论文-《Visual Question Answering as Reading Comprehension Hui》笔记
论文下载
摘要:
Visual question answering (VQA) demands simultaneous comprehension of both the image visual content and natural language questions. In some cases, the reasoning needs the help ofcommon sense or general knowledge which usually appear in the form of text. Current methods jointly embed both the visual information and the textual feature into the same space. Nevertheless, how to model the complex interactions between the two different modalities is not an easy work. In contrast to struggling on multimodal feature fusion, in this paper, we propose to unify all the input information by natural language so as to convert VQA into a machine reading comprehension problem. With this transformation, our method not only can tackle VQA datasets that focus on observation based questions, but can also be naturally extended to handle knowledge-based VQA which requires to explore large-scale external knowledge base. It is a step towards being able to exploit large volumes oftext and natural language processing techniques to address VQA problem. Two types of models are proposed to deal with open-ended VQA and multiple-choice VQA respectively. We evaluate our models on three VQA benchmarks. The comparable performance with the state-of-the- art demonstrates the effectiveness ofthe proposed method.
VQA需要同时理解图片内容和自然语言问题,某些情况下还需要使用外部知识。当前的方法大多数都是将视觉信息和文本特征在同一个空间中融合,这并不是一件容易的工作,因此,作者提出将所有的输入信息通过自然语言表达,将VQA任务转换成机器阅读理解的问题。通过这种转换,不仅可以处理VQA中目标检测的问题,还可以处理需要大量外部知识库的VQA数据集。这种方法可以利用大量的文本和自然语言处理技术来处理VQA问题。作者针对开放式VQA问题和多选择式VQA问题提出了两种不同的方法。在三个VQA基准进行评估,比较结果表明提出的这种方法具有高效性。
背景:
介绍:
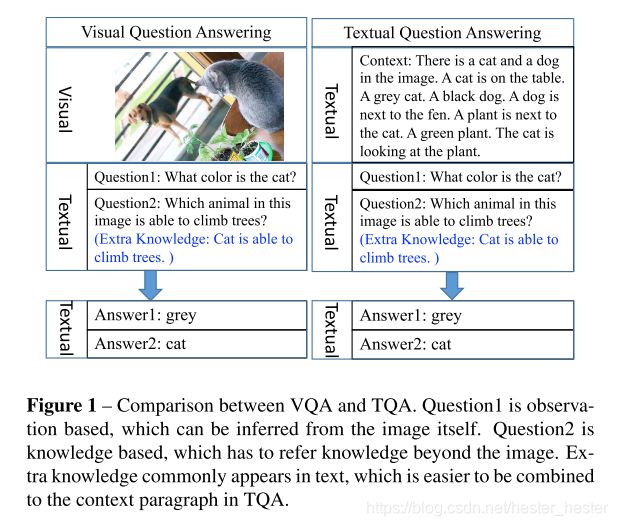
VQA是一个新兴的问题,要求算法根据图像回答自然语言问题,在计算机视觉和自然语言处理领域有着很好的应用前景。某种程度上来说,VQA和TQA任务很相近,但是VQA因为引入了视觉信息变得更有挑战性。
大多数的VQA都使用CNN来表示图像信息,使用RNN来表示句子或者段落,提取视觉和文本特征向量通过串联、逐元素求和或者点乘的融合嵌入方式推断答案。Fukui等人指出这种方法过于简单不能充分表示两种不同模态之间复杂的关系,因此他们提出了MCB。如果把额外的知识用于推理,会变得更加复杂,因此Li等人提出一个将外部知识到记忆槽中,并通过DMN将外部知识和图片、问题和答案特征进行合并的方法。
和图像特征相比,自然语言具有更高的抽象性和较全面的语义信息,因此两种模态在文本领域进行融合,通过这种转换,能更好地保留VQA关注地核心内容,使推理过程也更具有可解释性。
主要贡献:
1) We propose a new thought of solving VQA problem. Instead of integrating feature vectors from different modalities, we represent image content explicitly by natural language and solve VQA as reading comprehension. Thus we can resort to the abundant research results in NLP community to handle VQA problem. Using text and NLP techniques allows convenient access to higher-level information, and enables transfer learning from TQA to VQA models. Text data is more easier to be collected than images. Our method makes it possible to exploit large volumes of text in understanding images, actions, and commands. 将图像内容通过自然语言表示,将VQA任务作为阅读理解。
2) Two types of VQA models are proposed to address the open-end VQA and the multiple-choice VQA respectively. Based on the converted text description and the attention mechanism used in the models, semantic level supporting facts can be retrieved from the context, which makes the answer inferring process human-readable. The proposed models show comparable performance with the state-of-the-art on three different types of VQA datasets, which demonstrates their feasibility and effectiveness. 提出两种VQA模型分别处理开放式和多选择式地VQA任务。
3) Most VQA methods cannot handle knowledge based VQA or have poor performance because of the complicated knowledge embedding. In contrast, our method can be easily extended to address knowledge based VQA.能够更容易地处理需要外部知识地VQA任务。
相关工作:
联合嵌入(Joint embedding):
当前的方法大多数都是整合图像和文本特征,通常使用向量串联、逐元素求和或者点乘,Fukui等人认为该方法较简单不能表示足够的信息,提出了MCB,但是MCB首先需要将图像和文本特征映射到一个高维空间,再通过快速傅里叶变换进行逐元素点乘,之后MLB(Multimodal Low-rank Bilinear pooling)、MFB(Multimodal Factorized Bilinear pooling)和MRN(Multimodal Residual Networks)都相继提出,做了一些改进,因此可以发现怎样融合多模态信息式VQA任务的关键。
基于知识的VQA(Knowledge-based VQA):
在NLP领域有一些利用语义分析或者信息检索合并外部知识来回答问题的研究,但是这些都是基于文本特征,当输入换成了无结构的图像特征,就变得有些难度。目前有很多针对这些问题提出的解决办法,但是都会有其它的问题产生,比如没有结构化表示、应用受限制、容易引起同形异义词的误解等。因此,作者提出了一种更简单的处理外部知识库VQA任务的方法,就是在自然语言空间中整合图像-问题-答案-事实元组,使用NLP中阅读理解的技术进行处理。
文本问答(Textual Question Answering):
TQA的目标是基于段落回答问题,是NLP领域的基石。由于使用端到端神经网络和注意力机制,TQA在近几年有了显著的进步,例如DMN,r-net,DrQA,QANet,和最近出现的BERT,在解决VQA问题时,有很多固有的QA技术,比如注意力机制,DMN等。这里作者基于QANet尝试解决VQA问题。
VQA模型:
QANet:
QANet是TQA中一个快速、准确的端到端模型,包含嵌入模块(embedding block)、嵌入编码器(embedding encoder)、语境-问题注意力模块(context-query attention block)、模型编码器(model encoder)和输出层(output layer)。
输入嵌入模块(Input Embedding Block):对文本和问题中的单词嵌入成向量,每一个单词的表示是单词嵌入和特征嵌入的串联,这里使用两层高速网络来获取嵌入特征。
嵌入编码器模块(Embedding Encoder Block):由卷积层、自注意力层、前馈层和归一化层组成,并采用深度可分离卷积提高记忆和泛化能力,采用多头注意力机制对全局交互进行建模。

