《PyTorch深度学习实践》学习笔记:Pytorch实现线性模型
文章目录
- 一、Pytorch实现线性模型
- 二、练习代码
- 三、课后练习
`
一、Pytorch实现线性模型
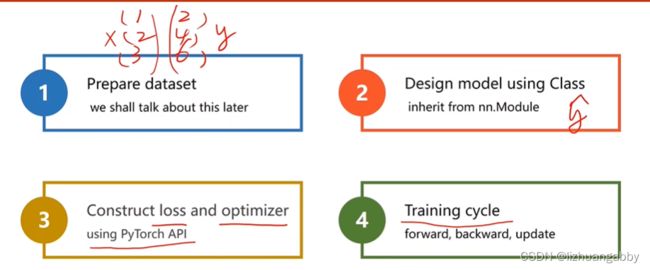
准备数据:
广播机制:

这两个矩阵是不能直接做加法的,所以需要做广播即对[1 2 3]进行扩充。

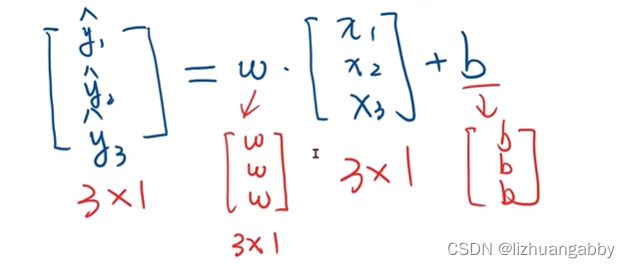
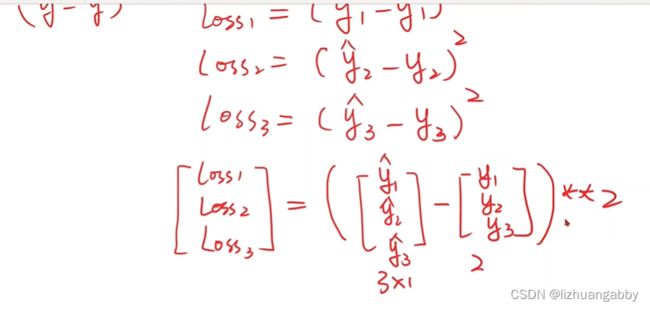
求出loss后,一般会求和或者均值得到loss的标量值。

pytorch输入的数据是tensor类型。

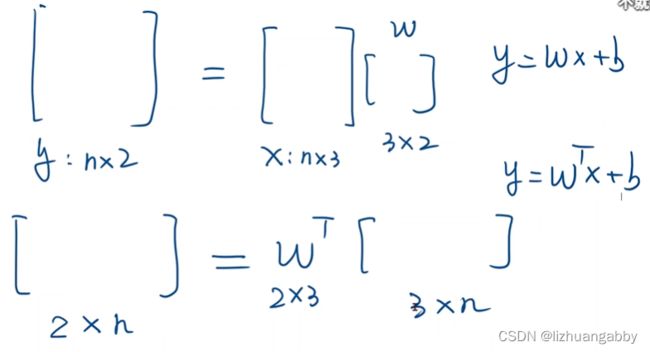
这里关于函数的参数的一些补充知识:
def fuc(*args,**kwargs):
print(args)
print(kwargs)
fuc(1,2,3,4,x=3,y=4)
(1, 2, 3, 4)
{‘x’: 3, ‘y’: 4}
可以看到args输出的是元组,而kwargs输出的是字典。

- 在pytorch的__call__语句里面有一个重要的就是forward()。
- Module实现了魔法函数__call__(),call()里面有一条语句是要调用forward()。因此新写的类中需要重写forward()覆盖掉父类中的forward()。
- 所以我们在自己的moudle里面必须是实现forward。


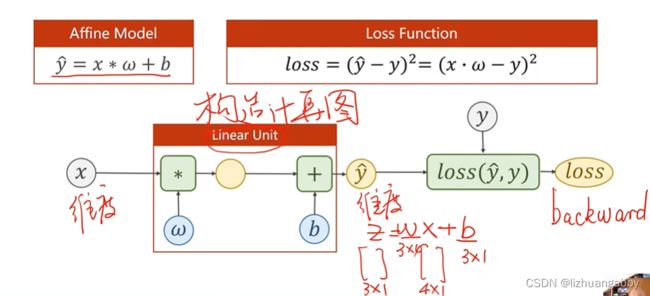
loss:

可以去看Pytorch官网查看MSEloss具体现在参数使用,跟上述有所不同。
优化器:

