Spark项目实践--基于 TMDB 数据集的电影数据分析
基于 TMDB 数据集的电影数据分析
- 一、环境搭建
- 二、数据预处理
- 三、使用 Spark 将数据转为 DataFrame
- 四、使用 Spark 进行数据分析并可视化
-
- 1.单独分析
- 2.字段之间的关系分析
- 五,结语
一、环境搭建
从假设裸机,环境搭建开始,具体环境搭建操作大体流程如下,具体详细流程点击查看另一篇博客:spark环境搭建
大体流程:
(1)安装Linux操作系统:比如可以安装Ubuntu 16.04
(2)安装Hadoop:需要在Linux系统上安装Hadoop
(3)安装Spark:需要在Linux系统上安装Spark
(4)最后为了方便编写代码,实现Linux与Windows下的pycharm对接。
本次实验环境:
pycharm2019专业版
Ubuntu16.04
pip3=10.0.1
pyspark3.0.2
二、数据预处理
环境搭建完成之后,开始做项目。
首先数据集介绍:
本次项目使用的数据集来自数据网站 Kaggle 的 tmdb-movie-metadata 电影数据集,该数据集包含大约 5000 部电影的相关数据。数据包含以下字段:

上图中可以看出数据中某些字段包含 json 数据,因此直接使用 DataFrame 进行读取会出现分割错误,所以如果要创建 DataFrame,需要先直接读取文件生成 RDD,再将 RDD 转为 DataFrame。过程中,还需要使用 python3 中的 csv 模块对数据进行解析和转换。
为了更方便的对 csv 文件转化的 RDD 进行处理,需要首先去除csv文件的标题行。完成后,将处理好的文件 tmdb_5000_movies.csv 存储到 HDFS 上方便进一步的处理,使用下面命令将文件上传至 HDFS:
hdfs dfs -put tmdb_5000_movies.csv
问题一
如果上传过程中遇到如下情况:hdfs: command not found
原因是没有在bin目录之下设置路径,解决:
1.sudo vi /etc/profile打开原文件
2.在文件最后新起一行添加路径export PATH=/usr/local/hadoop/bin:$PATH
其中这里的/usr/local/hadoop/bin是你的hdfs所在的目录,一定看清楚。
3.最后要使文件生效,这个一定不要忘了,不然文件也是白配置。命令:source /etc/profile
这时文件已经被上传至HDFS中
三、使用 Spark 将数据转为 DataFrame
打开Windows下的pycharm,连接到Linux,开始编程
因为读入的 csv 文件是结构化的数据,因此可以将数据创建为 DataFrame 方便进行分析。
上面也说过,为了创建DataFrame ,要将HDFS上的数据加载为RDD,由RDD转为DataFrame ,具体代码以及解析如下:
'''
csv --> HDFS--> RDD --> DataFrame
1.创建 SparkSession 和 SparkContext 对象。
2.为 RDD 转为 DataFrame 制作表头 (schema)。schema 是一个 StructType 对象,
该对象使用一个 StructField 数组创建。
每一个 StructField 都代表结构化数据中的一个字段,构造 StructField 需要 3 个参数
1. 字段名称
2. 字段类型
3. 字段是否可以为空
'''
#这里运行之前的环境配置,有些不配置不会出错,不过由于不是直接在Linux里写的,而是对接的pycharm中,所以可能会出现环境错误,带上这几行代码以防万一
import os
os.environ["JAVA_HOME"] = "/usr/lib/jvm/jdk1.8.0_162"
os.environ["PYSPARK_PYTHON"] = "/usr/bin/python3.5"
#调用包
from pyspark import SparkContext
from pyspark.sql import SparkSession, Row
from pyspark.sql.types import StringType, StructField, StructType
import json # 用于后面的流程
import csv
import matplotlib.pyplot as plt
#创建两个对象
sc = SparkContext('local','spark_project')
sc.setLogLevel('WARN')
spark = SparkSession.builder.getOrCreate()
# 根据数据集表格制作表头
schemaString = "budget,genres,homepage,id," \
"keywords,original_language," \
