VQA2-2017-Dual Attention Networks for Multimodal Reasoning and Matching

原文网址:
文章目录
- Abstrace
- 1. Introduction
- 2. Related Work
-
- 2.1. Attention Mechanisms
- 2.2. Visual Question Answering (VQA)
- 2.3. Image-Text Matching
- 3. Dual Attention Networks (DANs)
-
- 3.1. Input Representation
- 3.2. Attention Mechanisms
- 3.3. r-DAN for Visual Question Answering
- 3.4. m-DAN for Image-Text Matching
- 4. Experiments
-
- 4.1. Experimental Setup
- 4.2. Evaluation on Visual Question Answering
-
- 4.2.1 Dataset and Evaluation Metric
- 4.2.2 Results and Analysis
- 4.3. Evaluation on Image-Text Matching
-
- 4.3.1 Dataset and Evaluation Metric
- 4.3.2 Results and Analysis
- 5. Conclusion
Abstrace
我们提出了双重注意力网络(DAN),该网络联合利用视觉和文本注意力机制来捕获视觉和语言之间的细微相互作用。 DAN通过多个步骤关注图像中的特定区域和文本中的单词,并从这两种方式中收集基本信息。 在此框架的基础上,我们分别介绍了两种用于多模式推理和匹配的DAN。 推理模型允许视觉和文本注意力在协作推理过程中相互引导,这对于诸如视觉问题解答(VQA)之类的任务很有用。 另外,匹配模型利用两种注意力机制,通过关注图像和句子的共享语义来估计图像和句子之间的相似性。 我们进行的广泛实验验证了DAN在结合视觉和语言方面的有效性,并在VQA和图像文本匹配的公共基准上实现了最先进的性能。
1. Introduction
视觉和语言是人类了解现实世界的两个核心部分。 它们也是实现人工智能的基本组成部分,几十年来在每个领域都进行了大量研究。 近年来,深度学习的巨大进步打破了视觉和语言之间的界限,引起了人们对其交集的浓厚兴趣,例如视觉问答(VQA)[3,37,23,35],图像字幕[33,2],图像 -文字匹配[8、11、20、30],可视化背景[24、9]等。
注意机制是神经网络的最新进展之一[21,4,33]。 它旨在按顺序专注于数据的某些方面,并随着时间的流逝汇总基本信息以推断结果,并且已成功应用于视觉和语言领域。 在计算机视觉中,基于注意力的方法自适应地选择图像区域序列以提取必要的特征[21、6、33]。 同样,用于自然语言处理的注意力模型会突出显示特定的单词或句子,以从输入文本中提取信息[4、25、15]。 这些方法结合包括卷积神经网络(CNN)和递归神经网络(RNN)在内的深层架构,提高了广泛应用的性能。
尽管注意力在处理视觉和文本数据方面都是有效的,但几乎没有尝试在视觉和文本注意力模型之间建立联系,这在各种情况下都是非常有益的。 例如,图1a中的VQA问题是伞是什么颜色? 可以通过同时关注伞的区域和单词颜色来有效地解决问题。 在图1b中的图像文本匹配示例中,可以通过关注特定区域和共享共同语义(例如女孩和游泳池)的单词来有效地测量图像和句子之间的相似性。

