Multi-Granularity Alignment for Visual Question Answering(视觉问答的多粒度对齐)
摘要
找到不同模态之间以及每个模态内的组件连接以获得更好的注意力权重是至关重要的。本文重点关注如何构建输入分层和嵌入结构信息,来改善不同层次组件之间的对齐。
本文提出了视觉问答任务的多粒度对齐架构(MGA-VQA),该架构通过多粒度对齐来学习模态内和模态间的相关性,并通过决策融合模块输出最终结果。
介绍
整个细粒度图像特征和整个自然语言句子的直接融合非常复杂,缺乏可解释性。本文重点研究再没有额外数据的情况下更有效的学习多模态的对齐,为了实现粒度级对齐,通过引入lead graph的概念将图结构信息嵌入到我们的模型中。
贡献:
- 本文提出了一种新的多粒度对齐架构,该架构在三个不同层次上联合学习模态内和模态间的相关关系:概念实体层次、区域名词短语层次和空间句子层次。此外,将结果与决策融合模块集成,以获得最终答案。
- 本文提出了一种联合注意机制,将问题引导的视觉注意和图像引导的问题注意结合起来,提高了解释性。
- 实验在两个具有挑战性的基准数据集GQA和VQA-v2上进行。证明了本文提出的模型在没有额外预训练数据的情况下在两个数据集方法的有效性。此外,本文的方法甚至比预先训练的方法在GQA上取得了更好的结果。
目前存在方法的一些缺陷:
图像缺乏自然语言的语法结构,语言可能存在偏见。
文本特征和细粒度图像特征之间的对齐,其中图像缺乏语言结构和语法规则,导致难以获得良好的结果。 此外,这些工作大多以简单的方式处理问题,而忽略了自然语言领域中的内部逻辑关系。这些问题成为理解多模态特征之间关系的瓶颈。
方法
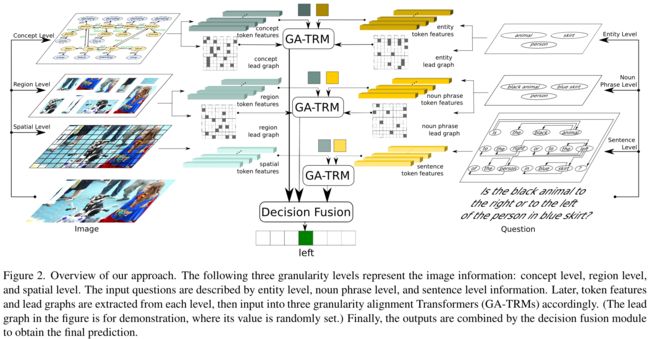
模型的主要思想:在多模态输入之间相应地对齐多个信息层次,并整合信息以获得最终预测。该模型包含了三种不同粒度层次的对齐。
首先,从输入图像中检测对象,包括它们的名称、相应的属性和关系。在问题方面,检测名词短语、实体和句子语法结构。然后使用lead graph进一步引导对齐学习,并根据上述步骤中提取的结构信息构造它们,其中图中的节点被视为下一步的token特征。这些特征是以下三个粒度对齐Transformers(GA-TRMs)的基本组成部分:概念级和实体级信息、区域级和名词短语级信息以及空间级和句子级信息。最后,三个GA-TRM的输出通过决策融合模块用于预测答案。
VQA中的粒度层次