"original_title,overview,popularity," \
"production_companies,production_countries," \
"release_date,revenue,runtime,spoken_languages," \
"status,tagline,title,vote_average,vote_count"
fields = [StructField(field,StringType(),True)
for field in schemaString.split(',')]
schema = StructType(fields)
# 3. 开始创建用于转为 DataFrame 的 RDD。这个过程首先sc.textFile读取 HDFS 上的数据文件,然后为了将 RDD 转为 DataFrame,还需要使用lambda函数将数据的每一行转为一个 Row 对象。
#lambda函数内部:对于每一行用逗号分隔的数据,(从里到外剖析)
# 1.csv.reader:使用 csv 模块进行解析并转为 Row 对象,得到可以转为 DataFrame 的 RDD
#2.使用 next 函数将迭代器中的数据读取到数组
#3.使用 * 将数组转为 Row 对象的构造函数参数,创建 Row 对象
moviesRdd = sc.textFile('tmdb_5000_movies.csv').map(lambda line: Row(*next(csv.reader([line]))))
#使用准备好的表头 (schema) 和 RDD 创建 DataFrame createDataFrame 创建 DataFrame
mdf = spark.createDataFrame(moviesRdd, schema)
#mdf.show() #至此完成 DataFrame 的创建,show查看最终内容
#print(mdf.collect())
以上数据预处理结束。最后可以打印出来查看数据结构,进行下面的数据分析。
四、使用 Spark 进行数据分析并可视化
接下来使用上述处理完成后得到的 DataFrame mdf 进行数据分析,首先对数据中的主要字段单独进行分析,然后再分析不同字段之间的关系。
为了方便使用matplotlib进行数据可视化,对于每个字段不同的分析,都将分析结果导出为json文件保存之后,对该文件进行数据可视化。
接下来的每个分析都需要进行保存,所以提前定义一个save函数,直接调用即可:
def save(path, data):
with open(path, 'w') as f:
f.write(data)
注意!!!下列代码中所有的save有关的函数如果被注释掉的请打开,否则存储不了的话,可视化分析是不可以的。
1.单独分析
(1)分析数据集中电影的体裁分布
- 数据集中可以看出,电影的体裁字段是一个 json 格式的数据,所以,要统计不同体裁的电影的数量,首先需要解析这个字段的 json 数据,从中取出每个电影对应的体裁数组,然后使用词频统计的方法,根据相同key相加,统计不同体裁出现的频率,即可得到电影的体裁分布。
#选择体裁字段,filter筛选出数据中该字段为空的不要,使用map与lambda函数结合,
madff = mdf.select("genres").filter(mdf["genres"] != '').rdd.flatMap(
lambda g: [(v, 1) for v in map(lambda x: x['name'], json.loads(g["genres"]))])\
.repartition(1).reduceByKey(lambda x, y: x + y)
#print(mdf.collect()) #建议每打出一行代码就运行一下看看结果
res =madff.collect()
#print(list(map(lambda v: {"genre": v[0], "count": v[1]}, res)))
countByGenres=list(map(lambda v: {"genre": v[0], "count": v[1]}, res))
print(countByGenres)
#save('/home/hadoop/test/TMDB/genres.json', json.dumps(countByGenres))
#不可跨平台保存,注意路径,要是虚拟机的路径
#下面画图之前先读取保存的文件数据
with open('/home/hadoop/test/TMDB/genres.json', 'r') as f:
data=json.load(f)
print(data)
#取出画图需要的x,y轴
x=list(map(lambda x:x['genre'],data)) #python自带的map与RDD中map区分开,python中map自动遍历值
y=list(map(lambda x:x['count'],data))
