【Python学习笔记—保姆版】第四章—关于Pandas、数据准备、数据处理、数据分析、数据可视化
第四章
欢迎访问我搞事情的【知乎账号】:Coffee
以及我的【B站漫威剪辑账号】:VideosMan
若我的笔记对你有帮助,请用小小的手指,点一个大大的赞哦。
#编译器使用的是sypder,其中">>>"代表输入和执行的内容
>>> print(‘Hello World’) #执行代码
Hello World #输出值
【Python学习笔记—保姆版】第四章
- 第四章
- 1、关于Pandas
- 2、数据准备
-
- pandas和numpy
- 创建DataFrame
-
- 1.标准格式创建:
- 2 .传入等长的列表组成的字典来创建:
- **3 传入嵌套字典(字典的值也是字典)创建DataFrame**
- 增删改查
-
- 1.增加值
-
- 1.增加列。直接为不存在的列赋值就会创建新的列
- 2.增加行
- 3.删除行和列:axis代表选中的是行还是列,列是1,行是2.inplace代表有没有真正删除
- 改
- DataFrame
-
- 一、某列所有值
- 二、某行所有值
- 三、某行某列对应值df_signal[‘a’].iloc[-1]
- 四、删除特定行
- 五、**Python DataFrame 按条件筛选数据**
- 六、排序
- 数据导入
- 3、数据处理
-
- 4.3.1 数据清洗
-
- 1、重复值的处理:drop_duplicates()
- 2、缺失值处理:
-
- 1. dropna() 去除数据结构中值为空的数据行
- 2. df.fillna() 用其他数值替代NaN,有些时候空数据直接删除会影响分析的结果,可以对数据进行填补。【例4-8】使用数值或者任意字符替代缺失值
- 3. df.fillna(method='pad') 用前一个数据值替代NaN
- 4. df.fillna(method='bfill') 用后一个数据值替代NaN
- 5. df.fillna(df.mean()) 用平均数或者其他描述性统计量来代替NaN。
- 6. df.fillna(df.mean()[math: physical]) 可以选择列进行缺失值的处理
- 7. strip():清除字符型数据左右(首尾)指定的字符,默认为空格,中间的不清除。
- 3、特定值替换:replace('缺考', 0)
- 4、删除满足条件元素所在的行:drop()
- 4.3.2 数据抽取
-
- 1. 字段抽取:抽出某列上指定位置的数据做成新的列。
- 2. 字段拆分:按指定的字符sep,拆分已有的字符串。
- 3. 记录抽取:是指根据一定的条件,对数据进行抽取。
- 4. 随机抽样:是指随机从数据中按照一定的行数或者比例抽取数据。
- PS:按照指定条件抽取数据:
- 5. 字典数据:将字典数据抽取为dataframe,有三种方法。
- 4.3.3 排名索引
-
- 说明:axis、ascending、inplace、by
- **1. 排名排序(索引排序):df.sort_index()**
- 2.重新索引:.reindex(index=None,**kwargs)
- 3. 值排序:df.sort_values()
- **4、sort_values()中的na_position参数**
- 5、“值排名”:rank()函数
- 4.3.4 数据合并
-
- 1. 记录合并:是指两个结构相同的数据框合并成一个数据框。也就是在一个数据框中追加另一个数据框的数据记录。pd.concat([df1,df2])
- 2. 字段合并:是指将同一个数据框中的不同的列进行合并,形成新的列。X = x1+x2+…
- 3. 字段匹配:是指不同结构的数据框(两个或以上的数据框),按照一定的条件进行合并,即追加列。merge(x,y,left_on,right_on) 外键连接
- 4.3.5 数据计算
-
- 1. 简单计算:通过对各字段进行加、减、乘、除等四则算术运算,计算出的结果作为新的字段。
- 2. 数据标准化:是指将数据按照比例缩放,使之落入特定的区间,一般使用0-1标准化。X*=(x-min)/(max-min)
- 4.3.6 数据分组
-
- 说明:pd.cut(series,bins,right=True,labels=NULL)
- bins
- labels
- 4.3.7 日期处理
-
- 1. 日期转换:是指将字符型的日期格式转换为日期格式数据的过程。
- 2. 日期格式化:是指将日期型的数据按照给定的格式转化为字符型的数据。
- 3. 日期抽取:是指从日期格式里面抽取出需要的部分属性
- 4. 日期判断:
- 5.日期增长:
- 4、数据分析
-
- 4.4.1 基本统计:describe
- 4.4.2 分组分析:groupby(离散值分组)
- 4.4.3 分布分析:cut+groupby(连续值分组)
- 4.4.4 交叉分析:pivot_table(数据透视表)
- 4.4.5 结构分析:pivot_table+sum+div(查比重)
- 4.4.6 相关分析:corr(一维、二维)
- 5、数据可视化
-
- 相关注意
- 4.5.1 饼图:plt.pie(gb2.人数,labels=gb2.index,autopct='%.2f%%',colors=['b','pink',(0.5,0.8,0.3)],explode=[0,0,0,0,0.1])
- 4.5.2 散点图:plt.plot(df.高代,df.数分,'o',color='pink')
- 4.5.3 折线图:plt.plot(df.学号,df.总分,'-',color='r')
- 4.5.4 柱形图:plt.bar(df.学号后三位,df.总分,width=1,color=['r','b'])
- 4.5.5 直方图:plt.hist(df2.C语言程序设计,bins=10,color='g',cumulative=True)
- 这是我的线上笔记,希望对你有所帮助;你的点赞收藏,是我坚持的最大动力
1、关于Pandas
Pandas的中文网,介绍得非常详细
https://www.pypandas.cn/docs/
2、数据准备
pandas和numpy
import pandas as pd
import pandas as Series
import numpy as np
from pandas import DataFrame
-
pandas:生成数据框,处理数据框
import pandas as pdDataFrame、Series -
numpy:一些特殊的数值,可视化的使用
import numpy as np比如
方法 解释 np.nan 空值(缺失值) np.inf 无穷( -inf 或 +inf ) np.arange(16) 返回一个有终点和起点的固定步长的排列 np.random 生成随机数 np.array([1,2,3,4]) 返回一个自定义的排列 方法 效果 numpy.size 人数 numpy.mean 平均值 numpy.var 方差 numpy.std 标准差 numpy.max 最高分 numpy.min 最低分
创建DataFrame
1.标准格式创建:
>>> from pandas import DataFrame
>>> df = DataFrame(np.arange(16).reshape(4,4),index=['a','b','c','d'],columns =['one','two','three','four'])
>>> df
one two three four
a 0 1 2 3
b 4 5 6 7
c 8 9 10 11
d 12 13 14 15
2 .传入等长的列表组成的字典来创建:
>>> data = {'a':[5,8],'b':[1,0]}
>>> df = DataFrame(data)
>>> df
a b
0 5 1
1 8 0
同时也可以指定列索引序列
>>> df = DataFrame(data,columns = ['b','a'])
>>> df
b a
0 1 5
1 0 8
3 传入嵌套字典(字典的值也是字典)创建DataFrame
其中我们可以知道,外层键是列索引,内层子键是行索引
>>> nest_dict={'shanghai':{2015:100,2016:101},'beijing':{2015:102,2016:103}}
>>> df = DataFrame(nest_dict)
>>> df
shanghai beijing
2015 100 102
2016 101 103
>>> nest_dict={'shanghai':{2015:100,2016:101},'beijing':{2015:102,2014:103}}
>>> df = DataFrame(nest_dict)
>>> df
shanghai beijing
2014 NaN 103.0
2015 100.0 102.0
2016 101.0 NaN
增删改查
(1 封私信 / 4 条消息) dataframe修改某列的值 - 搜索结果 - 知乎 (zhihu.com)
(20条消息) pandas:dataframe在指定位置插入一行数据_碧海蓝天-CSDN博客_dataframe插入一行数据
(22条消息) Python中pandas dataframe删除一行或一列:drop函数_海晨威-CSDN博客_dataframe drop
1.增加值
1.增加列。直接为不存在的列赋值就会创建新的列
df['Hefei'] = 1 dfshanghai beijing Hefei
2014 NaN 103.0 1
2015 100.0 102.0 1
2016 101.0 NaN 1
2.增加行
利用loc方法,当然也可以使用append方法,不过传入的需要是字典形式。
>>> df.loc[4]={'shanghai':5,'beijing':13, 'Hefei':50}
>>> df
shanghai beijing Hefei
2014 NaN 103.0 1
2015 100.0 102.0 1
2016 101.0 NaN 1
4 5.0 13.0 50
>>> df.loc[2]={'shanghai':5,'beijing':13, 'Hefei':50}
>>> df
shanghai beijing Hefei
2014 NaN 103.0 1
2015 100.0 102.0 1
2016 101.0 NaN 1
4 5.0 13.0 50
2 5.0 13.0 50
3.删除行和列:axis代表选中的是行还是列,列是1,行是2.inplace代表有没有真正删除
>>> df.drop('Hefei',axis = 1,inplace = True)
>>> df
shanghai beijing
2014 NaN 103
2015 100 102
2016 101 NaN
4 5 13
2 5 13
3 5 13
df.drop(3,axis = 0,inplace = True)
>>> df
shanghai beijing
2014 NaN 103
2015 100 102
2016 101 NaN
4 5 13
2 5 13
改
改操作主要记住就是从列开始
>>> df
shanghai beijing
2014 6 6
2015 100 102
2016 101 NaN
4 5 13
2 5 13
>>> df[:3]
shanghai beijing
2014 6 6
2015 100 102
2016 101 NaN
>>> df[1] = 3
>>> df
shanghai beijing 1
2014 6 6 3
2015 100 102 3
2016 101 NaN 3
4 5 13 3
2 5 13 3
DataFrame
df.info(): # 打印摘要
df.describe(): # 描述性统计信息
df.values: # 数据 (推荐)
df.shape: # 形状 (行数, 列数)
df.columns: # 列标签 一、某列所有值
df['a']#取a列
df[['a','b']]#取a、b列
二、某行所有值
# 前n行,后n行
df.head(n)
df.tail(n)
#iloc只能用数字索引,不能用索引名------(左闭右开)
df.iloc[0:2]#前2行
df.iloc[0]#第0行
df.iloc[0:2,0:2]#0、1行,0、1列
df.iloc[[0,2],[1,2,3]]#第0、2行,1、2、3列
# 选取等于某些值的行记录 用 ==
df.loc[df['column_name'] == some_value]
# 选取某列是否是某一类型的数值 用 isin
df.loc[df['column_name'].isin(some_values)]
# 多种条件的选取 用 &
df.loc[(df['column'] == some_value) & df['other_column'].isin(some_values)]
# 选取不等于某些值的行记录 用 !=
df.loc[df['column_name'] != some_value]
# isin返回一系列的数值,如果要选择不符合这个条件的数值使用~
df.loc[~df['column_name'].isin(some_values)]
#提取出某行某列
li=list(df.columns)
df.iloc[[3,4,8],[li.index('animal'),li.index('age')]]
三、某行某列对应值df_signal[‘a’].iloc[-1]
#iat取某个单值,只能数字索引df.iat[1,1]#第1行,1列#at取某个单值,只能index和columns索引df.at[‘one’,‘a’]#one行,a列
四、删除特定行
# 要删除列“score”<50的所有行:
df = df.drop(df[df.score < 50].index)
df = df.drop(df[df['score'] < 50].index)
df.drop(df[df.score < 50].index, inplace=True)
df.drop(df[df['score'] < 50].index, inplace=True)
# 多条件情况
# 可以使用操作符: | 只需其中一个成立, & 同时成立, ~ 表示取反,它们要用括号括起来。
# 例如删除列“score<50 和>20的所有行
df = df.drop(df[(df.score < 50) & (df.score > 20)].index
五、Python DataFrame 按条件筛选数据
点击查看更多内容
比如我想查看id等于11396的数据。
pdata1[pdata1['id']==11396]
pdata1[pdata1.id==11396]
查看时间time小于25320的数据。
pdata1[pdata1['time']<25320]
pdata1[pdata1.time<25320]
查看time小于25320且大于等于25270的数据
pdata1[(pdata1['time'] < 25320)&(pdata1['time'] >= 25270)]
可以根据筛选条件查看某几列
pdata1[(pdata1['time'] < 25320)&(pdata1['time'] >= 25270)][['x','y']]
注意多个条件要加括号后在&或|。
六、排序
点击查看更多内容
#表示pd按照xxx这个字段排序,inplace默认为False,如果该值为False,那么原来的pd顺序没变,只是返回的是排序的
pd.sort_values("xxx",inplace=True)
数据导入
从excel导入
from pandas import read_excel
df = read_excel('e://rz2.xlsx')
df
从csv导入
from pandas import read_csv
path4 = 'C:\\Users\\admin\\Desktop\\大数据爬虫2\\合并\\主键外连接.csv'
df5 = read_csv(path4,engine='python')
3、数据处理
df3=pd.merge(df1,df2,left_on='学号',right_on='学号') #外键连接
df3=df3.drop(columns=['手机号码'])
df3
df3=df3.replace('缺考', 0) #特殊值代替