图像中的粒度信息
给定输入图像(Img),以不同的粒度层次提取三个层次的特征。 对于每个粒度层次,都有一组关联的 token特征 和 lead graph 对。 我们首先构造 graphG={E, L} 表示当前粒度层次的信息,其中 tokens(E) 是图中的实体,lead graph(L) 是对应邻接矩阵中的连接对。
概念层次(Concept Level):由对象的语义特征,属性和对象之间的关系组成。首先从图像中提取这些信息并构成相应的图 ![]() ,首先将关系看作是额外的节点,然后将该图拆分为节点序列
,首先将关系看作是额外的节点,然后将该图拆分为节点序列 ![]() 并通过索引
并通过索引![]() 表示节点连接对。为了描述节点之间的关系,将 subject-predicate-object 三元组分解成 subject -> predicate 和 predicate -> object 。这样的话,可以将 subject-predicate-object 和 subject/object-attribut 都由索引对来描述,它们被视为节点连接
表示节点连接对。为了描述节点之间的关系,将 subject-predicate-object 三元组分解成 subject -> predicate 和 predicate -> object 。这样的话,可以将 subject-predicate-object 和 subject/object-attribut 都由索引对来描述,它们被视为节点连接![]() 。
。
[Example 1]
在这里,token序列的特征![]() 是通过GloVe嵌入和多层感知器(MLP)从节点序列
是通过GloVe嵌入和多层感知器(MLP)从节点序列 ![]() 计算出来的。
计算出来的。
区域层次(Region Level):区域层次描述了中间层次的视觉特征,它表示物体的视觉区域。与概念层次中的对象特征不同,此层次中的特征描述了对象 视觉而不是语义。token序列的特征 ![]() 是由Faster R-CNN提取,然后关系对
是由Faster R-CNN提取,然后关系对 ![]() 的获取方式和
的获取方式和 ![]() 是相同的。其中,如果两个对象在概念级别上存在语义关系,则在区域级别上存在对应的关系对。
是相同的。其中,如果两个对象在概念级别上存在语义关系,则在区域级别上存在对应的关系对。
[Example 2]
空间层次(Spatial Level):空间层次描述了整体但粒度最高的视觉特征,并提供了前两个层次的详细、空间和补充信息,即场景信息。从主干CNN中提取的 token 序列特征 ![]() ,
,![]() 是所有特征单元的全连接关系。
是所有特征单元的全连接关系。
问题中的粒度信息
从输入问题提取三个层次的特征,包括结构和语法信息以进行更好的对齐。
实体层次:实体层特征表示表示问题中没有属性的单个对象,帮助模型在抽象概念上进行对齐。token 序列特征  与图像中的概念特征处理方式相似,对应的 lead graph 对
与图像中的概念特征处理方式相似,对应的 lead graph 对 是全连接对。
是全连接对。
名词短语层次:首先过滤解析器解析后的结果,去掉限定词(a, the)和表示位置关系的词(left, right)。构造名词性短语是为了与图像中的区域层次特征进行对齐,其中视觉特征包含了属性。由于大多数组件为多个单词,我们没有将它们合并为单个token,而是将其拆分,并使用MLP处理GloVe特征,并获得token特征 ![]() 。此外,对应的 lead graph 对
。此外,对应的 lead graph 对![]() 是全连接对。
是全连接对。
句子层次:对于句子级,使用依赖解析器对问题进行处理,并从依赖图中得到相应的邻接矩阵(![]() ) 。由于视觉特征比自然语言具有更高的层次,并且需要更少的语境聚合,因此在对齐之前需要对句子级特征进行进一步处理,以便更好地将结构信息嵌入到输入中。首先使用额外的Transformer模块来处理句子,以获得上下文感知特征
) 。由于视觉特征比自然语言具有更高的层次,并且需要更少的语境聚合,因此在对齐之前需要对句子级特征进行进一步处理,以便更好地将结构信息嵌入到输入中。首先使用额外的Transformer模块来处理句子,以获得上下文感知特征  ,而不是直接将句子 token 放入Transformer中以融合多模态特征。
,而不是直接将句子 token 放入Transformer中以融合多模态特征。
其中 ![]() 是带有输入token
是带有输入token  和注意力掩码
和注意力掩码  的 Transformer 模块。连接信息已经嵌入到了 中,句子层次的 lead graph 对也由全连接对组成。
的 Transformer 模块。连接信息已经嵌入到了 中,句子层次的 lead graph 对也由全连接对组成。

多模态粒度对齐
GA 多头注意力

将来自图像(![]() ) 和问题(
) 和问题(![]() ) 的 token 串联拼接起来,在进行线性映射之后添加可学习的位置编码(相对和绝对位置信息)。与一般的Transformer模块相比,这里采用Graph merging模块产生的lead graph (
) 的 token 串联拼接起来,在进行线性映射之后添加可学习的位置编码(相对和绝对位置信息)。与一般的Transformer模块相比,这里采用Graph merging模块产生的lead graph (![]() )作为一种mask。
)作为一种mask。
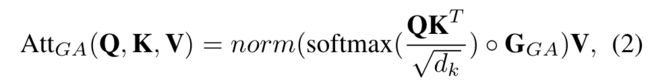
Graph merging模块
graph merging模块的设计是为了将图对( )转换为单模态的lead graph(
)转换为单模态的lead graph(![]() ),然后将他们融合成多模态的lead graph(
),然后将他们融合成多模态的lead graph(![]() )。
)。
单模态lead graph生成:
首先是从图像(![]() )和问题(
)和问题(![]() )的图对中获取单模态的lead graph,
)的图对中获取单模态的lead graph,![]() 都是二值图,维度为
都是二值图,维度为![]()
[Example 2]
假设
,
,则有:
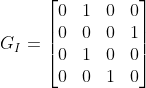
多模态lead graph生成:
多模态lead graph是一组维度为![]() 的二元图,对于编码器的不同层设置了不同的的lead graph。
的二元图,对于编码器的不同层设置了不同的的lead graph。
第一层:

这是为了使模型学习问题的自注意力,因为视觉特征相对较高,需要对句子中的单词进行有限的上下文聚合,后者需要进一步处理。
第二层:
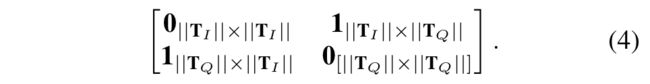
这是为了使模型学习模态间的co-attention。
第三层:
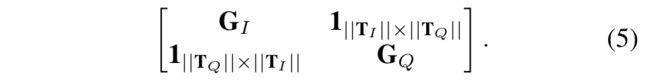
这可以使模型关注两种模式中存在的所有连接。
多粒度决策融合
三个层次对齐后的输出为![]() ,采用线性多模态融合的方式融合特征,
,采用线性多模态融合的方式融合特征,
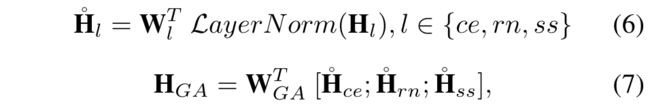
loss被定义为三种层次的交叉熵和决策融合后的交叉熵损失和,并被赋予相同的权重:
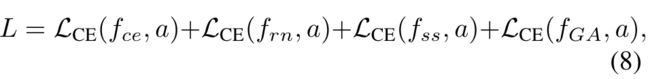
这篇文章总感觉有点怪怪的,实验部分感觉没讲清就不放了