语境-问题注意力模块(Context-question Attention Block):用于提取更多内容和疑问词之间的相关特征,模型中包含语境-问题注意力(context-to-question attention)和问题-语境注意力(question-to-context attention)两种注意力机制。
模型编码器模块(Model Encoder Block):使用语境-问题注意力模块的结果作为输入,与嵌入编码器模块共享参数。
输入层(Output Layer):根据模型编码器的3次重复输出,预测上下文每个位置是答案的概率。
开放VQA模型(Open-ended VQA model):
除了QANet使用的基本模块以外,还添加了另一个输入预处理模块,并修改了输出模块,以适应于开放式VQA:

预处理模块(pre-processing block)包含图像描述模块(image description module)和外部知识检索模块(external knowledge retrieval module)。
图像描述模块的目的是通过文本段表示图像信息,使用了Dense captions模型,对图像内容提供一个精细的语义表示,从单个对象的属性(颜色、形状等)到对象之间的相互关系(空间位置等)。目前已有类似的工作,有的文献中使用256个属性词汇作为图像表示,取得了比较好的效果。但是在这篇论文中作者使用了另一种语义信息方法,可以让结果做得更好。将生成的区域字母组合在一起QANet的输入,由于使用了自注意力,该模型在长期依赖编码方面比通常使用的RNN做的要好。
当VQA需要的知识超出了图像范围,就需要外部知识检索模块,需要从大范围的知识库中提取相关信息而忽略无关信息。这采用了关键字匹配技术(keyword matching technique),相比于启发式匹配方法(heuristic matching approach),关键字匹配技术更不易受同形异义词或者同义词的影响,并能利用检索到的所有知识作为语境上下文。将图像信息和检索到的外部知识使用自然语言表示,再进行串联,最后输入到QANet中进行编码,寻找语境上下文和问题的相关性,进行预测答案。
输出层也有特定的任务,如果答案包含在文本段中,可以继续使用QANet定位答案出现的位置,然而,如果答案没有明确的显示在上下文中,例如通常很难判断“when”“why”这种问题。为了解决这个问题,作者提出将输出层构建为一个多类分类层,并根据三个模型编码器的输出特征M0,M1,M2来进行预定义答案的概率预测。首先经过平均池化层,然后将得到的特征向量串联起来,投影到答案类别的输出空间中,计算概率,最后使用交叉熵对模型进行训练。
多选择VQA模型(Multiple-choice VQA model Multiple-choice):
可以根据开放式VQA模型的结果与代选项进行匹配,但是这种方法不能充分利用所提供的信息,因此作者做了一些改进,提出了多选择VQA模型。