数据分析的第一步是提高数据质量。数据清洗要做的就是处理缺失数据以及清除无意义的信息。这是数据价值链中最关键的步骤。垃圾数据,即使是通过最好的分析,也将产生错误的结果,并误导业务本身。
4.3.1 数据清洗
1、重复值的处理:drop_duplicates()
drop_duplicates()
把数据结构中行相同的数据去除(保留其中的一行)
【例4-6】数据去重。
这里df是原始数据,其中7、9行、8、10行是重复行from pandas import DataFrame from pandas import read_excel df = read_excel('e://rz2.xlsx') dfOut[1]:
YHM TCSJ YWXT IP
0 S1402048 18922254812 1.225790e+17 221.205.98.55
1 S1411023 13522255003 1.225790e+17 183.184.226.205
2 S1402048 13422259938 NaN 221.205.98.55
3 20031509 18822256753 NaN 222.31.51.200
4 S1405010 18922253721 1.225790e+17 120.207.64.3
5 20140007 NaN 1.225790e+17 222.31.51.200
6 S1404095 13822254373 1.225790e+17 222.31.59.220
7 S1402048 13322252452 1.225790e+17 221.205.98.55
8 S1405011 18922257681 1.225790e+17 183.184.230.38
9 S1402048 13322252452 1.225790e+17 221.205.98.55
10 S1405011 18922257681 1.225790e+17 183.184.230.38
newDF=df.drop_duplicates() newDFOut[2]:
YHM TCSJ YWXT IP
0 S1402048 18922254812 1.225790e+17 221.205.98.55
1 S1411023 13522255003 1.225790e+17 183.184.226.205
2 S1402048 13422259938 NaN 221.205.98.55
3 20031509 18822256753 NaN 222.31.51.200
4 S1405010 18922253721 1.225790e+17 120.207.64.3
5 20140007 NaN 1.225790e+17 222.31.51.200
6 S1404095 13822254373 1.225790e+17 222.31.59.220
7 S1402048 13322252452 1.225790e+17 221.205.98.55
8 S1405011 18922257681 1.225790e+17 183.184.230.38
上面的df中第7和第9行数据相同,第8和第10行数据相同,去重后第7、9和8、10各保留一行数据。
2、缺失值处理:
dropna()、df.fillna() 、df.fillna(method=‘pad’)、df.fillna(method=‘bfill’)、df.fillna(df.mean())、df.fillna(df.mean()[math: physical]) 、strip()
对于缺失数据的处理方式有数据补齐、删除对应行、不处理等方法。
【例4-6】缺失处理。
这里df是原始数据,其中2、3、5行有缺失值from pandas import DataFrame from pandas import read_excel df = read_excel('e://rz2.xlsx') dfOut[1]:
YHM TCSJ YWXT IP
0 S1402048 18922254812 1.225790e+17 221.205.98.55
1 S1411023 13522255003 1.225790e+17 183.184.226.205
2 S1402048 13422259938 NaN 221.205.98.55
3 20031509 18822256753 NaN 222.31.51.200
4 S1405010 18922253721 1.225790e+17 120.207.64.3
5 20140007 NaN 1.225790e+17 222.31.51.200
6 S1404095 13822254373 1.225790e+17 222.31.59.220
7 S1402048 13322252452 1.225790e+17 221.205.98.55
8 S1405011 18922257681 1.225790e+17 183.184.230.38
9 S1402048 13322252452 1.225790e+17 221.205.98.55
10 S1405011 18922257681 1.225790e+17 183.184.230.38
1. dropna() 去除数据结构中值为空的数据行
【例4-7】删除数据为空所对应的行
from pandas import DataFrame from pandas import read_excel df = read_excel('e://rz2.xlsx') newDF=df.dropna() newDFOut[3]:
YHM TCSJ YWXT IP
0 S1402048 18922254812 1.225790e+17 221.205.98.55
1 S1411023 13522255003 1.225790e+17 183.184.226.205
4 S1405010 18922253721 1.225790e+17 120.207.64.3
6 S1404095 13822254373 1.225790e+17 222.31.59.220
7 S1402048 13322252452 1.225790e+17 221.205.98.55
8 S1405011 18922257681 1.225790e+17 183.184.230.38
9 S1402048 13322252452 1.225790e+17 221.205.98.55
10 S1405011 18922257681 1.225790e+17 183.184.230.38
例中的2、3、5行有空值NaN已经被删除。
2. df.fillna() 用其他数值替代NaN,有些时候空数据直接删除会影响分析的结果,可以对数据进行填补。【例4-8】使用数值或者任意字符替代缺失值
【例4-8】使用数值或者任意字符替代缺失值
from pandas import DataFrame from pandas import read_excel df = read_excel('e://rz2.xlsx') df.fillna('?')Out[4]:
YHM TCSJ YWXT IP DLSJ
0 S1402048 1.89223e+10 1.22579e+17 221.205.98.55 2014-11-04 08:44:46
1 S1411023 1.35223e+10 1.22579e+17 183.184.226.205 2014-11-04 08:45:06
2 S1402048 1.34223e+10 ? 221.205.98.55 2014-11-04 08:46:39
3 20031509 1.88223e+10 ? 222.31.51.200 2014-11-04 08:47:41
4 S1405010 1.89223e+10 1.22579e+17 120.207.64.3 2014-11-04 08:49:03
5 20140007 ? 1.22579e+17 222.31.51.200 2014-11-04 08:50:06
6 S1404095 1.38223e+10 1.22579e+17 222.31.59.220 2014-11-04 08:50:02
7 S1402048 1.33223e+10 1.22579e+17 221.205.98.55 2014-11-04 08:49:18
8 S1405011 1.89223e+10 1.22579e+17 183.184.230.38 2014-11-04 08:14:55
9 S1402048 1.33223e+10 1.22579e+17 221.205.98.55 2014-11-04 08:49:18
10 S1405011 1.89223e+10 1.22579e+17 183.184.230.38 2014-11-04 08:14:55
如2、3、5行有空,用?替代了缺失值。
3. df.fillna(method=‘pad’) 用前一个数据值替代NaN
【例4-9】用前一个数据值替代缺失值
(2、3、5行是缺失值)from pandas import DataFrame from pandas import read_excel df = read_excel('e://rz2.xlsx') df.fillna(method='pad')Out[5]:
YHM TCSJ YWXT IP DLSJ
0 S1402048 18922254812 1.225790e+17 221.205.98.55 2014-11-04 08:44:46
1 S1411023 13522255003 1.225790e+17 183.184.226.205 2014-11-04 08:45:06
2 S1402048 13422259938 1.225790e+17 221.205.98.55 2014-11-04 08:46:39
3 20031509 18822256753 1.225790e+17 222.31.51.200 2014-11-04 08:47:41
4 S1405010 18922253721 1.225790e+17 120.207.64.3 2014-11-04 08:49:03
5 20140007 18922253721 1.225790e+17 222.31.51.200 2014-11-04 08:50:06
6 S1404095 13822254373 1.225790e+17 222.31.59.220 2014-11-04 08:50:02
7 S1402048 13322252452 1.225790e+17 221.205.98.55 2014-11-04 08:49:18
8 S1405011 18922257681 1.225790e+17 183.184.230.38 2014-11-04 08:14:55
9 S1402048 13322252452 1.225790e+17 221.205.98.55 2014-11-04 08:49:18
10 S1405011 18922257681 1.225790e+17 183.184.230.38 2014-11-04 08:14:55
4. df.fillna(method=‘bfill’) 用后一个数据值替代NaN
【例4-10】用后一个数据值替代NaN
(2、3、5行是缺失值)from pandas import DataFrame from pandas import read_excel df = read_excel('e://rz2.xlsx') df.fillna(method='bfill')Out[6]:
YHM TCSJ YWXT IP DLSJ
0 S1402048 18922254812 1.225790e+17 221.205.98.55 2014-11-04 08:44:46
1 S1411023 13522255003 1.225790e+17 183.184.226.205 2014-11-04 08:45:06
2 S1402048 13422259938 1.225790e+17 221.205.98.55 2014-11-04 08:46:39
3 20031509 18822256753 1.225790e+17 222.31.51.200 2014-11-04 08:47:41
4 S1405010 18922253721 1.225790e+17 120.207.64.3 2014-11-04 08:49:03
5 20140007 13822254373 1.225790e+17 222.31.51.200 2014-11-04 08:50:06
6 S1404095 13822254373 1.225790e+17 222.31.59.220 2014-11-04 08:50:02
7 S1402048 13322252452 1.225790e+17 221.205.98.55 2014-11-04 08:49:18
8 S1405011 18922257681 1.225790e+17 183.184.230.38 2014-11-04 08:14:55
9 S1402048 13322252452 1.225790e+17 221.205.98.55 2014-11-04 08:49:18
10 S1405011 18922257681 1.225790e+17 183.184.230.38 2014-11-04 08:14:55
5. df.fillna(df.mean()) 用平均数或者其他描述性统计量来代替NaN。
【例4-11】使用均值来填补数据。
from pandas import DataFrame from pandas import read_excel df = read_excel('e://rz2_0.xlsx') df df.fillna(df.mean())Out[7]:
No math physical Chinese
0 1 76 85 78
1 2 85 56 NaN
2 3 76 95 85
3 4 NaN 75 58
4 5 87 52 68Out[8]:
No math physical Chinese
0 1 76 85 78.00
1 2 85 56 72.25
2 3 76 95 85.00
3 4 81 75 58.00
4 5 87 52 68.00
6. df.fillna(df.mean()[math: physical]) 可以选择列进行缺失值的处理
【例4-12】为某列使用该列的均值来填补数据
from pandas import DataFrame from pandas import read_excel df = read_excel('e://rz2_0.xlsx') df.fillna(df.mean()['math':'physical'])Out[26]:
No math physical Chinese
0 1 76.0 85 78.0
1 2 85.0 56 NaN
2 3 76.0 95 85.0
3 4 NaN 75 58.0
4 5 87.0 52 68.0Out[9]:
No math physical Chinese
0 1 76 85 78
1 2 85 56 NaN
2 3 76 95 85
3 4 81 75 58
4 5 87 52 68
7. strip():清除字符型数据左右(首尾)指定的字符,默认为空格,中间的不清除。
【例4-13】删除字符串左右或首位指定的字符。
from pandas import DataFrame from pandas import read_excel df = read_excel('e://rz2.xlsx') newDF=df['IP'].str.strip() #因为IP是一个对象,所以先转为str。 newDFOut[27]:
YHM TCSJ YWXT IP DLSJ
0 S1402048 18922254812.0 1.2257903137349373e+17 221.205.98.55 2014-11-04 08:44:46
1 S1411023 13522255003.0 1.2257903137349373e+17 183.184.226.205 2014-11-04 08:45:06
2 S1402048 13422259938.0 221.205.98.55 2014-11-04 08:46:39
3 20031509 18822256753.0 222.31.51.200 2014-11-04 08:47:41