在本文中,我们提出了双重注意力网络(DAN),该网络可以共同学习视觉和文本注意力模型,以探索视觉和语言之间的细粒度交互。我们研究了图1中所示的DAN的两个变体,分别称为推理DAN(rDAN)和匹配DAN(m-DAN)。 rDAN使用联合记忆协作地执行视觉和文本注意力,该记忆汇集了先前的注意力结果并指导了后续的注意力。它适合需要多模式推理的任务,例如VQA。另一方面,m-DAN将视觉和文本注意模型与不同的记忆分开,但共同训练它们以捕获图像和句子之间的共享语义。这种方法最终找到了一个联合嵌入空间,可以促进有效的跨模式匹配和检索。两种提出的算法都将视觉和文本注意机制紧密地连接到一个统一的框架中,从而在VQA和图像-文本匹配问题上实现了出色的性能。
总而言之,我们工作的主要贡献如下:
•我们提出了一个视觉和文字关注的整合框架,其中关键区域和单词通过多个步骤共同定位。
•为多模式推理和匹配实现了所提议框架的两个变体,并将其应用于VQA和图像-文本匹配。
•注意结果的详细可视化验证了我们的模型有效地专注于给定任务的视觉和文本数据的重要部分。
•我们的框架展示了VQA数据集[3]和Flickr30K图像文本匹配数据集[36]的最新性能。
2. Related Work
2.1. Attention Mechanisms
注意机制使模型可以在任务的每个步骤集中于视觉或文本输入的必要部分。 视觉注意模型选择性地注意图像中的小区域,以提取核心特征并减少要处理的信息量。 近来,许多方法采用视觉注意力来使图像分类[21、28],图像生成[6],图像标题[33],视觉问答[35、26、32]等受益。 另一方面,文本 注意机制通常旨在在编码器-解码器框架下找到语义或语法上的输入输出对齐方式,这在处理长期依赖性方面特别有效。 该方法已成功应用于各种任务,包括机器翻译[4],文本生成[16],句子摘要[25]和问题解答[15、32]。
2.2. Visual Question Answering (VQA)
VQA是用自然语言回答有关给定图像的问题的任务,这需要对视觉和文本数据进行多模式推理。 自从Antol等[3]提出了一个包含自由格式和开放式问题的大规模数据集以来,它就引起了人们的关注。 Zhou等人[37]的一个简单基准通过CNN图像特征和词袋问题特征的串联来预测答案。 根据给定的问题,几种方法可以自适应地构建深度体系结构。 例如,Noh等人[23]在问题所学的CNN上强加了一个动态参数层,而Andreas等人[1]利用问题的组成结构来组装神经模块集合。
上述方法的局限性在于它们诉诸于包含噪声或不必要信息的全局图像表示。为了解决这个问题,Yang等人[35]提出了执行多步视觉注意的堆叠式注意网络,Shih等人[26]使用对象建议来识别与给定问题相关的区域。最近,动态内存网络[32]将注意力机制与内存模块集成在一起,并且利用多峰紧凑双线性池[5]来表达性地组合多峰特征并预测图像上的注意力。这些方法通常使用视觉注意力来查找关键区域,但是文本注意力很少被纳入VQA。 尽管HieCoAtt [18]运用了视觉和文字注意,但它独立执行共同注意的每个步骤,而无需推理先前的共同注意输出。相反,我们的方法基于先前注意力的记忆,通过多个推理步骤移动和完善了两种注意力,这有利于视觉和文本数据之间的紧密相互作用。
2.3. Image-Text Matching