优化器不会构建计算图。
第一个参数:params代表的是权重。

优化器可以对模型里面的所有权重进行更新,上述的模型包括w和b。
最终完整的过程:
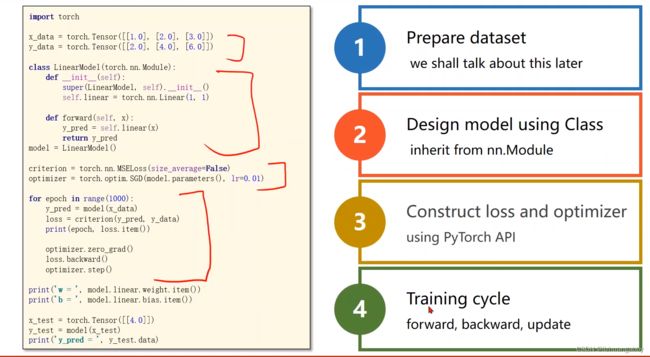
二、练习代码
import torch
from torch import nn
import matplotlib.pyplot as plt
x_data = torch.tensor([[1.0],[2.0],[3.0]])
y_data = torch.tensor([[2.0],[4.0],[6.0]])
class Linear(nn.Module):
def __init__(self):
super(Linear, self).__init__() # 调用父类的构造
self.linear = nn.Linear(1,1) # 构造线性层,继承Module
def forward(self,x):
y_pred = self.linear(x)
return y_pred
model = Linear()
# loss
crition = nn.MSELoss()
optim = torch.optim.SGD(model.parameters(),lr=0.01)
epoch_list = []
loss_list = []
for epoch in range(1000):
y_pred = model(x_data)
loss = crition(y_pred,y_data) # loss是标量,不会产生计算图
print(epoch,loss.item())
optim.zero_grad()
loss.backward()
optim.step()
loss_list.append(loss.item())
epoch_list.append(epoch+1)
print('w=',model.linear.weight.item())
print('b=',model.linear.bias.item())
x_test = torch.tensor([[4.0]])
y_test = model(x_test)
print('y_pred=',y_test.data)
#画loss曲线图
plt.plot(epoch_list,loss_list)
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()
输出结果:
0 19.817733764648438
1 15.665116310119629
2 12.382694244384766
3 9.788114547729492
4 7.737236976623535
5 6.116125583648682
6 4.834723472595215
7 3.8218417167663574
8 3.021212339401245
…
…
993 1.0619542990752961e-05
994 1.0569059668341652e-05
995 1.0517499504203442e-05
996 1.0467151696502697e-05
997 1.0416924851597287e-05
998 1.0366818969487213e-05
999 1.0316834050172474e-05
w= 1.9962784051895142
b= 0.00846012495458126
y_pred= tensor([[7.9936]])
经过1000次训练后输出接近8。
三、课后练习