print(x)
print(y)
plt.bar(x,y,0.5)
plt.show()
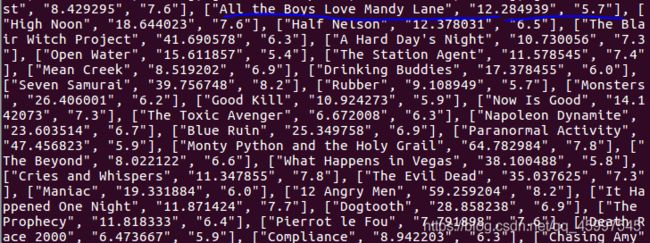
(2) 前 100 个常见关键词
- 该项分析电影关键词中出现频率最高的前一百个。字段也是 json 格式数据,因此也是进行频率统计,统计结果进行降序排序并取前 100 项。
#进行频率统计,同时对于统计结果进行降序排序并取前 100 项,套路如上,选择字段--筛选出无用值--词频统计
keyword = mdf.select("keywords").filter(mdf["keywords"] != '').rdd.flatMap(
lambda g: [(v, 1) for v in map(lambda x: x['name'], json.loads(g["keywords"]))])\
.repartition(1).reduceByKey(lambda x, y: x + y)
res1 = keyword.sortBy(lambda x: -x[1]).take(100)
countByKeywords=list(map(lambda v: {"x": v[0], "value": v[1]}, res1))
print(countByKeywords)
save('/home/hadoop/test/TMDB/keywords.json', json.dumps(countByKeywords))
from wordcloud import WordCloud
with open('/home/hadoop/test/TMDB/keywords.json', 'r') as f:
data=json.load(f)
print(data)
x=list(map(lambda x:x['x'],data))#python自带的map与RDD中map区分开,python中map自动遍历值
save('/home/hadoop/test/TMDB/keywordswc.json',json.dump(x)) #将单词存储为一个文件
跟上面的分两个批次执行,一个处理文本,一个将文本画词云
with open('/home/hadoop/test/TMDB/keywordswc.json', 'r') as f:
datawc=json.load(f)
print(datawc)
datawc1=",".join(datawc) #list转String,因为list类型不可用于词云画图
wc = WordCloud(background_color="white",\
width = 800,\
height = 600,\
).generate(datawc1) #expected string or bytes-like object
wc.to_file('keywords.png') # 保存图片
plt.imshow(wc) # 用plt显示图片
plt.axis('off') # 不显示坐标轴
plt.show()
可视化结果:

(3) 数据集 中最常见的 10 种预算数
- 这一项探究电影常见的预算数是多少
#统计电影常见预算,首先计算对预算字段进行过滤filter,去除预算为 0 的项目,
#然后根据预算聚合groupBy并计数count(),接着根据计数进行排序orderBy,并将结果导出为 json 字符串toJSON(),
#为了统一输出,这里将 json 字符串转为 python 对象,最后取前 10 项作为最终的结果
countByBudget = mdf.filter(mdf["budget"] != 0).groupBy("budget").count().\
orderBy('count', ascending=False).toJSON().map(lambda j: json.loads(j)).take(10)
print(countByBudget)
save('/home/hadoop/test/TMDB/budget.json', json.dumps(countByBudget))
#画图可视化结果,查看预算与统计数的关系
with open('/home/hadoop/test/TMDB/budget.json', 'r') as f:
data=json.load(f)
print(data)
x=list(map(lambda x:x['budget'],data))
y=list(map(lambda x:x['count'],data))
print(x)
print(y)
plt.bar(x,y,0.5)
plt.xticks(rotation = 45)
plt.show()
结果:
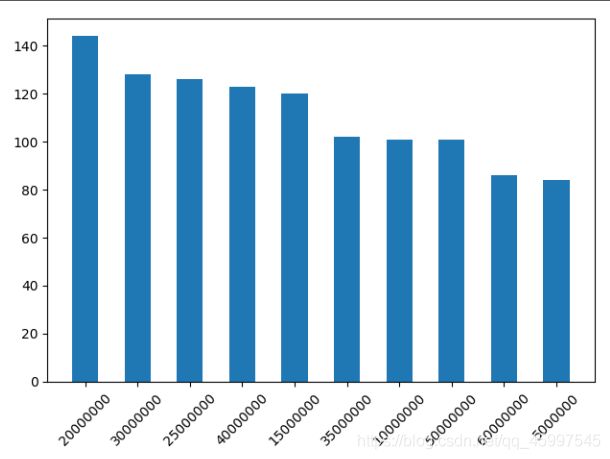
最常见的预算从高到低排列,可以看出20000000的最多。
(4)数据集中最常见电影时长 (只展示电影数大于 100 的时长)