图像-文本匹配的核心问题是测量视觉和文本输入之间的语义相似性。 通常通过学习一个联合空间来解决,该联合空间中图像和句子特征向量可直接比较。 Hodosh等人[8]应用规范相关分析(CCA)来找到使图像和句子之间的相关性最大化的嵌入,并通过结合深度神经网络对其进行了进一步改进[14,34]。 Wang等人的最新方法(文献[30])在双向损失函数中包含了结构保留约束,以使联合空间更具区分性。 相反,Ma等人[19]构建了一个CNN,将图像和句子片段组合成一个联合表示,从中可以直接推断出匹配分数。 基于给定查询图像的句子的逆概率,图像字幕框架也被用来估计相似度[20,29]。
据我们所知,还没有研究尝试学习用于图像-文本匹配的多模式注意力模型·。 即使Karpathy等人[11,10]提出寻找图像区域和句子片段之间的对齐方式,他们仍然明确计算它们之间的所有成对距离并估计平均或最佳对齐方式得分,这导致效率低下。 另一方面,我们的方法将图像和句子之间的共享概念自动嵌入到一个联合空间中,该空间中的跨模态相似性可通过单个内部积运算直接获得。
3. Dual Attention Networks (DANs)
我们提出了DAN的两种结构,以巩固视觉和文本注意机制:r-DAN用于多模态推理,而m-DAN用于多模态匹配。 它们具有相同的框架,但是在视觉和文字注意之间的关联方式却有所不同。 我们首先描述通用框架,包括输入表示(第3.1节)和注意机制(第3.2节)。 然后,我们说明分别应用于VQA和图像文本匹配的r-DAN(第3.3节)和mDAN(第3.4节)的细节。
3.1. Input Representation
图像表示 .图像特征是从19层VGGNet [27]或152层ResNet [7]中提取的。 我们首先将图像缩放为448×448,然后将其输入到CNN中。 为了获得不同区域的特征向量,我们采用VGGNet的最后一个池化层(pool5)或ResNet的最后一个池化层之下的层(res5c)。 最终,输入图像由 { v 1 , v 2 , ⋯ , v N } \{v_1,v_2,\cdots,v_N\} {v1,v2,⋯,vN}表示,其中 N N N是图像区域的数量, v n v_n vn是与第 n n n个区域相对应的512(VGGNet)或2048(ResNet)尺寸特征向量。
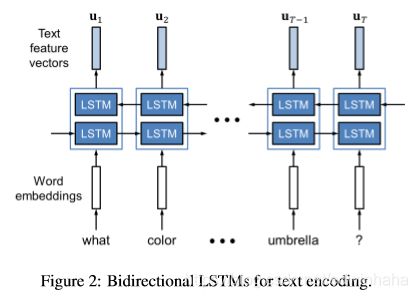
3.2. Attention Mechanisms
我们的方法通过多个步骤同时执行视觉和文本注意,并从这两种方式中收集必要的信息。 在本节中,我们将解释在每个步骤中使用的潜在注意力机制,这些机制是构成整个DAN的基础。 为简单起见,我们将在以下方程式中省略偏置项 b b b。
视觉注意。 视觉注意力旨在通过关注输入图像的某些部分来生成上下文向量。 在步骤 k k k,视觉上下文向量 V ( k ) V^{(k)} V(k)由下式给出:

其中, m v k − 1 m_v^{k-1} mvk−1是编码在步骤 k − 1 k-1 k−1之前一直被关注的信息的存储向量。具体地说,我们采用了软注意机制,其中,上下文向量是从输入特征向量的加权平均值中获得的。 注意权重 { α v , n ( k ) } n = 1 N \{ \alpha_{v,n}^{(k)}\}_{n=1}^N {αv,n(k)}n=1N由2层前馈神经网络(FNN)和softmax函数计算:
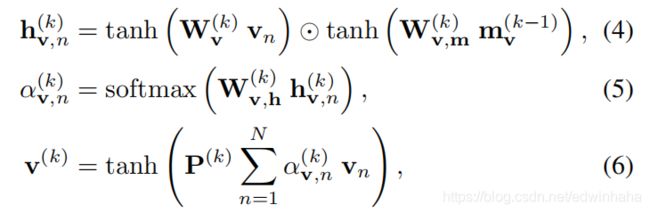
