np.sum(np.absolute(y_predict - y_test)) / len(y_test)
print(mae_test)R Squared:
分类准确率,就是在01之间取值。但RMSE和MAE没有这样的性质,得到的误差。因此RMSE和MAE就有这样的局限性,比如我们在预测波士顿方差,RMSE值是4.9(万美元) 我们再去预测身高,可能得到的误差是10(厘米),我们不能说后者比前者更准确,因为二者的量纲根本就不是一类东西。
其实这种局限性,可以被解决。用一个新的指标R Squared:
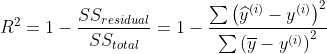
R方这个指标为什么好呢?
-
对于分子来说,预测值和真实值之差的平方和,即使用我们的模型预测产生的错误。
-
对于分母来说,是均值和真实值之差的平方和,即认为“预测值=样本均值”这个模型(Baseline Model)所产生的错误。
-
我们使用Baseline模型产生的错误较多,我们使用自己的模型错误较少。因此用1减去较少的错误除以较多的错误,实际上是衡量了我们的模型拟合住数据的地方,即没有产生错误的相应指标。
我们根据上述分析,可以得到如下结论:
-
R^2 <= 1
-
R2越大也好,越大说明减数的分子小,错误率低;当我们预测模型不犯任何错误时,R2最大值1
-
当我们的模型等于基准模型时,R^2 = 0
-
如果R^2 < 0,说明我们学习到的模型还不如基准模型。此时,很有可能我们的数据不存在任何线性关系。