#统计最常见的电影时长,1.过滤掉0分钟的电影,使用filter 筛选出来runtime不等于0的电影
#2.根据时长字段进行聚拢求和,按照key=runtime的聚拢
#3.对2进行计数统计,然后过滤掉时长<100的也就是筛选出时长大于100的,最终将json转为python输出,collect查看结果
Runtime = mdf.filter(mdf["runtime"] != 0).groupBy("runtime").count()\
.filter('count>=100').toJSON().map(lambda j: json.loads(j)).collect()
print(Runtime)
save('/home/hadoop/test/TMDB/runtime.json', json.dumps(Runtime))
#画图,可视化结果
#读取文件内容,取出x,y 使用plt绘图
with open('/home/hadoop/test/TMDB/runtime.json','r') as f:
runtimedata = json.load(f)
print(runtimedata)
x=list(map(lambda x:x["runtime"],runtimedata)) #pyhton中的map格式:map(fun,data)
y=list(map(lambda x:x["count"],runtimedata))
plt.title('Four ')
plt.xlabel('runtime')
plt.ylabel('count')
#将数据显示在条形图上方
ax=plt.bar(x,y)
for rect in ax:#'BarContainer' object has no attribute 'text'
w = rect.get_height()
plt.text(rect.get_x() + rect.get_width() / 2, w, '%d' % int(w), ha='center', va='bottom')
#ha有三个选择:right,center,left
#va有四个选择:'top', 'bottom', 'center', 'baseline'
plt.show()
结果:
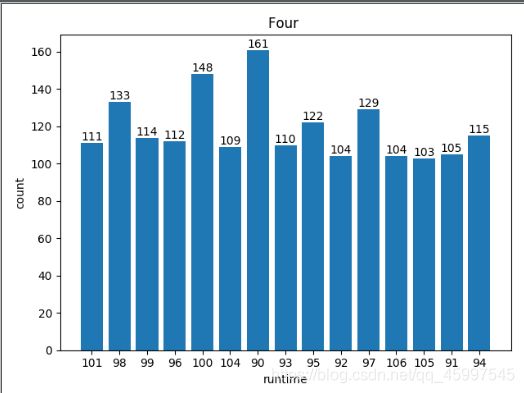
从可视化结果来看最常见的电影时长是90min左右
(5) 生产电影最多的 10 大公司
- 解析 json 格式字段从中提取出 name 并进行词频统计,这里取出"production_companies"字段名称,进行排序,寻找前十个,选择字段select(“production_companies”) ,在字段中筛选出空值 ,使用rdd中的map,最终聚合
#解析 json 格式字段从中提取出 name 并进行词频统计
#这里取出"production_companies"字段名称,进行排序,寻找前十个
#1.选择字段select("production_companies") 2.在字段中筛选出空值 3.使用rdd中的map,最终聚合
res = mdf.select("production_companies").filter(mdf["production_companies"] != '').rdd\
.flatMap(lambda g: [(v, 1) for v in map(lambda x: x['name'], json.loads(g["production_companies"]))])\
.repartition(1).reduceByKey(lambda x, y: x + y)
res5 = res.sortBy(lambda x: -x[1]).take(10)
countByCompanies = list(map(lambda v: {"company": v[0], "count": v[1]}, res5)) #规定输出格式
print(countByCompanies)
save('/home/hadoop/test/TMDB/company_count.json', json.dumps(countByCompanies))
with open('/home/hadoop/test/TMDB/company_count.json','r') as f:
companydata = json.load(f)
print(companydata)
x=list(map(lambda x:x["company"],companydata))
y=list(map(lambda x:x["count"],companydata))
ax=plt.bar(x,y)
for rect in ax:#'BarContainer' object has no attribute 'text'
w = rect.get_height()