其中 W v k , W v , m ( k ) W_v^{k},W_{v,m}^{(k)} Wvk,Wv,m(k)和 W v , h ( k ) W_{v,h}^{(k)} Wv,h(k)是网络参数, h v , n ( k ) h_{v,n}^{(k)} hv,n(k)是隐藏状态,并且 ⊙ \odot ⊙是逐元素乘法。 在等式6中,我们引入了一个具有权重矩阵 P ( k ) P(k) P(k)的附加层,以便将视觉上下文向量嵌入到带有文本上下文向量的兼容空间中,因为我们使用了预训练的图像特征 v n v_n vn。
文字注意。 文本注意力通过每一步关注输入句子中的特定单词来计算文本上下文向量 u ( k ) u^{(k)} u(k):
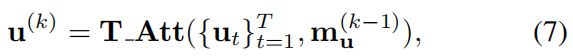
其中 m u ( k − 1 ) m_u^{(k-1)} mu(k−1)是一个存储向量。 文本注意机制与视觉注意机制几乎相同。 换句话说,注意权重 { α u , t ( k ) } t = 1 T \{\alpha_{u,t}^{(k)}\}_{t=1}^T {αu,t(k)}t=1T是从2层FNN获得的,上下文向量 u ( k ) u^{(k)} u(k)是通过加权平均来计算的:
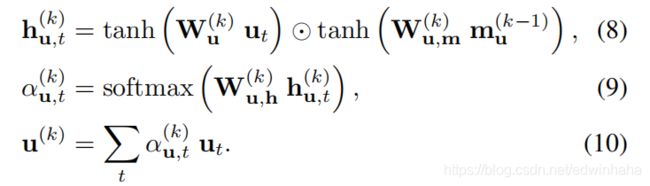
其中 W u ( k ) , W u , m ( k ) W_u^{(k)}, W_{u,m}^{(k)} Wu(k),Wu,m(k)和 W u , h ( k ) W_{u,h}^{(k)} Wu,h(k)是网络参数, h u , t ( k ) h_{u,t}^{(k)} hu,t(k)是隐藏状态。 与视觉注意力不同,它在最后一次加权平均后不需要额外的图层,因为文本特征 u t u_t ut已被端到端训练。
3.3. r-DAN for Visual Question Answering
VQA是一个代表性问题,需要对多模式数据进行联合推理。 为此,rDAN维护一个联合存储向量 m ( k ) m^{(k)} m(k),该向量累计了直到步骤 k k k之前一直在关注的视觉和文本信息。 它由递归更新
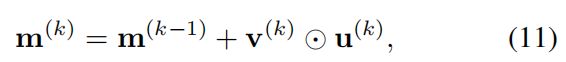
其中 v ( k ) v^{(k)} v(k)和 u ( k ) u^{(k)} u(k)分别是从等式6和10获得的视觉和文本上下文向量。 这种联合表示同时引导视觉和文本注意,即 m ( k ) = m v ( k ) = m u ( k ) m^{(k)}= m^{(k)}_v = m_u^{(k)} m(k)=mv(k)=mu(k),这允许两个注意机制彼此紧密协作。 基于全局上下文向量 v ( 0 ) v^{(0)} v(0)和 u ( 0 ) u^{(0)} u(0)定义初始存储向量 m ( 0 ) m^{(0)} m(0)为
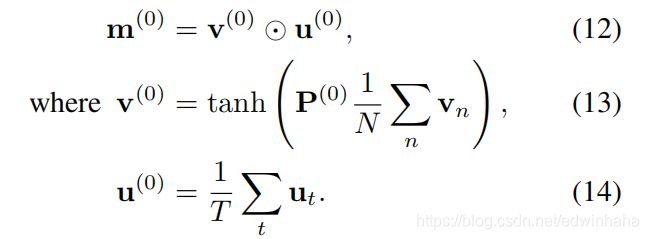
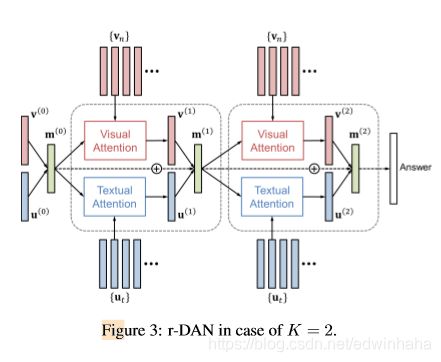
通过对K步重复双重注意(等式3和7)和内存更新(等式11),我们有效地专注于图像和问题中的关键部分,并收集了用于回答问题的相关信息。 图3说明了在 K = 2 K = 2 K=2的情况下r-DAN的总体架构。
通过对前C个常见答案的多方分类来预测最终答案。 我们使用具有交叉熵损失的单层softmax分类器,其中输入是最终内存 m ( k ) m^{(k)} m(k):
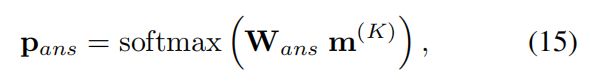
其中 P a n s P_{ans} Pans代表候选答案的概率。
3.4. m-DAN for Image-Text Matching