4 S1405010 18922253721.0 1.2257903137349373e+17 120.207.64.3 2014-11-04 08:49:03
5 20140007 1.2257903137349373e+17 222.31.51.200 2014-11-04 08:50:06
6 S1404095 13822254373.0 1.2257903137349373e+17 222.31.59.220 2014-11-04 08:50:02
7 S1402048 13322252452.0 1.2257903137349373e+17 221.205.98.55 2014-11-04 08:49:18
8 S1405011 18922257681.0 1.2257903137349373e+17 183.184.230.38 2014-11-04 08:14:55
9 S1402048 13322252452.0 1.2257903137349373e+17 221.205.98.55 2014-11-04 08:49:18
10 S1405011 18922257681.0 1.2257903137349373e+17 183.184.230.38 2014-11-04 08:14:55Out[10]:
0 221.205.98.55
1 183.184.226.205
2 221.205.98.55
3 222.31.51.200
4 120.207.64.3
5 222.31.51.200
6 222.31.59.220
7 221.205.98.55
8 183.184.230.38
9 221.205.98.55
10 183.184.230.38
Name: IP, dtype: object
3、特定值替换:replace(‘缺考’, 0)
df11 = df11.replace(np.nan,'[正常]')
df11 = df11.replace('none',np.nan)
df11 = df11.replace(' ― ',np.nan)
4、删除满足条件元素所在的行:drop()
df = df.drop(df[].index)
#删除价格大于1000的手机
df_s_acc = df_s.drop(df_s[df_s['价格']>=1000].index)Out[68]:
Unnamed: 0 ID值 价格 … 标签 变更 规范日期
5566 6626 1354676 699 … 安全手机 2020/11/1 2020-11-01
5565 6625 1354673 799 … 安全手机 2020/11/1 2020-11-01
101 102 1346463 2699 … 安全手机 2020/11/11 2020-11-11
64 64 1338710 3199 … 安全手机 2020/11/11 2020-11-11
2884 3382 1352445 1499 … 安全手机 2020/11/26 2020-11-26
2892 3391 1349515 1099 … 安全手机 2020/11/26 2020-11-26
2910 3411 1349516 1299 … 安全手机 2020/11/26 2020-11-26
2844 3340 1348871 999 … 安全手机 2020/11/26 2020-11-26
4046 4845 1350884 799 … 安全手机 2020/12/1 2020-12-01
4036 4834 1350882 699 … 安全手机 2020/12/1 2020-12-01
3394 4023 1349976 799 … 安全手机 2020/12/12 2020-12-12
4740 5656 1353088 2399 … 安全手机 2020/12/22 2020-12-22
4737 5653 1353068 1999 … 安全手机 2020/12/22 2020-12-22
4048 4847 1357947 1099 … 安全手机 2021/1/1 2021-01-01
4038 4836 1357933 999 … 安全手机 2021/1/1 2021-01-01
4043 4842 1357949 1199 … 安全手机 2021/1/1 2021-01-01Out[72]:
Unnamed: 0 ID值 价格 … 标签 变更 规范日期
5566 6626 1354676 699 … 安全手机 2020/11/1 2020-11-01
5565 6625 1354673 799 … 安全手机 2020/11/1 2020-11-01
2844 3340 1348871 999 … 安全手机 2020/11/26 2020-11-26
4046 4845 1350884 799 … 安全手机 2020/12/1 2020-12-01
4036 4834 1350882 699 … 安全手机 2020/12/1 2020-12-01
3394 4023 1349976 799 … 安全手机 2020/12/12 2020-12-12
4038 4836 1357933 999 … 安全手机 2021/1/1 2021-01-01
也可以使用多个条件
df_clear = df.drop(df[df['x']<0.01].index)
# 也可以使用多个条件
df_clear = df.drop(df[(df['x']<0.01) | (df['x']>10)].index) #删除x小于0.01或大于10的行
4.3.2 数据抽取
1. 字段抽取:抽出某列上指定位置的数据做成新的列。
slice(start,stop)
start 开始位置; stop 结束位置
【例4-14】从数据中抽出某列。
from pandas import DataFrame from pandas import read_excel df = read_excel('e://rz2.xlsx') df['TCSJ']=df['TCSJ'].astype(str) #astype()转化类型 df['TCSJ'] bands = df['TCSJ'].str.slice(0,3) bandsOut[1]:
0 18922254812
1 13522255003
2 13422259938
3 18822256753
4 18922253721
5 nan
6 13822254373
7 13322252452
8 18922257681
9 13322252452
10 18922257681
Name: TCSJ, dtype: objectOut[2]:
0 189
1 135
2 134
3 188
4 189
5 nan
6 138
7 133
8 189
9 133
10 189
Name: TCSJ, dtype: object
2. 字段拆分:按指定的字符sep,拆分已有的字符串。
split(sep,n,expand=False)
sep 用于分隔字符串的分隔符
n 分割后新增的列数
expand 是否展开为数据框,默认为False
返回值:expand为True,返回DaraFrame;False返回Series。
【原始数据】
YHM TCSJ YWXT IP DLSJ
0 S1402048 18922254812.0 1.2257903137349373e+17 221.205.98.55 2014-11-04 08:44:46
1 S1411023 13522255003.0 1.2257903137349373e+17 183.184.226.205 2014-11-04 08:45:06
2 S1402048 13422259938.0 221.205.98.55 2014-11-04 08:46:39
3 20031509 18822256753.0 222.31.51.200 2014-11-04 08:47:41
4 S1405010 18922253721.0 1.2257903137349373e+17 120.207.64.3 2014-11-04 08:49:03
5 20140007 1.2257903137349373e+17 222.31.51.200 2014-11-04 08:50:06
6 S1404095 13822254373.0 1.2257903137349373e+17 222.31.59.220 2014-11-04 08:50:02
7 S1402048 13322252452.0 1.2257903137349373e+17 221.205.98.55 2014-11-04 08:49:18
8 S1405011 18922257681.0 1.2257903137349373e+17 183.184.230.38 2014-11-04 08:14:55
9 S1402048 13322252452.0 1.2257903137349373e+17 221.205.98.55 2014-11-04 08:49:18
10 S1405011 18922257681.0 1.2257903137349373e+17 183.184.230.38 2014-11-04 08:14:55
【例4-15】拆分字符串为指定的列数
from pandas import DataFrame from pandas import read_excel df = read_excel('e://rz2.xlsx') newDF=df['IP'].str.strip() #IP先转为str,再删除首位空格 newDF= df['IP'].str.split('.',1,True)#按第一个"."分成两列,1表示新增的列数 newDFOut[1]:
0 1
0 221 205.98.55
1 183 184.226.205
2 221 205.98.55
3 222 31.51.200
4 120 207.64.3
5 222 31.51.200
6 222 31.59.220
7 221 205.98.55
8 183 184.230.38
9 221 205.98.55
10 183 184.230.38
newDF.columns = ['IP1','IP2-4'] #给第一第二列增加列名称 newDFOut[2]:
IP1 IP2-4
0 221 205.98.55
1 183 184.226.205
2 221 205.98.55
3 222 31.51.200
4 120 207.64.3
5 222 31.51.200
6 222 31.59.220
7 221 205.98.55
8 183 184.230.38
9 221 205.98.55
10 183 184.230.38
3. 记录抽取:是指根据一定的条件,对数据进行抽取。
dataframe[condition]
condition:过滤条件
返回值:DataFrame
常用的condition类型:
比较运算:<、>、>=、<=、!=,如:
df[df.comments>10000)];
范围运算:between(left,right),如:
df[df.comments.between(1000,10000)];
空置运算:pandas.isnull(column) ,如:
df[df.title.isnull()];
字符匹配:str.contains(patten,na = False) ,如:
df[df.title.str.contains(‘电台’,na=False)]
逻辑运算:&(与),|(或),not(取反);如:
df[(df.comments>=1000)&(df.comments<=10000)] 与 df[df.comments.between(1000,10000)]等价。
【原始数据】同上
【例4-16】按条件抽取数据。
import pandas from pandas import read_excel df = read_excel('e://rz2.xlsx') df[df.TCSJ==13322252452]Out[2]:
YHM TCSJ YWXT IP
7 S1402048 13322252452 1.225790e+17 221.205.98.55
9 S1402048 13322252452 1.225790e+17 221.205.98.55df[df.TCSJ>13500000000]Out[3]:
YHM TCSJ YWXT IP DLSJ
0 S1402048 18922254812 1.225790e+17 221.205.98.55 2014-11-04 08:44:46
1 S1411023 13522255003 1.225790e+17 183.184.226.205 2014-11-04 08:45:06
3 20031509 18822256753 NaN 222.31.51.200 2014-11-04 08:47:41
4 S1405010 18922253721 1.225790e+17 120.207.64.3 2014-11-04 08:49:03
6 S1404095 13822254373 1.225790e+17 222.31.59.220 2014-11-04 08:50:02
8 S1405011 18922257681 1.225790e+17 183.184.230.38 2014-11-04 08:14:55
10 S1405011 18922257681 1.225790e+17 183.184.230.38 2014-11-04 08:14:55df[df.TCSJ.between(13400000000,13999999999)]Out[4]:
YHM TCSJ YWXT IP DLSJ
1 S1411023 13522255003 1.225790e+17 183.184.226.205 2014-11-04 08:45:06
2 S1402048 13422259938 NaN 221.205.98.55 2014-11-04 08:46:39
6 S1404095 13822254373 1.225790e+17 222.31.59.220 2014-11-04 08:50:02df[df.YWXT.isnull()]Out[5]:
YHM TCSJ YWXT IP DLSJ
2 S1402048 13422259938 NaN 221.205.98.55 2014-11-04 08:46:39
3 20031509 18822256753 NaN 222.31.51.200 2014-11-04 08:47:41df[df.IP.str.contains('222.',na=False)]Out[6]:
YHM TCSJ YWXT IP DLSJ
3 20031509 18822256753 NaN 222.31.51.200 2014-11-04 08:47:41
5 20140007 NaN 1.225790e+17 222.31.51.200 2014-11-04 08:50:06
6 S1404095 13822254373 1.225790e+17 222.31.59.220 2014-11-04 08:50:02
4. 随机抽样:是指随机从数据中按照一定的行数或者比例抽取数据。
随机抽样函数:
numpy.random.randint(start,end,num)
start:范围的开始值;
end:范围的结束值;
num:抽样个数
返回值:行的索引值序列
【原始数据】同上
【例4-17】随机抽取数据。
import numpy import pandas from pandas import read_excel df = read_excel('e://rz2.xlsx’) dfOut[1]:
YHM TCSJ YWXT IP DLSJ
0 S1402048 18922254812 1.225790e+17 221.205.98.55 2014-11-4 8:44
1 S1411023 13522255003 1.225790e+17 183.184.226.205 2014-11-4 8:45
2 S1402048 13422259938 NaN 221.205.98.55 2014-11-4 8:46
3 20031509 18822256753 NaN 222.31.51.200 2014-11-4 8:47
4 S1405010 18922253721 1.225790e+17 120.207.64.3 2014-11-4 8:49