plt.text(rect.get_x() + rect.get_width() / 2, w, '%d' % int(w), ha='center', va='bottom')
plt.xticks(rotation = 10)
plt.show()
可视化:
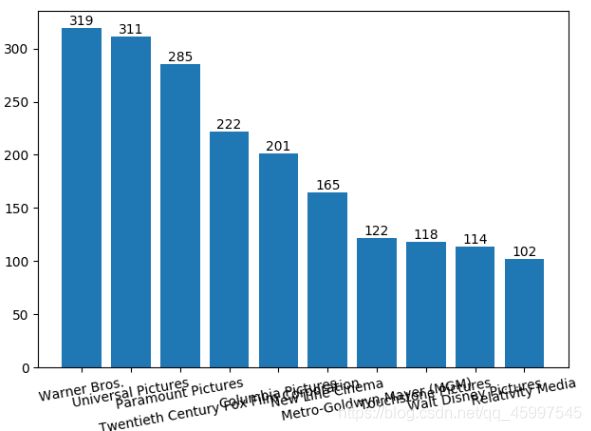
最后x轴字体过长,倾斜度不多,大家可以自己再次调节看看。
(6)TMDb 中的 10 大电影语言 饼图
- 该字段也是 JSON 数据,因此首先对每个项目进行词频统计,然后过滤掉语言为空的项目,最后排序取前十即可。
#该字段也是 JSON 数据,因此首先对每个项目进行词频统计,然后过滤掉语言为空的项目,最后排序取前十即可。
res = mdf.select("spoken_languages").filter(mdf["spoken_languages"] != '').rdd\
.flatMap(lambda g: [(v, 1) for v in map(lambda x: x['name'], json.loads(g["spoken_languages"]))])\
.repartition(1).reduceByKey(lambda x, y: x + y)
res6 =res.sortBy(lambda x: -x[1]).take(10) #排序取前十个
countByLanguage = list(map(lambda v: {"language": v[0], "count": v[1]}, res6))
print(countByLanguage)
save('/home/hadoop/test/TMDB/language.json', json.dumps(countByLanguage))
#开始画图
with open('/home/hadoop/test/TMDB/language.json','r') as f:
landata = json.load(f)
print(landata)
x=list(map(lambda x:x['language'],landata))
y=list(map(lambda x:x['count'],landata))
plt.pie(x=y, #绘图数据
labels=x,#标签
autopct='%.2f%%', #设置百分比的格式,这里保留两位小数
pctdistance=0.8, #设置百分比标签与圆心的距离
labeldistance=1.1, #设置标签与圆心的距离
startangle=180, #设置饼图的初始角度
radius=1.2, #设置饼图的半径
counterclock=False, #是否逆时针,这里设置为顺时针方向
wedgeprops={'linewidth':1.5, 'edgecolor':'green'}, #设置饼图内外边界的属性值
textprops={'fontsize':10, 'color':'black'}, #设置文本标签的属性值
)
plt.legend(loc='upper left', bbox_to_anchor=(-0.3, 1)) #图标的位置
plt.grid()
plt.show()
可视化:

其中有中文字体,由于没有设置中文没有显示出来,这也是在最后整理的时候发现的问题。
2.字段之间的关系分析
(1)预算与评价的关系
- 对于每个电影,需要导出如下的数据:[电影标题title,预算budget,评价vote_average],其中选择后两个字段进行关系绘图
- 需要注意的是,上述代码都是放在一个代码文件中运行的,到这里开始一个关系就是一个py文件,这里除了调用必要的包之外,还需要调用上述文件的mdf变量以及save函数。
import dataonefrom dataone import mdf #调用第一个文件中定义的变量mdf
import os
os.environ["JAVA_HOME"] = "/usr/lib/jvm/jdk1.8.0_162"
os.environ["PYSPARK_PYTHON"] = "/usr/bin/python3.5"
import json # 用于后面的流程
import csv
import matplotlib.pyplot as plt
import dataone
from dataone import mdf #调用dataone中的变量mdf
#基于 DataFrame 对数据进行字段过滤即可 注意过滤掉预算为空的数据,同时,结果只保留了投票数大于 100 的数据确保公平
budgetVote = mdf.select("title", "budget", "vote_average")\
.filter(mdf["budget"] != 0).filter(mdf["vote_count"] > 100).collect()
print(budgetVote)
dataone.save('budget_vote.json', json.dumps(budgetVote))