图像文本匹配任务通常涉及大量图像和句子之间的比较,其中有效而高效的跨模式相似性计算至关重要。 为此,我们旨在学习满足以下特性的联合嵌入空间。 首先,嵌入空间对在图像和句子域中经常同时出现的共享概念进行编码。 此外,图像和句子无需配对就自动嵌入到关节空间中,因此空间中的任意图像和句子向量可直接比较。
我们的m-DAN共同学习视觉和文本注意模型,以捕获两种模式之间的共享概念,但在推理时将它们分开,以在嵌入空间中提供大致可比的表示。 与使用联合记忆的r-DAN相反,m-DAN保留了单独的记忆向量,以引起视觉和文本注意:
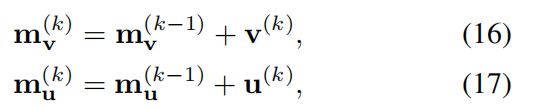
分别初始化为公式13和14中定义的 v ( 0 ) v^{(0)} v(0)和 u ( 0 ) u^{(0)} u(0)。 在每一步,我们都通过它们的内积来计算视觉和文本上下文向量之间的相似度 s ( k ) s^{(k)} s(k):

在执行了两次注意和记忆更新的 K K K个步骤之后,给定图像和句子之间的最终相似度 S S S变为
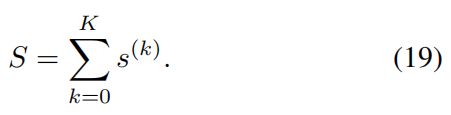
当 K = 2 K = 2 K=2时,该模型的整体架构如图4所示。

该网络经过双向最大边距排序损失训练,广泛用于多模式相似性学习[11、10、13、30]。 对于图像和句子 ( u , v ) (u,v) (u,v)的每个正确对,我们还分别对否定图像 v v v和否定句子 u u u进行采样,以构造两个否定对 ( v − , u ) (v^-,u) (v−,u)和 ( v , u − ) (v,u^-) (v,u−)。 然后,损失函数变为:
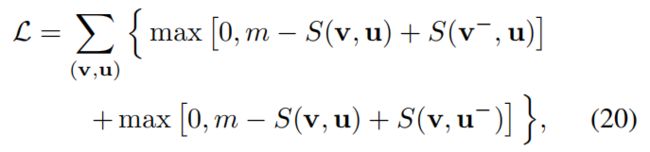
其中 m m m是裕度约束。 通过最小化此功能,可以训练网络专注于通过视觉和文本注意机制仅出现在正确的图像句子对中的常见语义。
在推断时,通过连接上下文向量将任意图像或句子嵌入到联合空间中:
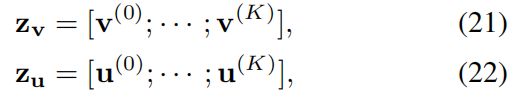
其中 z v z_v zv和 z u z_u zu分别是图像 v v v和句子 u u u的表示。 请注意,这些向量是通过视觉和文字注意的单独管道获得的,即从图像或句子本身而不是从图像句子对揭示学习的共享概念。 关节空间中两个向量之间的相似性可以通过它们的内积简单地计算出来,例如 S ( v , u ) = z v ⋅ z u S(v,u)=z_v\cdot z_u S(v,u)=zv⋅zu,它等于公式19中网络的输出。
4. Experiments
4.1. Experimental Setup
我们修复了同时应用于r-DAN和m-DAN的所有超参数。 注意步骤数K设置为2,根据经验可显示最佳性能。 每个隐藏层的大小(包括单词嵌入,LSTM和注意模型)设置为512。我们通过随机梯度下降训练我们的网络,学习速率为0.1,动量为0.9,权重衰减为0.0005,辍学比为0.5,梯度修剪 在0.1。 该网络训练了60个时期,其中学习率在30个时期后下降到0.01。 r-DAN和m-DAN的小批量分别由128对<图像,问题>和128个四联体<正图像,正句,负图像,负句>组成。 VQA的可能答案C的数量设置为2000,等式20中的损失函数的余量m设置为100。
4.2. Evaluation on Visual Question Answering
4.2.1 Dataset and Evaluation Metric