5 20140007 NaN 1.225790e+17 222.31.51.200 2014-11-4 8:50
6 S1404095 13822254373 1.225790e+17 222.31.59.220 2014-11-4 8:50
7 S1402048 13322252452 1.225790e+17 221.205.98.55 2014-11-4 8:49
8 S1405011 18922257681 1.225790e+17 183.184.230.38 2014-11-4 8:14
9 S1402048 13322252452 1.225790e+17 221.205.98.55 2014-11-4 8:49
10S1405011 18922257681 1.225790e+17 183.184.230.38 2014-11-4 8:14r = numpy.random.randint(0,10,3) rOut[2]: array([8, 2, 9])
df.loc[r,:] #抽取r行数据Out[3]:
YHM TCSJ YWXT IP DLSJ
8 S1405011 18922257681 1.225790e+17 183.184.230.38 2014-11-04 08:14:55
2 S1402048 13422259938 NaN 221.205.98.55 2014-11-04 08:46:39
9 S1402048 13322252452 1.225790e+17 221.205.98.55 2014-11-04 08:49:18
PS:按照指定条件抽取数据:
1)使用index标签选取数据:df.loc[行标签,列标签]
df.loc[‘a’:‘b’] #选取ab两行之间的数据,假设a,b为行索引
df.loc[:,'TCSJ'] #选取TCSJ列的数据
df.loc的第一个参数是行标签,第二个参数为列标签(可选参数,默认为所有列标签),两个参数既可以是列表也可以是单个字符,如果两个参数都为列表则返回的是DataFrame,否则为Series。
按照指定条件抽取数据:
2)使用切片位置选取数据:df.iloc[行位置,列位置] #iloc只能用数字索引,不能用索引名------(左闭右开)
df.iloc[1,1] #选取第二行,第二列的值,返回的为单个值
df.iloc[[0,2],:] #选取第一行和第三行的数据
df.iloc[0:2,:] #选取第一行到第三行(不包含)的数据
df.iloc[:,1] #选取所有记录的第一列的值,返回的为一个Series
df.iloc[1,:] #选取第一行数据,返回的为一个Series
说明:loc为location的缩写,iloc则为integer & location的缩写。更广义的切片方式是使用 .ix,它自动根据给到的索引类型判断是使用位置还是标签进行切片。即:iloc为整型索引;loc为字符串索引; ix是 iloc和 loc的合体。
Python默认的行序号是从0开始,我们称为行位置;但实际上0开始的行我们在计数时为第1行,也称为行号,是从1开始;有时index是被命名的,如’one’,‘two’,‘three’,‘four’或’a’,‘b’,‘c’,'d’等字符串,我们称之为标签。loc索引的是行号、标签,不是行位置,如下例中df2.loc[1]索引的是第一行(行号为1),其实位置为0行;iloc索引的是位置,不能是标签或行号;ix则三者皆可。
import pandas as pd index_loc = ['a','b'] index_iloc = [1,2] data = [[1,2,3,4],[5,6,7,8]] columns = ['one','two','three','four'] df1 = pd.DataFrame(data=data,index=index_loc,columns=columns) df2 = pd.DataFrame(data=data,index=index_iloc,columns=columns) print(df1.loc['a'])one 1
two 2
three 3
four 4
Name: a, dtype: int64print(df1.iloc['a']) #iloc不能索引字符串Traceback (most recent call last):
TypeError: cannot do label indexing onwith these indexers [a] of print(df2.iloc[1]) #iloc索引的是行位置 print(df2.loc[1]) #loc[1]索引的是行号,的对应的行位置为0行 print(df1.ix[0]) print(df1.ix['a'])Out[0]:
one 5
two 6
three 7
four 8
Name: 2, dtype: int64Out[1]:
one 1
two 2
three 3
four 4
Name: 1, dtype: int64Out[2]:
one 1
two 2
three 3
four 4
Name: a, dtype: int64Out[3]:
one 1
two 2
three 3
four 4
Name: a, dtype: int64
3)通过逻辑指针进行数据切片:df[逻辑条件]
df[df. TCSJ >= 18822256753] #单个逻辑条件 df[(df. TCSJ >=13422259938 )&(df. TCSJ < 13822254373)] #多个逻辑条件组合 这种方式获取的数据切片都是DataFrame。 df[df.TCSJ >= 18822256753]Out[14]:
YHM TCSJ YWXT IP DLSJ
0 S1402048 18922254812 1.225790e+17 221.205.98.55 2014-11-04 08:44:46
3 20031509 18822256753 NaN 222.31.51.200 2014-11-04 08:47:41
4 S1405010 18922253721 1.225790e+17 120.207.64.3 2014-11-04 08:49:03
8 S1405011 18922257681 1.225790e+17 183.184.230.38 2014-11-04 08:14:55
10 S1405011 18922257681 1.225790e+17 183.184.230.38 2014-11-04 08:14:55
5. 字典数据:将字典数据抽取为dataframe,有三种方法。
import pandas from pandas import DataFrame #1.字典的key和value各作为一列 d1={‘a':'[1,2,3]','b':'[0,1,2]'} a1=pandas.DataFrame.from_dict(d1, orient='index’) #将字典转化为dataframe,且key列做成了index a1.index.name = 'key' #将index的列名改成‘key’ b1=a1.reset_index() #重新增加index,并将原index做成了‘key’列 b1.columns=['key','value'] #对列重新命名为'key'和'value' b1Out[1]:
key value
0 b [0,1,2]
1 a [1,2,3]#2.字典里的每一个元素作为一列(同长) d2={'a':[1,2,3],'b':[4,5,6]} #字典的value必须长度相等 a2= DataFrame(d2) a2Out[2]:
a b
0 1 4
1 2 5
2 3 6#3.字典里的每一个元素作为一列(不同长) d = {'one' : pandas.Series([1, 2, 3]),'two' : pandas.Series([1, 2, 3, 4])} #字典的value长度可以不相等 df = pandas.DataFrame(d) dfOut[3]:
one two
0 1.0 1
1 2.0 2
2 3.0 3
3 NaN 4
也可以如下处理:
import pandas from pandas import Series import numpy as np from pandas import DataFrame d = dict( A = np.array([1,2]), B = np.array([1,2,3,4])) DataFrame(dict([(k,Series(v)) for k,v in d.items()]))Out[4]:
A B
0 1.0 1
1 2.0 2
2 NaN 3
3 NaN 4
还可以处理如下:
import numpy as np import pandas as pd my_dict = dict( A = np.array([1,2]), B = np.array([1,2,3,4]) ) df = pd.DataFrame.from_dict(my_dict,orient='index').T dfOut[5]:
A B
0 1.0 1.0
1 2.0 2.0
2 NaN 3.0
3 NaN 4.0
4.3.3 排名索引
说明:axis、ascending、inplace、by
DataFrame中的排序分为两种,一种是对索引排序,一种是对值进行排序。
索引排序: sort_index();值排序:sort_values();值排名:rank()
对于索引排序,涉及到对行索引、列索引的排序,并且还涉及到是升序还是降序。函数df.sort_index(axis= , ascending= , inplace=),需要特别注意这三个参数。axis表示对行操作,还是对列操作;ascending表示升序,还是降序操作。
对于值排序,同样也是涉及到行、列排序问题,升序、降序排列问题。函数df.sort_values(by= , axis= , ascending= , inplace=),也需要特别注意这几个参数,只是多了一个by操作,需要我们指明是按照哪一行或哪一列,进行排序的。
PS:(True\False)大写
- axis=0表示对行操作,axis=1表示对列进行操作;
- ascending=True表示升序,ascending=False表示降序;
- inplace=True表示对原始DataFrame本身操作,因此不需要赋值操作,inplace=False相当于是对原始DataFrame的拷贝,之后的一些操作都是针对这个拷贝文件进行操作的,因此需要我们赋值给一个变量,保存操作后的结果。
1. 排名排序(索引排序):df.sort_index()
Series的sort_index(ascending=True)方法可以对 index 进行排序操作,ascending 参数用于控制升序或降序,默认为升序。
在 DataFrame 上,.sort_index(axis=0, by=None, ascending=True) 方法多了一个轴向的选择参数与一个 by 参数,by 参数的作用是针对某一(些)列进行排序(不能对行使用 by 参数)。
- axis:0按照行名排序;1按照列名排序
from pandas import DataFrame df0={'Ohio':[0,6,3],'Texas':[7,4,1],'California':[2,8,5]} df=DataFrame(df0,index=['a','c','d']) dfOut[1]:
Ohio Texas California
a 0 7 2
c 6 4 8
d 3 1 5df.sort_index(by='Ohio')Out[2]:
Ohio Texas California
a 0 7 2
d 3 1 5
c 6 4 8df.sort_index(by=['California','Texas'])Out[3]:
Ohio Texas California
a 0 7 2
d 3 1 5
c 6 4 8df.sort_index(axis=1) #axis:0按照行名排序;1按照列名排序California Ohio Texas
a 2 0 7
c 8 6 4
d 5 3 1
排名(Series.rank(method=‘average’, ascending=True))的作用与排序的不同之处在于,它会把对象的 values 替换成名次(从 1 到 n),对于平级项可以通过方法里的 method 参数来处理,method 参数有四个可选项:average, min, max, first。举例如下:
from pandas import Series ser=Series([3,2,0,3],index=list('abcd')) serOut[8]:
a 3
b 2
c 0
d 3ser.rank() ser.rank(method='min') ser.rank(method='max') ser.rank(method='first')ser.rank()
Out[9]:
a 3.5
b 2.0
c 1.0
d 3.5
dtype: float64ser.rank(method=‘min’)
Out[10]:
a 3.0
b 2.0
c 1.0
d 3.0
dtype: float64ser.rank(method=‘max’)
Out[11]:
a 4.0
b 2.0
c 1.0
d 4.0
dtype: float64ser.rank(method=‘first’)
Out[12]:
a 3.0
b 2.0
c 1.0
d 4.0
dtype: float64
2.重新索引:.reindex(index=None,**kwargs)
Series 对象的重新索引通过其 .reindex(index=None,**kwargs) 方法实现。**kwargs 中常用的参数有两个:method=None和fill_value=np.NaN。
ser = Series([4.5,7.2,-5.3,3.6],index=['d','b','a','c']) A = ['a','b','c','d','e'] ser.reindex(A)Out[13]:
a -5.3
b 7.2
c 3.6
d 4.5
e NaN
dtype: float64ser = ser.reindex(A,fill_value=0) ser.reindex(A,method='ffill') ser.reindex(A,fill_value=0,method='ffill')Out[15]:
a -5.3
b 7.2
c 3.6
d 4.5
e 0.0
dtype: float64a -5.3
b 7.2
c 3.6
d 4.5
e 4.5
dtype: float64a -5.3
b 7.2
c 3.6
d 4.5
e 4.5
dtype: float64
- .reindex() 方法会返回一个新对象,其 index 严格遵循给出的参数,
- method:{‘backfill’, ‘bfill’, ‘pad’, ‘ffill’, None} 参数用于指定插值(填充)方式,当没有给出时,默认用 fill_value 填充,值为 NaN(ffill = pad,bfill = back fill,分别指插值时向前还是向后取值)。
- DataFrame 对象的重新索引方法:.reindex(index=None,columns=None,**kwargs)仅比 Series 多了一个可选的 columns 参数,用于给列索引。用法与上例Series类似,只不过插值方法 method 参数只能应用于行,即轴axis = 0。
>>> state = ['Texas','Utha','California']
>>> df.reindex(columns=state,method='ffill')
Texas Utha California
a 1 NaN 2
c 4 NaN 5
d 7 NaN 8
[3 rows x 3 columns]
>>> df.reindex(index=['a','b','c','d'],columns=state,method='ffill')
Texas Utha California
a 1 NaN 2
b 1 NaN 2
c 4 NaN 5
d 7 NaN 8
[4 rows x 3 columns]
可不可以通过 df.T.reindex(index,method=‘**’).T 这样的方式来实现在列上的插值呢?