#可视化
with open('budget_vote.json','r') as f:
buddata = json.load(f)
print(buddata)
x=list(map(lambda x:x[1],buddata))
y=list(map(lambda x:x[2],buddata))
X=[]
Y=[]
for i in x:
X.append(int(i)/10000)
for i in y:
Y.append(float(i))
print(X)
print(Y)
#预算与评价 y z
plt.scatter(X,Y)
plt.xticks(rotation =90 )
plt.show()
保存的json文件:

可视化(只取一部分值画图):

(2)电影发行时间与评价的关系
- 这部分考虑发行时间与评价之间的关系,因此对于每个电影,需要导出如下的数据:[电影标题,发行时间,评价]
import os
os.environ["JAVA_HOME"] = "/usr/lib/jvm/jdk1.8.0_162"
os.environ["PYSPARK_PYTHON"] = "/usr/bin/python3.5"
import json # 用于后面的流程
import csv
import matplotlib.pyplot as plt
import dataone
from dataone import mdf #调用dataone中的变量mdf
#这里还是要注意过滤掉发行时间为空的数据,保留投票数大于 100 的数据
dateVote = mdf.select(mdf["release_date"], "vote_average", "title")\
.filter(mdf["release_date"] != "").filter(mdf["vote_count"] > 100).collect()
dataone.save('date_vote.json', json.dumps(dateVote))
#发行时间与评价
with open('date_vote.json','r') as f:
datedata = json.load(f)
print(datedata)
x=list(map(lambda x:x[0],datedata))
y=list(map(lambda x:x[1],datedata))
X=[]
Y=[]
for i in x:
X.append(i)
for i in y:
Y.append(float(i))
print(X)
print(Y)
plt.bar(X,Y)
plt.xticks(rotation = 90)
plt.show()
看一下保存文件的数据结构:

可视化(依旧是部分取值):
(3)流行度和评价的关系
- 这部分考虑流行度与评价之间的关系,因此对于每个电影,需要导出如下的数据:[电影标题,流行度,评价]
#下面的代码基本上都是一个套路了
import os
os.environ["JAVA_HOME"] = "/usr/lib/jvm/jdk1.8.0_162"
os.environ["PYSPARK_PYTHON"] = "/usr/bin/python3.5"
import json # 用于后面的流程
import csv
import matplotlib.pyplot as plt
import dataone
from dataone import mdf #调用dataone中的变量mdf
#选择需要的字段,过滤掉流行度为0的,保留票数大于100的
popVote = mdf.select("title", "popularity", "vote_average")\
.filter(mdf["popularity"] != 0).filter(mdf["vote_count"] > 100).collect()
dataone.save('pop_vote.json', json.dumps(popVote))
with open('pop_vote.json','r') as f:
popdata = json.load(f)
x=list(map(lambda x:x[1],popdata))
y=list(map(lambda x:x[2],popdata))
X=[]
Y=[]
for i in x:
X.append(float(i))
for i in y:
Y.append(float(i))
print(X)
print(Y)
plt.scatter(X,Y)
plt.xticks(rotation = 90)
plt.xlabel("popularity")
plt.ylabel("vote_average")
plt.show()
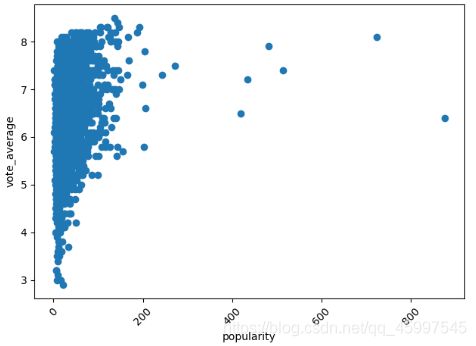
(4)公司生产的电影平均分和数量的关系