除了问题和图像描述,模型将候选答案也作为输入,计算候选答案和语境上下文的交互性。之后在串联的特征上使用多层感知机(MLP)进行训练。第一层使用概率为0.5的dropout,再使用sigmoid函数将特征转换为概率,最后使用二元逻辑损失对模型进行训练。
和开放式VQA模型选取频率最高的答案去掉出现较少的答案相比,多选择VQA模型直接对候选答案进行编码,答案范围更广,另外,对于比较相似的答案,多选择VQA模型可以通过嵌入和编码来学习相似语句的相似度,此外,它避免了将相似答案作为不同的类进行学习。
实验(Experiments):
数据集(Datasets):
FVQA(基于事实的VQA)不仅提供了图像-问题-答案的元组,也对每个视觉概念收集了外部知识,提取比较重要的视觉概念,从DBPedia,ConceptNet,We- bChild中进行查询并构建了一个大型的知识库。
Visual Genome是一个有着丰富的图片和语言的数据集,包含了108077张图片和1445233个问题答案对。
Visual7W是Visual Genome的一个子集,专门针对于VQA任务,包含了47300张图片和139868个问题答案对。
实验细节(Implementation Details FVQA):
FVQA需要使用外部知识,这里作者提出使用QQ映射法(question-to- query(QQ) mapping method),所有的事实信息都合并到一个段落里。QANet使用默认参数直接预测答案在段落中的位置,并进行微调,预训练使用SQuAD数据集。该模型前10个epoch使用0.001的学习率,后面10个0.0001。
Visual Genome提供了区域描述的真值,作者重新训练了模型,选取前5000个频率最高的答案作为开放式VQA模型的分类标签,为了快速训练,限制段落长度为500个单词,并在编码模块使用4个attention head。模型使用ADAM进行优化,初始学习率为0.001,后边每3个epoch衰减0.8直到降为0.0001。
Visual7W为每个问题提供了多个选项的答案,通常训练在多选项VQA模型中。
FVQA的结果分析(Results Analysis on FVQA):
作者使用答案准确度来评估模型,如果预测值能匹配上相应的正确答案,则认为预测是正确的。

下面是一些该模型在FVQA数据集的例子。

Visual Genome结果分析(Results Anslysis on Visual Genome QA (VGQA)):
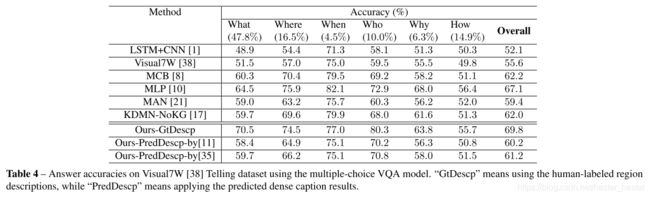
该模型在使用真值描述时获得了最佳性能,模型在“5W”上表现都不错,除了“What”以外,其中“Who”性能最好。这是因为回答“What”类型的问题主要考虑图像描述,而该模型主要考虑的是图像状态。

这里作者进行了简化实验来探究段落长度对实验结果的影响,可以发现随着长度的上升,准确率提升,但是计算速度会大大降低,因此折中取长度为500。

Visual7W结果分析(Results Analysis on Visual7W):
结果表明在真值描述性能较好,具体来说在“Who”类型问题中表现较好,“What”和“How”类型问题中性能相当,而在“When”和“Why”类型的问题性能不太好,这是因为这种问题在文本信息内描述较少。
下图是多选择VQA模型的一些例子。