答案是肯定的。
另外要注意,使用 reindex(index,method=‘**’) 的时候,index 必须是单调的,否则就会引发一个 ValueError: Must be monotonic for forward fill,比如上例中的最后一次调用,如果使用 index=[‘a’,‘b’,‘d’,‘c’] 就会报错。
3. 值排序:df.sort_values()
1、对某一列进行升序排列(有实际意义)
df = pd.DataFrame({"A":[3,1,5,9,7], "B":[4,1,2,5,3], "C":[3,15,9,6,12], "D":[2,4,6,10,8]}, index=list("acbed")) display(df)A B C D
a 3 4 3 2
c 1 1 15 4
b 5 2 9 6
e 9 5 6 10
d 7 3 12 8df.sort_values(by="A",axis=0,ascending=True,inplace=True) dfOut[133]:
A B C D
c 1 1 15 4
a 3 4 3 2
b 5 2 9 6
d 7 3 12 8
e 9 5 6 10
2、 对某一行进行降序排列(实际意义不大)
df = pd.DataFrame({"A":[3,1,5,9,7], "B":[4,1,2,5,3], "C":[3,15,9,6,12], "D":[2,4,6,10,8]}, index=list("acbed")) display(df)A B C D
a 3 4 3 2
c 1 1 15 4
b 5 2 9 6
e 9 5 6 10
d 7 3 12 8df.sort_values(by="a",axis=1,ascending=False,inplace=True) dfOut[140]:
B A C D
a 4 3 3 2
c 1 1 15 4
b 2 5 9 6
e 5 9 6 10
d 3 7 12 8
4、sort_values()中的na_position参数
na_position参数用于设定缺失值的显示位置,first表示缺失值显示在最前面;last表示缺失值显示在最后面。
df = pd.DataFrame({"A":[10,8,np.nan,2,4], "B":[1,7,5,3,8], "C":[5,2,8,4,1]}, index=list("abcde")) dfOut[141]:
A B C
a 10.0 1 5
b 8.0 7 2
c NaN 5 8
d 2.0 3 4
e 4.0 8 1df.sort_values(by="A",axis=0,inplace=True,na_position="first") dfOut[142]:
A B C
c NaN 5 8
d 2.0 3 4
e 4.0 8 1
b 8.0 7 2
a 10.0 1 5df.sort_values(by="A",axis=0,inplace=True,na_position="last") dfOut[143]:
A B C
d 2.0 3 4
e 4.0 8 1
b 8.0 7 2
a 10.0 1 5
c NaN 5 8
5、“值排名”:rank()函数
1、rank()函数的常用参数说明
(31条消息) DataFrame(13):DataFrame的排序与排名问题_数据分析与统计学之美-CSDN博客_dataframe排序
4.3.4 数据合并
1. 记录合并:是指两个结构相同的数据框合并成一个数据框。也就是在一个数据框中追加另一个数据框的数据记录。pd.concat([df1,df2])
concat([dataFrame1, dataFrame2,…])
DataFrame1:数据框
返回值:DataFrame
import pandas from pandas import DataFrame from pandas import read_excel df1 = read_excel('E:\\Python\\第4章数据\\rz2.xlsx') df1 df2 = read_excel('E:\\Python\\第4章数据\\rz3.xlsx') df2Out[1]:
YHM TCSJ YWXT IP
0 S1402048 18922254812 1.225790e+17 221.205.98.55
1 S1411023 13522255003 1.225790e+17 183.184.226.205
2 S1402048 13422259938 NaN 221.205.98.55
3 20031509 18822256753 NaN 222.31.51.200
4 S1405010 18922253721 1.225790e+17 120.207.64.3
5 20140007 13422259313 1.225790e+17 222.31.51.200
6 S1404095 13822254373 1.225790e+17 222.31.59.220
7 S1402048 13322252452 1.225790e+17 221.205.98.55
8 S1405011 18922257681 1.225790e+17 183.184.230.38
9 S1402048 13322252452 1.225790e+17 221.205.98.55
10 S1405011 18922257681 1.225790e+17 183.184.230.38[11 rows x 5 columns]
Out[2]:
YHM TCSJ YWXT IP
0 S1402011 18603514812 1.225790e+17 221.205.98.55
1 S1411022 13103515003 1.225790e+17 183.184.226.205
2 S1402033 13203559930 NaN 221.205.98.55[3 rows x 5 columns]
合并:两个文件的数据记录都合并到一起了,实现了数据记录的“叠加”或者记录顺延。
df=pandas.concat([df1,df2]) dfOut[3]:
YHM TCSJ YWXT IP
0 S1402048 18922254812 1.225790e+17 221.205.98.55
1 S1411023 13522255003 1.225790e+17 183.184.226.205
2 S1402048 13422259938 NaN 221.205.98.55
3 20031509 18822256753 NaN 222.31.51.200
4 S1405010 18922253721 1.225790e+17 120.207.64.3
5 20140007 13422259313 1.225790e+17 222.31.51.200
6 S1404095 13822254373 1.225790e+17 222.31.59.220
7 S1402048 13322252452 1.225790e+17 221.205.98.55
8 S1405011 18922257681 1.225790e+17 183.184.230.38
9 S1402048 13322252452 1.225790e+17 221.205.98.55
10 S1405011 18922257681 1.225790e+17 183.184.230.38
0 S1402011 18603514812 1.225790e+17 221.205.98.55
1 S1411022 13103515003 1.225790e+17 183.184.226.205
2 S1402033 13203559930 NaN 221.205.98.55[14 rows x 5 columns]
2. 字段合并:是指将同一个数据框中的不同的列进行合并,形成新的列。X = x1+x2+…
X = x1+x2+… x1:数据列1 x2:数据列2 返回值:Series,合并后的系列,要求合并的系列长度一致。import pandas from pandas import DataFrame from pandas import read_csv df = read_csv('e://rz4.csv',sep=" ",names=['band','area','num']) df df = df.astype(str) tel=df['band']+df['area']+df['num'] telOut[1]:
band area num
0 189 2225 4812
1 135 2225 5003
2 134 2225 9938
3 188 2225 6753
4 189 2225 3721
5 134 2225 9313
6 138 2225 4373
7 133 2225 2452
8 189 2225 7681Out[2]:
0 18922254812
1 13522255003
2 13422259938
3 18822256753
4 18922253721
5 13422259313
6 13822254373
7 13322252452
8 18922257681
dtype: object
3. 字段匹配:是指不同结构的数据框(两个或以上的数据框),按照一定的条件进行合并,即追加列。merge(x,y,left_on,right_on) 外键连接
merge(x,y,left_on,right_on)
x:第一个数据框
y:第二个数据框
left_on:第一个数据框的用于匹配的列
right_on:第二个数据框的用于匹配的列
返回值:DataFrame
import pandas from pandas import DataFrame from pandas import read_excel df1 = read_excel('e://rz2.xlsx',sheetname='Sheet3') df1Out[1]:
id band num
0 1 130 123
1 2 131 124
2 4 133 125
3 5 134 126df2 = read_excel('e://rz2.xlsx',sheetname='Sheet4') df2Out[2]:
id band area
0 1 130 351
1 2 131 352
2 3 132 353
3 4 133 354
4 5 134 355
5 5 135 356pandas.merge(df1,df2,left_on='id',right_on='id')Out[3]:
id band_x num band_y area
0 1 130 123 130 351
1 2 131 124 131 352
2 4 133 125 133 354
3 5 134 126 134 355
4 5 134 126 135 356
4.3.5 数据计算
1. 简单计算:通过对各字段进行加、减、乘、除等四则算术运算,计算出的结果作为新的字段。
| id | num | price |
|---|---|---|
| 1 | 123 | 159 |
| 2 | 124 | 753 |
| 3 | 125 | 456 |
| 4 | 126 | 852 |
| id | num | price | result |
|---|---|---|---|
| 1 | 123 | 159 | 19557 |
| 2 | 124 | 753 | 93372 |
| 3 | 125 | 456 | 57000 |
| 4 | 126 | 852 | 107352 |
from pandas import read_csv df = read_csv('e://rz2.csv',sep=',') dfOut[1]:
id band num price
0 1 130 123 159
1 2 131 124 753
2 3 132 125 456
3 4 133 126 852result=df.price*df.num resultOut[2]:
0 19557
1 93372
2 57000
3 107352
dtype: int64df['result']=result dfOut[3]:
id band num price result
0 1 130 123 159 19557
1 2 131 124 753 93372
2 3 132 125 456 57000
3 4 133 126 852 107352
2. 数据标准化:是指将数据按照比例缩放,使之落入特定的区间,一般使用0-1标准化。X*=(x-min)/(max-min)
from pandas import read_csv df = read_csv('e://rz2.csv',sep=',') dfOut[1]:
id band num price
0 1 130 123 159
1 2 131 124 753
2 3 132 125 456
3 4 133 126 852scale=(df.price-df.price.min())/(df.price.max()-df.price.min()) scaleOut[2]:
0 0.000000
1 0.857143
2 0.428571
3 1.000000
Name: price, dtype: float64
4.3.6 数据分组
bins = [0,180,210,240,270,np.inf] #np.inf 是无穷大
labels=["差","及格", "中","良","优"]
df3["等级"]=pd.cut(df3.总分,bins,right=False,labels=labels)
说明:pd.cut(series,bins,right=True,labels=NULL)
数据分组:根据数据分析对象的特征,按照一定的数据指标,把数据划分为不同的区间来进行研究,以揭示其内在的联系和规律性。简单来说:就是新增一列,将原来的数据按照其性质归入新的类别中。
cut(series,bins,right=True,labels=NULL)