对比不同优化器的loss下降。
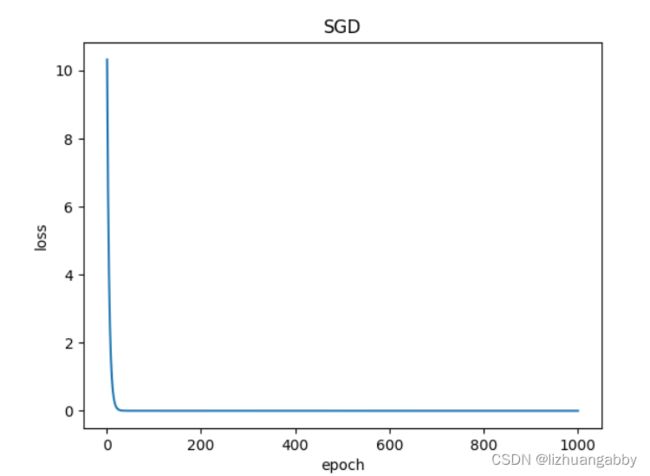
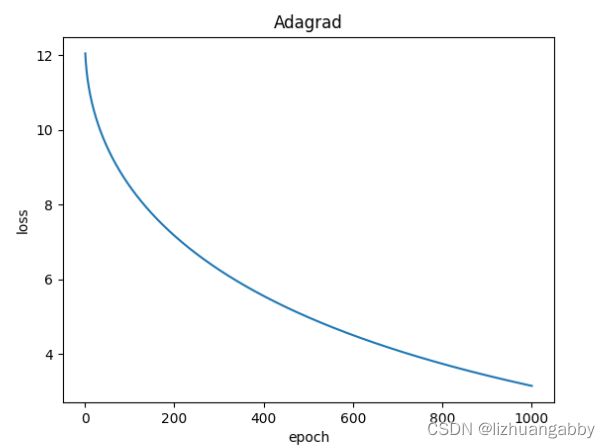
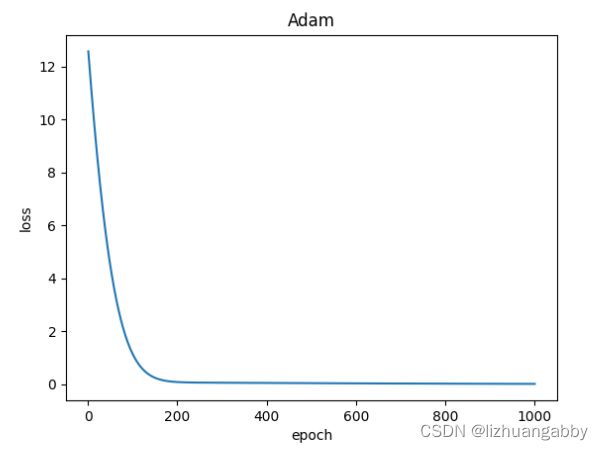
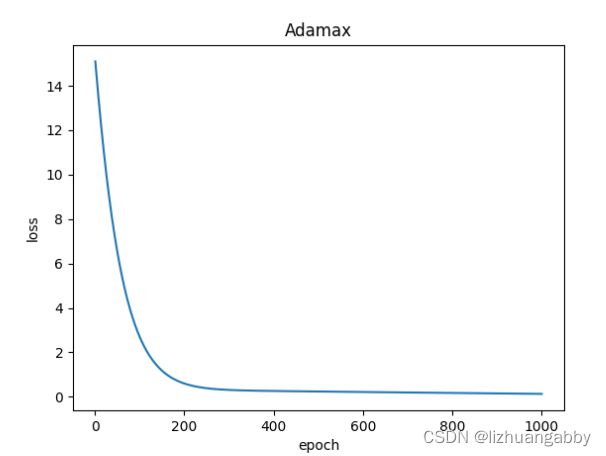
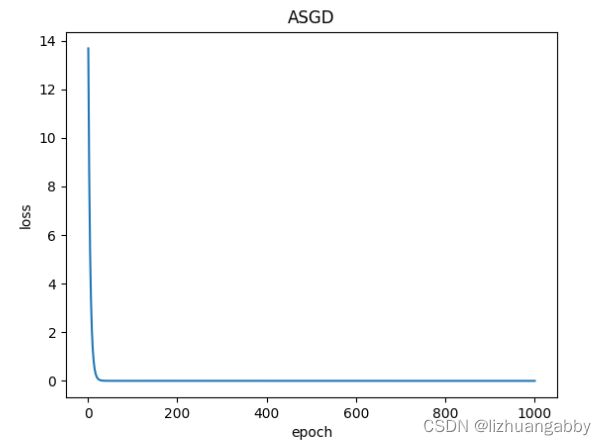
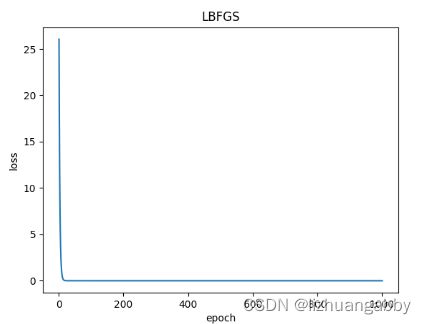 注意:LBFGS优化器与本篇其他所有优化器不同,需要重复多次计算函数,因此需要传入一个闭包,让他重新计算你的模型,这个闭包应当清空梯度、计算损失,然后返回损失。
注意:LBFGS优化器与本篇其他所有优化器不同,需要重复多次计算函数,因此需要传入一个闭包,让他重新计算你的模型,这个闭包应当清空梯度、计算损失,然后返回损失。

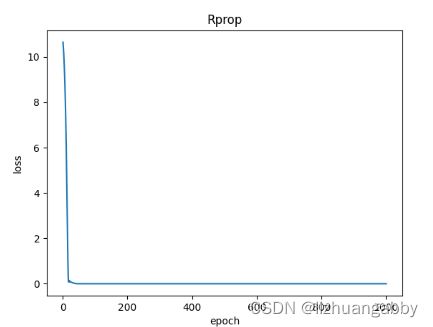
将上述优化器合并后的代码:
import torch
from torch import nn
import matplotlib.pyplot as plt
x_data = torch.tensor([[1.0],[2.0],[3.0]])
y_data = torch.tensor([[2.0],[4.0],[6.0]])
class Linear(nn.Module):
def __init__(self):
super(Linear, self).__init__() # 调用父类的构造
self.linear = nn.Linear(1,1) # 构造线性层,继承Module
def forward(self,x):
y_pred = self.linear(x)
return y_pred
model = Linear()
# loss
crition = nn.MSELoss()
# optim = torch.optim.SGD(model.parameters(),lr=0.01)
optim = torch.optim.Rprop(model.parameters(),lr=0.01)
epoch_list = []
loss_list = []
for epoch in range(1000):
def closure():
y_pred = model(x_data)
loss = crition(y_pred, y_data)
optim.zero_grad()
loss.backward()
return loss
loss = closure()
print(epoch+1,loss.item())
try:
optim.step(closure)
except:
optim.step()
loss_list.append(loss.item())
epoch_list.append(epoch+1)
print('w=',model.linear.weight.item())
print('b=',model.linear.bias.item())
x_test = torch.tensor([[4.0]])
y_test = model(x_test)
print('y_pred=',y_test.data)
#画loss曲线图
plt.plot(epoch_list,loss_list)
plt.xlabel('epoch')
plt.ylabel('loss')
plt.title('Rprop')
plt.show()