我们在视觉问题解答(VQA)数据集[3]上评估了r-DAN,该数据集包含来自MSCOCO数据集[17]的大约200K真实图像。 每个图像都与三个问题相关联,并且每个问题都由人工注释者标记了十个答案。 数据集通常分为四个部分:训练(80K图像),val(40K图像),test-dev(20K图像)和test-std(20K图像)。 我们使用train和val训练模型,使用test-dev进行验证,并在test-std上进行评估。 任务有两种形式,开放式和多项选择,分别要求每个问题不带和带有一组候选答案。 对于这两个任务,我们遵循[3]中使用的评估指标,即
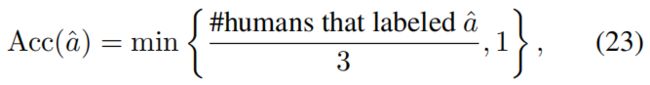
其中 a ^ \hat{a} a^是预测的答案。
4.2.2 Results and Analysis
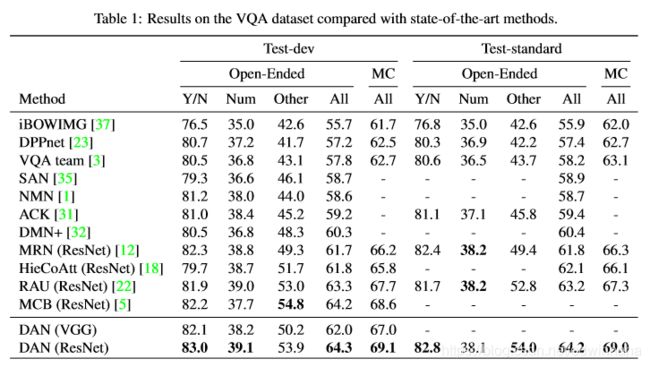
表1列出了r-DAN与最新VQA系统的性能,其中我们的方法在开放式和多项选择任务中均达到了最佳性能。为了进行公平的评估,我们比较了没有增加数据就获得的单模型准确性,即使[5]报告使用模型集合和其他训练数据获得了更好的性能。图5用注意力权重的可视化描述了我们方法的定性结果。我们的方法可以为需要细粒度推理的具有挑战性的问题提供正确答案,并且可以成功地关注特定区域和单词,从而有助于回答问题。具体来说,图5中的第一个和第四个示例说明了r-DAN将其视觉注意力移到了由出席单词指示的适当区域,而第二个和第三个示例显示了r-DAN将其文本注意力移至了将复杂任务划分为顺序任务子任务-查找目标对象并提取某些属性。

4.3. Evaluation on Image-Text Matching
4.3.1 Dataset and Evaluation Metric
我们采用Flickr30K数据集[36]来评估mDAN进行多模式匹配。 它由31783个真实图像组成,每个图像有5个描述性句子,我们按照[20]进行的公开拆分:29,783个训练,1,000个验证和1,000个测试图像。 我们报告m DAN在双向图像和句子检索中的性能与以前的工作相同[34,19,20,30]。 Recall @ K(K = 1、5、10)表示查询的百分比,其中在前K个结果中至少检索到一个地面真相,而MR衡量排名最高的地面真相的中位。
4.3.2 Results and Analysis
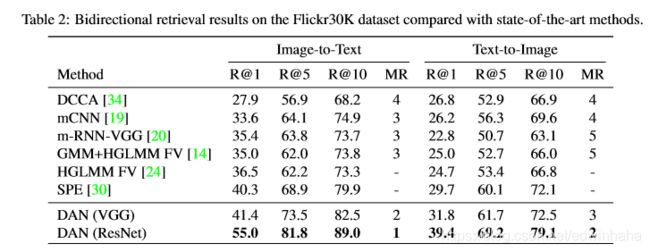
表2给出了Flickr30K数据集上的定量结果,该方法在所有指标上均优于其他方法。 图像到文本和文本到图像检索的定性结果分别在图6和图7中进行了说明,并显示了注意输出。 在关注的每个步骤中,m-DAN都能有效地发现出现在两种形式中的基本语义。 它倾向于在第一步捕获主要对象(例如女人,男孩,人等),并在第二步找出相关的对象,背景或动作(例如计算机,脚手架,扫帚等)。 请注意,此属性仅来自训练阶段,在该阶段可以共同学习视觉和文本注意模型,而图像和句子则在推理时进行独立处理。


5. Conclusion
我们提出了双重注意网络(DAN),以桥接视觉和文本注意机制。 我们介绍了用于多模式推理和匹配的DAN的两种体系结构。 第一个模型从图像和句子中共同推断出答案,而另一个模型通过捕获它们的共享语义将它们嵌入到公共空间中。 这些模型展示了VQA和图像文本匹配中的最新性能,显示了它们通过双重关注机制提取基本信息的有效性。 所提出的框架可以潜在地推广到视觉和语言交汇处的各种任务,例如图像字幕,视觉基础,视频问答等。