series 需要分组的数据
bins 分组的依据数据
right 分组的时候右边是否闭合
labels 分组的自定义标签,可以不自定义
bins
import pandas #from pandas import DataFrame from pandas import read_csv df = read_csv('e://rz2.csv',sep=',') dfOut[1]:
id band num price
0 1 130 123 159
1 2 131 124 753
2 3 132 125 456
3 4 133 126 852bins=[min(df.price)-1,500,max(df.price)+1] labels=["500以下","500以上"] pandas.cut(df.price,bins)Out[2]:
0 (158, 500]
1 (500, 853]
2 (158, 500]
3 (500, 853]
Name: price, dtype: category
Categories (2, object): [(158, 500] < (500, 853]]pandas.cut(df.price,bins,right=False)Out[3]:
0 [158, 500)
1 [500, 853)
2 [158, 500)
3 [500, 853)
Name: price, dtype: category
Categories (2, object): [[158, 500) < [500, 853)]
right 值:分组的时候右边是否闭合
labels
pa=pandas.cut(df.price,bins,right=False,labels=labels)
pa
Out[5]:
0 500以下
1 500以上
2 500以下
3 500以上
Name: price, dtype: category
Categories (2, object): [500以下 < 500以上]
df['label']=pandas.cut(df.price,bins,right=False,labels=labels)
df
Out[6]:
id band num price label
0 1 130 123 159 500以下
1 2 131 124 753 500以上
2 3 132 125 456 500以下
3 4 133 126 852 500以上
4.3.7 日期处理
1. 日期转换:是指将字符型的日期格式转换为日期格式数据的过程。
to_datetime(dateString,format)
format格式:
%Y:年份
%m:月份
%d:日期
%H:小时
%M:分钟
%S:秒
【例4-21】to_datetime(df.注册时间,format=’%Y/%m/%d’)。
from pandas import read_csv from pandas import to_datetime df = read_csv('e://rz3.csv',sep=',',encoding='utf8') dfOut[1]:
num price year month date
0 123 159 2016 1 2016/6/1
1 124 753 2016 2 2016/6/2
2 125 456 2016 3 2016/6/3
3 126 852 2016 4 2016/6/4
4 127 210 2016 5 2016/6/5
5 115 299 2016 6 2016/6/6
6 102 699 2016 7 2016/6/7
7 201 599 2016 8 2016/6/8
8 154 199 2016 9 2016/6/9
9 142 899 2016 10 2016/6/10df_dt = to_datetime(df.date,format="%Y/%m/%d") df_dtOut[2]:
0 2016-06-01
1 2016-06-02
2 2016-06-03
3 2016-06-04
4 2016-06-05
5 2016-06-06
6 2016-06-07
7 2016-06-08
8 2016-06-09
9 2016-06-10
Name: date, dtype: datetime64[ns]
注意csv的格式是否是utf8格式,否则会报错。另外,csv里date的格式是文本(字符串)格式。
2. 日期格式化:是指将日期型的数据按照给定的格式转化为字符型的数据。
apply(lambda x:处理逻辑)
datetime.strftime(x,format)
【例4-22】日期型数据转化为字符型数据。
df_dt = to_datetime(df.date,format="%Y/%m/%d") df_dt_str=df_dt.apply(lambda x: datetime.strftime(x,"%Y/%m/%d")) from pandas import read_csv from pandas import to_datetime from datetime import datetime df = read_csv('e://rz3.csv',sep=',',encoding='utf8') df_dt = to_datetime(df.date,format="%Y/%m/%d") df_dt_str=df_dt.apply(lambda x: datetime.strftime(x,"%Y/%m/%d")) #apply见后注 df_dt_strOut[1]:
0 2016/06/01
1 2016/06/02
2 2016/06/03
3 2016/06/04
4 2016/06/05
5 2016/06/06
6 2016/06/07
7 2016/06/08
8 2016/06/09
9 2016/06/10
Name: date, dtype: object注意:当希望将函数f应用到DataFrame 对象的行或列时,可以使用.apply(f, axis=0, args=(), **kwds) 方法,axis=0表示按列运算,axis=1时表示按行运算。如:
from pandas import DataFrame df=DataFrame({'ohio':[1,3,6],'texas':[1,4,5],'california':[2,5,8]},index=['a','c','d']) dfOut[1]:
california ohio texas
a 2 1 1
c 5 3 4
d 8 6 5f = lambda x:x.max()-x.min() df.apply(f) #默认按列运算,同df.apply(f,axis=0)Out[2]:
california 6
ohio 5
texas 4
dtype: int64df.apply(f,axis=1) #按行运算Out[3]:
a 1
c 2
d 3
dtype: int64
3. 日期抽取:是指从日期格式里面抽取出需要的部分属性
Data_dt.dt.property
| second | 1-60秒,从1开始到60 |
|---|---|
| minute | 1-60分,从1开始到60 |
| hour | 1-24小时,从1开始到24 |
| day | 1-31日,一个月中第几天,从1开始到31 |
| month | 1-12月,从1开始到12 |
| year | 年份 |
| weekday | 1-7,一周中的第几天,从1开始,最大为7(已改为0-6) |
【例4-23】对日期进行抽取。
from pandas import read_csv; from pandas import to_datetime; df = read_csv('e://rz3.csv', sep=',', encoding='utf8') dfOut[1]:
num price year month date
0 123 159 2016 1 2016/6/1
1 124 753 2016 2 2016/6/2
2 125 456 2016 3 2016/6/3
3 126 852 2016 4 2016/6/4
4 127 210 2016 5 2016/6/5
5 115 299 2016 6 2016/6/6
6 102 699 2016 7 2016/6/7
7 201 599 2016 8 2016/6/8
8 154 199 2016 9 2016/6/9
9 142 899 2016 10 2016/6/10df_dt =to_datetime(df.date,format='%Y/%m/%d') df_dtOut[2]:
0 2016-06-01
1 2016-06-02
2 2016-06-03
3 2016-06-04
4 2016-06-05
5 2016-06-06
6 2016-06-07
7 2016-06-08
8 2016-06-09
9 2016-06-10
Name: date, dtype: datetime64[ns]df_dt.dt.yearOut[3]:
0 2016
1 2016
2 2016
3 2016
4 2016
5 2016
6 2016
7 2016
8 2016
9 2016
Name: date, dtype: int64df_dt.dt.dayOut[4]:
0 1
1 2
2 3
3 4
4 5
5 6
6 7
7 8
8 9
9 10
Name: date, dtype: int64
4. 日期判断:
Python 时间比较大小 并从dataframe中提取满足时间条件的量_siml142857的博客-CSDN博客_dataframe 比较大小
5.日期增长:
python 当前时间减一天-菜鸟笔记
4、数据分析
4.4.1 基本统计:describe
如果分组字段是离散值,则直接使用groupby分组统计
基本统计分析:又叫描述性统计分析,一般统计某个变量的最小值、第一个四分位值、中值、第三个四分位值、以及最大值。
describe() 描述性统计分析函数
常用的统计函数:
size 计数(此函数不需要括号)
sum() 求和
mean() 平均值
var() 方差
std() 标准差
(22条消息) Python对表的行列求和_OlivierJ的博客-CSDN博客_python 列求和
4.4.2 分组分析:groupby(离散值分组)
如果分组字段是连续值,则先进行离散化(cut),然后再使用groupby分组
分组分析:是指根据分组字段将分析对象划分成不同的部分,以进行对比分析各组之间的差异性的一种分析方法。
常用的统计指标:计数、求和、平均值
常用形式:
df.groupby(by=['分类1','分类2',...])['被统计的列'].agg({列别名1:统计函数1,列别名2:统计函数2,…})
by 用于分组的列
[ ] 用于统计的列
.agg 统计别名显示统计值的名称,统计函数用于统计数据
size 计数
sum 求和
mean 均值
from pandas import read_excel df = read_excel('e:\\rz4.xlsx') dfOut[1]:
学号 班级 姓名 性别 英语 体育 军训 数分 高代 解几 计算机
0 2308024241 23080242 成龙 男 76 78 77 40 23 60 89
1 2308024244 23080242 周怡 女 66 91 75 47 47 44 82
2 2308024251 23080242 张波 男 85 81 75 45 45 60 80
3 2308024249 23080242 朱浩 男 65 50 80 72 62 71 82
4 2308024219 23080242 封印 女 73 88 92 61 47 46 83
5 2308024201 23080242 迟培 男 60 50 89 71 76 71 82
6 2308024347 23080243 李华 女 67 61 84 61 65 78 83
7 2308024307 23080243 陈田 男 76 79 86 69 40 69 82
8 2308024326 23080243 余皓 男 66 67 85 65 61 71 95
9 2308024320 23080243 李嘉 女 62 60 90 60 67 77 95
10 2308024342 23080243 李上初 男 76 90 84 60 66 60 82
11 2308024310 23080243 郭窦 女 79 67 84 64 64 79 85
12 2308024435 23080244 姜毅涛 男 77 71 87 61 73 76 82
13 2308024432 23080244 赵宇 男 74 74 88 68 70 71 85
14 2308024446 23080244 周路 女 76 80 77 61 74 80 85
15 2308024421 23080244 林建祥 男 72 72 81 63 90 75 85
16 2308024433 23080244 李大强 男 79 76 77 78 70 70 89
17 2308024428 23080244 李侧通 男 64 96 91 69 60 77 83
18 2308024402 23080244 王慧 女 73 74 93 70 71 75 88
19 2308024422 23080244 李晓亮 男 85 60 85 72 72 83 89df3.groupby(by=['班级','性别'])['军训'].agg({'总分':numpy.sum,'人数': numpy.size,'平均>值':numpy.mean,'方差':numpy.var,'标准差':numpy.std,'最高分':numpy.max,'最低分':numpy.min})总分 人数 平均值 方差 标准差 最高分 最低分
班级 性别
