B站路飞学城学习笔记-Python爬虫-爬取电影分类排名-
一、过程分析
1、先打开douban电影排行榜,点击喜剧部分
2、用鼠标滚轮向下翻页,同时按f12进行检查,点击Network中的Headers
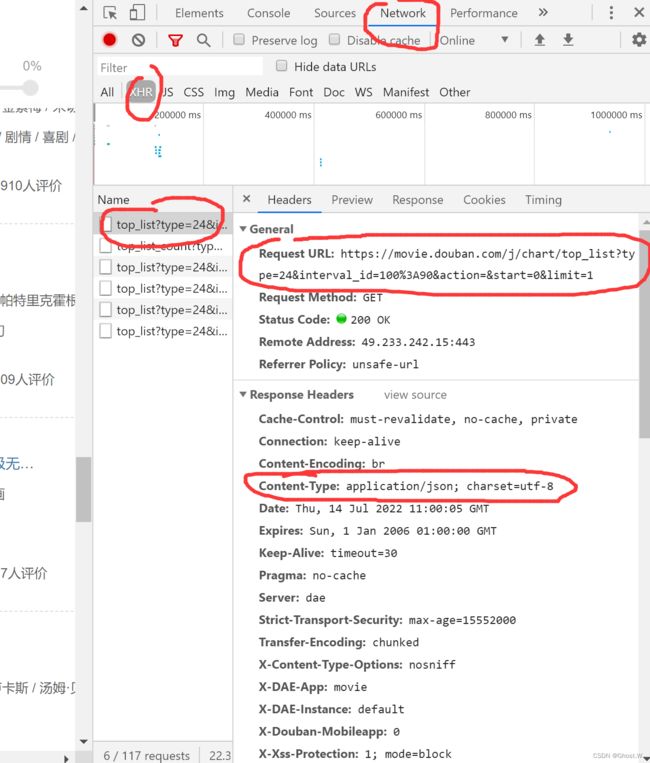
3、我们可以发现Headers中有很多信息,比如Request URL以及Content-Type中的json格式(意思是最后的数据类型是json格式),代码中需要用到
4、最下面的参数是所有页面共有的参数,代码中也需要用到
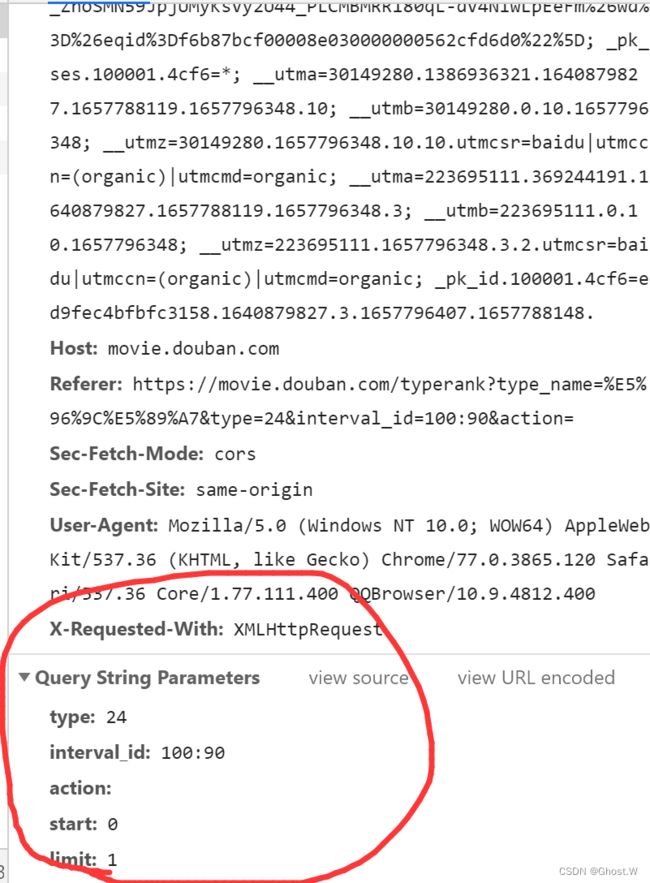
5、 上图中的User-Agent是UA伪装的必要部分,代码中也需要用
以上就是我们所需要的基本信息,下面给出代码
二、代码部分
1、import两个库
import requests
import json2、在main函数中写出url和param字典,其中将第一部分中复制的Requests URL中问号后面的部分去掉,写在字典param里,这样方便我们设置参数,然后我们将start设置为1,limit设置为20,意思是从第二部电影开始,一直到100部电影后
if __name__=="__main__":
url='https://movie.douban.com/j/chart/top_list?'
param={
'type':'4',
'interval_id':'100:90',
'action':'',
'start':'1',#从库中第几部电影开始
'limit':'100',#一次取出的个数
}3、进行UA伪装,伪装自己为浏览器,从而访问该页面
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.120 Safari/537.36 Core/1.77.111.400 QQBrowser/10.9.4812.400'
}4、用response接收通过requests来get()的对象,同时创建一个list_data变量来接收requests.json()的数据
response=requests.get(url=url,params=param,headers=headers)
list_data=response.json()#响应数据为json格式5、文件存储,将其存放在本目录下
fp=open('./douban.json','w',encoding='utf-8')
json.dump(list_data,fp=fp,ensure_ascii=False)6、运行以后点击我们创建的douban.json,将其在网上的json在线识别库中解析后能发现我们的解析是成功的

三、总结
爬取网站的重要一点在于观察其网站的加载方式,然后进行对requests库和json库的结合使用。