- 计算每个公司生产的电影数量及这些电影的平均分分布。
首先,需要对数据进行过滤,去掉生产公司字段为空和评价人数小于 100 的电影,然后对于每一条记录,得到一条如下形式的记录:
[公司名,(评分,1)]
import os
os.environ["JAVA_HOME"] = "/usr/lib/jvm/jdk1.8.0_162"
os.environ["PYSPARK_PYTHON"] = "/usr/bin/python3.5"
import json # 用于后面的流程
import csv
import matplotlib.pyplot as plt
import dataone
from dataone import mdf #调用dataone中的变量mdf
budgetRevenue = mdf.select("title", "budget", "revenue")\
.filter(mdf["budget"] != 0).filter(mdf['revenue'] != 0).collect()
print(budgetRevenue)
dataone.save('budget_revenue.json', json.dumps(budgetRevenue))
with open('budget_revenue.json','r') as f:
buddata = json.load(f)
x=list(map(lambda x:x[1],buddata))
y=list(map(lambda x:x[2],buddata))
X=[]
Y=[]
for i in x:
X.append(float(i))
for i in y:
Y.append(int(i))
print(X)
print(Y)
plt.scatter(X,Y)
plt.xticks(rotation = 90)
plt.xlabel("budget")
plt.ylabel("revenue")
plt.show()


(5)电影预算和营收的关系
- 这部分考虑电影的营收情况,因此对于每个电影,需要导出如下的数据:
[电影标题,预算,收入]
import os
os.environ["JAVA_HOME"] = "/usr/lib/jvm/jdk1.8.0_162"
os.environ["PYSPARK_PYTHON"] = "/usr/bin/python3.5"
import json # 用于后面的流程
import csv
import matplotlib.pyplot as plt
import dataone
from dataone import mdf #调用dataone中的变量mdf
#选择需要的字段,在数据中筛选出预算为0的,收入为0的,聚合剩下的
budgetRevenue = mdf.select("title", "budget", "revenue")\
.filter(mdf["budget"] != 0).filter(mdf['revenue'] != 0).collect()
print(budgetRevenue)
dataone.save('budget_revenue.json', json.dumps(budgetRevenue))
with open('budget_revenue.json','r') as f:
buddata = json.load(f)
x=list(map(lambda x:x[1],buddata))
y=list(map(lambda x:x[2],buddata))
X=[]
Y=[]
for i in x:
X.append(int(i))
for i in y:
Y.append(int(i))
print(X)
print(Y)
plt.scatter(X,Y)
plt.xticks(rotation = 90)
plt.xlabel("budget")
plt.ylabel("revenue")
plt.show()


五,结语
到此,整个数据分析项目结束。
总结,在进行项目实验时:
对于数据
1.考虑数据的结构
2.考虑数据的字段,可以做什么有价值的分析,以及用什么样的可视化可以将分析结果最直观的表达出来
对于编程
1.了解数据结构之后设计相应的数据框架(存储数据的格式),如本项目中将csv文件传输到HDFS中,HDFS将文件加载至RDD,最后由RDD转为DataFrame进行数据分析。
也要想到为什么最终会选择使用DataFrame,因为
- DataFrame是一种表格型数据结构,它含有一组有序的列,每列可以是不同的值。DataFrame既有行索引,也有列索引
DataFrame方便对数据进行提取分析处理。
2.使用的Spark知识,总的就是选择select,过滤filter,聚合reduceByKey,统计,排序sortBy。还需熟练使用matplotlib画图方法。
至此结束,若有错误,请大佬们指正,感谢阅读。