23080242 女 167 2 83.500000 144.500000 12.020815 92 75
男 321 4 80.250000 38.250000 6.184658 89 75
23080243 女 258 3 86.000000 12.000000 3.464102 90 84
男 255 3 85.000000 1.000000 1.000000 86 84
23080244 女 170 2 85.000000 128.000000 11.313708 93 77
男 509 6 84.833333 25.766667 5.076088 91 77
4.4.3 分布分析:cut+groupby(连续值分组)
分组分析:是指根据分组字段将分析对象划分成不同的部分,以进行对比分析各组之间的差异性的一种分析方法。
常用的统计指标:计数、求和、平均值
常用形式:
df.groupby(by=['分类1','分类2',...])['被统计的列'].agg({列别名1:统计函数1,列别名2:统计函数2,…})
by 用于分组的列
[ ] 用于统计的列
.agg 统计别名显示统计值的名称,统计函数用于统计数据
size 计数
sum 求和
mean 均值
import numpy import pandas from pandas import read_excel df = read_excel('e:\\rz4.xlsx') dfOut[1]:
学号 班级 姓名 性别 英语 体育 军训 数分 高代 解几 计算机 总分
0 2308024241 23080242 成龙 男 76 78 77 40 23 60 89 443
1 2308024244 23080242 周怡 女 66 91 75 47 47 44 82 452
2 2308024251 23080242 张波 男 85 81 75 45 45 60 80 471
3 2308024249 23080242 朱浩 男 65 50 80 72 62 71 82 482
4 2308024219 23080242 封印 女 73 88 92 61 47 46 83 490
5 2308024201 23080242 迟培 男 60 50 89 71 76 71 82 499
6 2308024347 23080243 李华 女 67 61 84 61 65 78 83 499
7 2308024307 23080243 陈田 男 76 79 86 69 40 69 82 501
8 2308024326 23080243 余皓 男 66 67 85 65 61 71 95 510
9 2308024320 23080243 李嘉 女 62 60 90 60 67 77 95 511
10 2308024342 23080243 李上初 男 76 90 84 60 66 60 82 518
11 2308024310 23080243 郭窦 女 79 67 84 64 64 79 85 522
12 2308024435 23080244 姜毅涛 男 77 71 87 61 73 76 82 527
13 2308024432 23080244 赵宇 男 74 74 88 68 70 71 85 530
14 2308024446 23080244 周路 女 76 80 77 61 74 80 85 533
15 2308024421 23080244 林建祥 男 72 72 81 63 90 75 85 538
16 2308024433 23080244 李大强 男 79 76 77 78 70 70 89 539
17 2308024428 23080244 李侧通 男 64 96 91 69 60 77 83 540
18 2308024402 23080244 王慧 女 73 74 93 70 71 75 88 544
19 2308024422 23080244 李晓亮 男 85 60 85 72 72 83 89 546labels=['450及其以下','450到500','500及其以上'] #给三段数据贴标签 labelsOut[5]: [‘450及其以下’, ‘450到500’, ‘500及其以上’]
bins = [min(df.总分)-1,450,500,max(df.总分)+1] #将数据分成三段 binsOut[3]: [442, 450, 500, 547]
总分分层 = pandas.cut(df.总分,bins,labels=labels) 总分分层Out[7]:
0 450及其以下
1 450到500
2 450到500
3 450到500
4 450到500
5 450到500
6 450到500
7 500及其以上
8 500及其以上
9 500及其以上
10 500及其以上
11 500及其以上
12 500及其以上
13 500及其以上
14 500及其以上
15 500及其以上
16 500及其以上
17 500及其以上
18 500及其以上
19 500及其以上
Name: 总分, dtype: category
Categories (3, object): [450及其以下 < 450到500 < 500及其以上]df['总分分层']= 总分分层 dfOut8]:
学号 班级 姓名 性别 英语 体育 军训 数分 高代 解几 计算机基础 总分 总分分层
0 2308024241 23080242 成龙 男 76 78 77 40 23 60 89 443 450及其以下
1 2308024244 23080242 周怡 女 66 91 75 47 47 44 82 452 450到500
2 2308024251 23080242 张波 男 85 81 75 45 45 60 80 471 450到500
3 2308024249 23080242 朱浩 男 65 50 80 72 62 71 82 482 450到500
4 2308024219 23080242 封印 女 73 88 92 61 47 46 83 490 450到500
5 2308024201 23080242 迟培 男 60 50 89 71 76 71 82 499 450到500
6 2308024347 23080243 李华 女 67 61 84 61 65 78 83 499 450到500
7 2308024307 23080243 陈田 男 76 79 86 69 40 69 82 501 500及其以上
8 2308024326 23080243 余皓 男 66 67 85 65 61 71 95 510 500及其以上
9 2308024320 23080243 李嘉 女 62 60 90 60 67 77 95 511 500及其以上
10 2308024342 23080243 李上初 男 76 90 84 60 66 60 82 518 500及其以上
11 2308024310 23080243 郭窦 女 79 67 84 64 64 79 85 522 500及其以上
12 2308024435 23080244 姜毅涛 男 77 71 87 61 73 76 82 527 500及其以上
13 2308024432 23080244 赵宇 男 74 74 88 68 70 71 85 530 500及其以上
14 2308024446 23080244 周路 女 76 80 77 61 74 80 85 533 500及其以上
15 2308024421 23080244 林建祥 男 72 72 81 63 90 75 85 538 500及其以上
16 2308024433 23080244 李大强 男 79 76 77 78 70 70 89 539 500及其以上
17 2308024428 23080244 李侧通 男 64 96 91 69 60 77 83 540 500及其以上
18 2308024402 23080244 王慧 女 73 74 93 70 71 75 88 544 500及其以上
19 2308024422 23080244 李晓亮 男 85 60 85 72 72 83 89 546 500及其以上df.groupby(by=['总分分层'])['总分'].agg({'人数':numpy.size})Out[9]:
人数
总分分层
450及其以下 1
450到500 6
500及其以上 13
4.4.4 交叉分析:pivot_table(数据透视表)
交叉分析:通常用于分析两个或两个以上分组变量之间的关系,以交叉表形式进行变量间关系的对比分析。一般分为:定量、定量分组交叉;定量、定性分组交叉;定性、定性分组交叉。
pivot_table(values,index,columns,aggfunc,fill_value)
values 数据透视表中的值
index 数据透视表中的行
columns 数据透视表中的列
aggfunc 统计函数
fill_value NA值的统一替换
import numpy import pandas from pandas import read_excel from pandas import pivot_table #在spyder下也可以不导入 df = read_excel('e:\\rz4.xlsx') bins = [min(df.总分)-1,450,500,max(df.总分)+1] labels=['450及其以下','450到500','500及其以上'] 总分分层 = pandas.cut(df.总分,bins,labels=labels) df['总分分层']= 总分分层 df.pivot_table(values=['总分'],index=['总分分层’], columns=['性别'],aggfunc=[numpy.size,numpy.mean])Out[1]:
size mean
总分 总分
性别 女 男 女 男
总分分层
450及其以下 NaN 1 NaN 443.000000
450到500 3 3 480.333333 484.000000
500及其以上 4 9 527.500000 527.666667df.pivot_table(values=['总分'],index=['总分分层’],columns=['性别'],aggfunc=[numpy.size,numpy.mean],fill_value=0) #也可以将统计为0的赋值为零,默认为nan。Out[2]:
size mean
总分 总分
性别 女 男 女 男
总分分层
450及其以下 0 1 0.000000 443.000000
450到500 3 3 480.333333 484.000000
500及其以上 4 9 527.500000 527.666667s
4.4.5 结构分析:pivot_table+sum+div(查比重)
结构分析:是在分组的基础上,计算各组成部分所占的比重,进而分析总体的内部特征的一种分析方法。
axis参数说明:0表示列;1表示行。
#假设要计算班级团体总分情况 import numpy import pandas from pandas import read_excel from pandas import pivot_table #在spyder下也可以不导入 df = read_excel('e:\\rz4.xlsx') df_pt = df.pivot_table(values=['总分’], index=['班级'],columns=['性别’], aggfunc=[numpy.sum]) df_ptOut[1]:
sum
总分
性别 女 男
班级
23080242 942 1895
23080243 1532 1529
23080244 1077 3220df_pt.sum()Out[3]:
性别
sum 总分 女 3551
男 6644
dtype: int64df_pt.div(df_pt.sum(axis=1),axis=0)#按列占比Out[5]:
sum
总分
性别 女 男
班级
23080242 0.332041 0.667959
23080243 0.500490 0.499510
23080244 0.250640 0.749360df_pt.sum(axis=1)Out[2]:
性别
sum 总分 女 3551
男 6644
dtype: int64df_pt.div(df_pt.sum(axis=0),axis=1)#按行占比Out[6]:
sum
总分
性别 女 男
班级
23080242 0.265277 0.285220
23080243 0.431428 0.230132
23080244 0.303295 0.484648df_pt.sum(axis=0)#效果同省略Out[4]:
班级
23080242 2837
23080243 3061
23080244 4297
dtype: int64
4.4.6 相关分析:corr(一维、二维)
相关分析: 是研究现象之间是否存在某种依存关系,并对具体有依存关系的现象探讨其相关方向以及相关程度,是研究随机变量之间的相关关系的一种统计方法。
相关系数: 可以用来描述定量变量之间的关系
| 相关系数|r|取值范围 | 相关程度 |
|---|---|
| 0<=|r|<0.3 | 低度相关 |
| 0.3<=|r|<0.8 | 中度相关 |
| 0.8<=|r|<=1 | 高度相关 |
相关分析函数:
DataFrame.corr()
Series.corr(other)
如果由数据框调用corr方法,那么将会计算每列两两之间的相似度。如果由序列调用corr方法,那么只是计算该序列与传入的序列之间的相关度。
返回值:
DataFrame调用 返回DataFrame
Series调用 返回一个数值型,大小为相关度
举例
#一维
df3.英语.corr(df3.高代)
Out[9]: -0.12524513810989527
df3.解几.corr(df3.高代)
Out[11]: 0.6132805268443008
#二维
df3.corr()
Out[13]:
学号 班级 英语 ... 解几 计算机基础 总分
学号 1.000000 0.982617 0.287492 ... 0.636150 0.211420 0.843040
班级 0.982617 1.000000 0.257248 ... 0.671301 0.251736 0.901960
英语 0.287492 0.257248 1.000000 ... 0.027452 -0.119039 0.167927
体育 0.130255 0.088482 0.244323 ... -0.526276 -0.266896 -0.067810
军训 0.124176 0.248652 -0.335015 ... 0.249299 0.148933 0.446614
数分 0.435493 0.517529 -0.129588 ... 0.544394 0.123399 0.732137
高代 0.602636 0.635006 -0.125245 ... 0.613281 0.096979 0.779466
解几 0.636150 0.671301 0.027452 ... 1.000000 0.305934 0.705506
计算机基础 0.211420 0.251736 -0.119039 ... 0.305934 1.000000 0.223004
总分 0.843040 0.901960 0.167927 ... 0.705506 0.223004 1.000000
5、数据可视化
相关注意
4.4Python数据处理篇之Matplotlib系列(四)—plt.bar()与plt.barh条形图
拉出长画布
fig = plt.figure(figsize=(12,4)) # 设置画布大小
调整标签字体大小
plt.tick_params(axis='x', labelsize=8) # 设置x轴标签大小
标签旋转
plt.bar(df['sport_type'], df['score'])
4.5.1 饼图:plt.pie(gb2.人数,labels=gb2.index,autopct=‘%.2f%%’,colors=[‘b’,‘pink’,(0.5,0.8,0.3)],explode=[0,0,0,0,0.1])
饼图(Pie Graph):又称圆形图,是一个划分为几个扇形的圆形统计图,它能够直观的反映个体与总体的比例关系
pie(x,labels,colors,explode,autopct)
x 进行绘图的序列
labels 饼图的各部分标签
colors 饼图的各部分颜色,使用GRB标颜色
explode 需要突出的块状序列
autopct 饼图占比的显示格式,%.2f:保留两位小数
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_excel(r'E:\Python\第4章数据\rz4.xlsx')
df
gb=df.groupby(by=['班级'])['学号'].agg([('人数',np.size)])
plt.pie(gb.人数,labels=gb.index,autopct='%.2f%%',colors=['b','pink',(0.5,0.8,0.3)],explode=[0,0.2,0])
练习
df2= pd.read_excel(r'E:\Python\第4章数据\09电动1.xls')
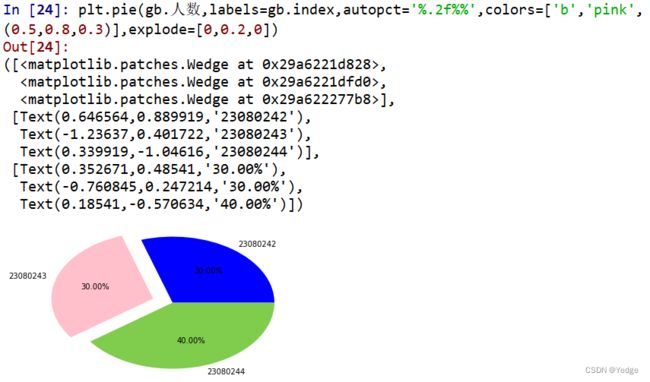
df2['C语言程序设计']=pd.cut(df2.C语言程序设计,bins=[0,60,70,80,90,101],right=False,labels=['不及格','及格','中等','良好','优秀']) #right=False 控制左闭右开
gb2=df2.groupby(by=['C语言程序设计'])['学号'].agg([('人数',np.size)]).fillna(0) #fillna(0)填充空值
plt.pie(gb2.人数,labels=gb2.index,autopct='%.2f%%',colors=['b','pink',(0.5,0.8,0.3)],explode=[0,0,0,0,0.1])
plt.rcParams['font.sans-serif']=['SimHei'] #字体
plt.rcParams['font.size']=30 #字体大小
plt.rcParams['figure.figsize']=[6,6] #正圆
-
plt.rcParams,显示设值字体的东西
plt.rcParams plt.rcParams['font.sans-serif'] Out[43]: ['DejaVu Sans', 'Bitstream Vera Sans', 'Computer Modern Sans Serif', 'Lucida Grande', 'Verdana', 'Geneva', 'Lucid', 'Arial', 'Helvetica', 'Avant Garde', 'sans-serif'] plt.rcParams['font.sans-serif']=['SimHei'] plt.rcParams['font.sans-serif']=['SimHei','...','...'] #没有的往后找
4.5.2 散点图:plt.plot(df.高代,df.数分,‘o’,color=‘pink’)
散点图(scatter diagram):是以一个变量为横坐标,另一个变量为纵坐标,利用散点(坐标点)的分布形态反映变量关系的一种图形。
plot(x,y, '. ',color=(r,g,b))
plt.xlabel('x轴坐标')
plt.ylabel('y轴坐标')
plt.grid(Ture)
x、y X轴和Y轴的序列
'. '、'o' 小点还是大点
Color 散点图的颜色,可以用rgb定义,也可以用英文字母定义
RGB颜色的设置:(red,green,blue) 红绿蓝颜色组成
df = pd.read_excel(r'E:\Python\第4章数据\rz4.xlsx')
df
gb=df.groupby(by=['班级'])['学号'].agg([('人数',np.size)])
plt.plot(df.英语,df.数分,'.',color='g')
plt.xlabel('英语')
plt.xlabel('数分')
plt.plot(df.高代,df.数分,'o',color='pink')
plt.plot(df.高代,df.数分,'o',color='pink')
plt.plot(df.高代,df.数分,'-',color='pink') #连线
4.5.3 折线图:plt.plot(df.学号,df.总分,‘-’,color=‘r’)
| 参数值 | 注释 |
|---|---|
| - | 连续的曲线 |
| — | 连续的虚线 |
| -. | 连续的用带点的曲线 |
| : | 由点连成的曲线 |
| . | 小点,散点图 |
| o | 大点,散点图 |
| , | 像素点(更小的点)的散点图 |
| * | 五角星的点散点图 |
| > | 右角标记散点图 |
| < | 左角标记散点图 |
| 1(2,3,4) | 伞形上(下左右)标记散点图 |
| s | 正方形标记散点图 |
| p | 五角星标记散点图 |
| v | 下三角标记散点图 |
| ^ | 上三角标记散点图 |
| h | 多边形标记散点图 |
| d | 钻石标记散点图 |
df = pd.read_excel(r'E:\Python\第4章数据\rz4.xlsx') df plt.plot(df.学号,df.总分,'-',color='r')学号 班级 姓名 性别 英语 体育 军训 数分 高代 解几 计算机基础 总分
0 2308024241 23080242 成龙 男 76 78 77 40 23 60 89 443
1 2308024244 23080242 周怡 女 66 91 75 47 47 44 82 452
2 2308024251 23080242 张波 男 85 81 75 45 45 60 80 471
3 2308024249 23080242 朱浩 男 65 50 80 72 62 71 82 482
4 2308024219 23080242 封印 女 73 88 92 61 47 46 83 490
5 2308024201 23080242 迟培 男 60 50 89 71 76 71 82 499
6 2308024347 23080243 李华 女 67 61 84 61 65 78 83 499
7 2308024307 23080243 陈田 男 76 79 86 69 40 69 82 501
8 2308024326 23080243 余皓 男 66 67 85 65 61 71 95 510
9 2308024320 23080243 李嘉 女 62 60 90 60 67 77 95 511
10 2308024342 23080243 李上初 男 76 90 84 60 66 60 82 518
11 2308024310 23080243 郭窦 女 79 67 84 64 64 79 85 522
12 2308024435 23080244 姜毅涛 男 77 71 87 61 73 76 82 527
13 2308024432 23080244 赵宇 男 74 74 88 68 70 71 85 530
14 2308024446 23080244 周路 女 76 80 77 61 74 80 85 533
15 2308024421 23080244 林建祥 男 72 72 81 63 90 75 85 538
16 2308024433 23080244 李大强 男 79 76 77 78 70 70 89 539
17 2308024428 23080244 李侧通 男 64 96 91 69 60 77 83 540
18 2308024402 23080244 王慧 女 73 74 93 70 71 75 88 544
19 2308024422 23080244 李晓亮 男 85 60 85 72 72 83 89 546
df=df.sort_values('学号')
df['学号后三位']=df.学号.astype(str).str.slice(-3,) #分离学号后三位,并加入新一列(不会影响df)
plt.plot(df.学号后三位,df.总分,'-',color='r') #画图
plt.xticks(rotation=60) #标签旋转度数
df2= pd.read_excel(r'E:\Python\第4章数据\09电动1.xls')
plt.plot(df2.姓名,df2.C语言程序设计,'--',color='g')
plt.xlabel('姓名')
plt.ylabel('C语言程序设计')
plt.xticks(rotation=90)
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['figure.figsize']=[10,6]
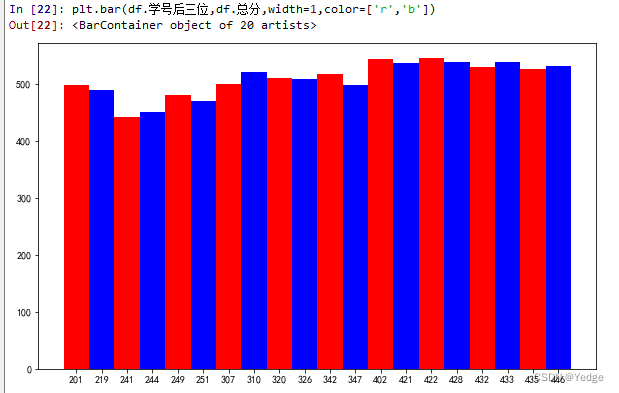
4.5.4 柱形图:plt.bar(df.学号后三位,df.总分,width=1,color=[‘r’,‘b’])
柱形图用于显示一段时间内的数据变化或显示各项之间的比较情况,是一种单位长度的长方形,根据数据大小绘制的统计图,用来比较两个或以上的数据(时间或类别)。
bar(left,height,width,color)
barh(bottom,width,height,color)
left x轴的位置序列,一般采用arange函数产生一个序列
height y轴的数值序列,也就是柱形图高度,一般就是我们需要展示的数据
width 柱形图的宽度,一般设置为1即可
color 柱形图填充颜色
df['学号后三位']=df.学号.astype(str).str.slice(-3,)
plt.bar(df.学号后三位,df.总分,width=1,color=['r','b']) #柱形图
plt.xticks(rotation=60)
plt.barh(df.学号后三位,df.总分,0.6,color=['r','b']) #条形图
bar
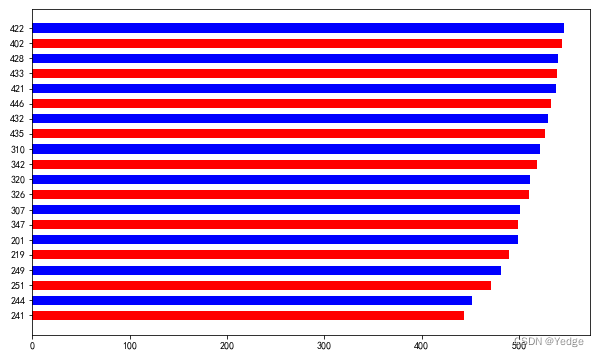
barh
4.5.5 直方图:plt.hist(df2.C语言程序设计,bins=10,color=‘g’,cumulative=True)
直方图(Histogram):是用一系列等宽不等高的长方形来绘制,宽度表示数据范围的间隔,高度表示在给定间隔内数据出现的频数,变化的高度形态表示数据的分布情况。
用来查看数据的频率
hist(x,color,bins,cumulative=False)
x 需要进行绘制的向量
color 直方图填充的颜色
bins 设置直方图的分组个数
cumulative 设置是否累积计数,默认是False
df2= pd.read_excel(r'E:\Python\第4章数据\09电动1.xls')
plt.hist(df2.C语言程序设计,bins=10,color='g',cumulative=False)
plt.hist(df2.C语言程序设计,bins=10,color='g',cumulative=True)
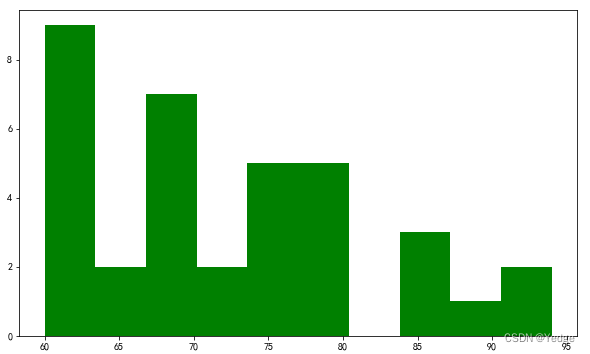
cumulative=False
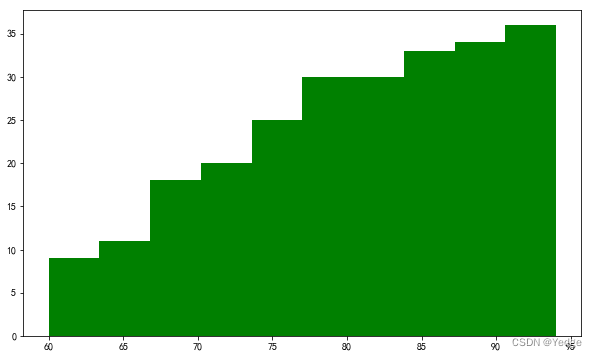
cumulative=True
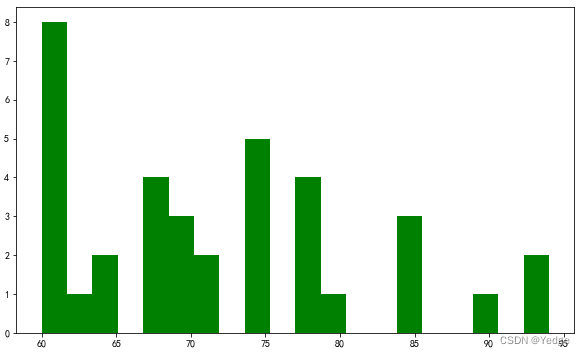
bins=20
这是我的线上笔记,希望对你有所帮助;你的点赞收藏,是我坚持的最大动力
![]()
【Python学习笔记—保姆版】Notion笔记