pytorch学习笔记——模型的保存与加载以及获取模型参数
目录
- 一、保存和加载
- 二、模型参数
-
- print(model)
- print(model.state_dict())
- print(type(model))
- print(model.named_parameters())中的name
- 总结:
- 一、module.state_dict()
- 二、module.named_parameters()
- 三、model.parameters()
PyTorch模型保存深入理解
一、保存和加载
pytorch保存和加载的函数:torch.save(name,path)、torch.load(path)保存的是什么加载的就是什么(比如字典),torch.save()保存的是一个字典,加载的时候也是一个字典。model.state_dict()与model.load_state_dict()对应,optimizer.state_dict()与optimizer.load_state_dict()对应。
pytorch 中的 state_dict 是一个简单的python的字典对象,将每一层与它的对应参数建立映射关系.(如model的每一层的weights及偏置等等)
(注意,只有那些参数可以训练的layer才会被保存到模型的state_dict中,如卷积层,线性层等等)
优化器对象Optimizer也有一个state_dict,它包含了优化器的状态以及被使用的超参数(如lr, momentum,weight_decay等)
参考链接
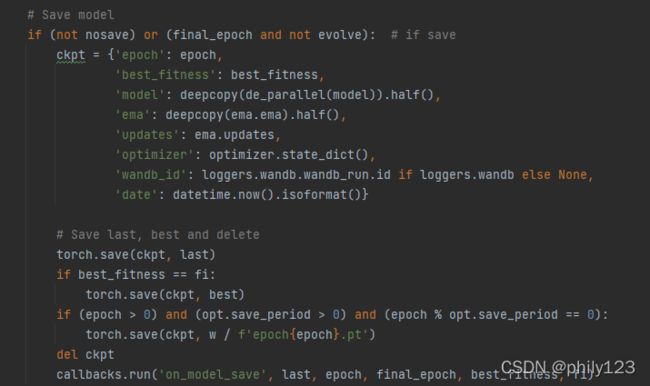
# 保存模型参数,优化器参数等
# 假设网络为model = Net(), optimizer = optim.Adam(model.parameters(), lr=args.lr), 假设在某个epoch,我们要保存模型参数,优化器参数以及epoch
#1. 先建立一个字典,保存三个参数:
state = {‘net':model.state_dict(), 'optimizer':optimizer.state_dict(), 'epoch':epoch}
#2.调用torch.save():其中dir表示保存文件的绝对路径+保存文件名,如'/home/qinying/Desktop/modelpara.pth'
torch.save(state, dir)
# 读取之前保存的网络模型参数等
checkpoint = torch.load(dir)
model.load_state_dict(checkpoint['net'])
optimizer.load_state_dict(checkpoint['optimizer'])
start_epoch = checkpoint['epoch'] + 1
#保存和加载整个模型
torch.save(model_object, 'model.pkl')
model = torch.load('model.pkl')
# 仅保存和加载模型参数(推荐使用)
torch.save(model_object.state_dict(), 'params.pkl')
model_object.load_state_dict(torch.load('params.pkl'))
torch.save(model.state_dict(), path)
model.load_state_dict(torch.load(path))
二、模型参数
pytorch中获取模型参数:state_dict和parameters两个方法的差异比较
import argparse
from models.common import *
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--weights', type=str, default='runs/train/exp3/weights/last.pt', help='weights path')
opt = parser.parse_args()
# Load pytorch model
model = torch.load(opt.weights, map_location=torch.device('cpu'))
print(model)
#print(type(model))
model = model['model']
print(model.state_dict())
print(type(model))
for name, parameters in model.named_parameters():
# print(name,':',parameters.size())
print(name)
# print(parameters.dtype)
print(model)
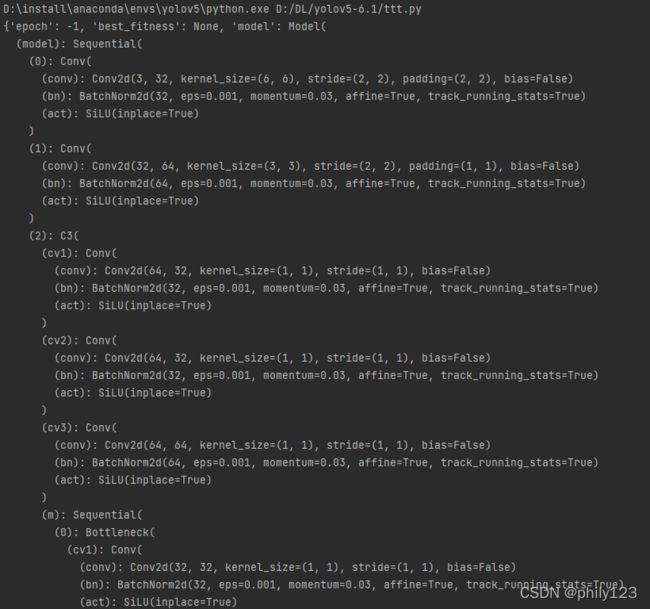
print(model.state_dict())
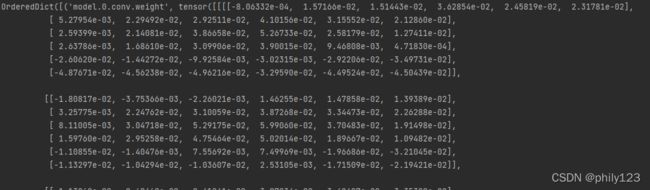
print(type(model))
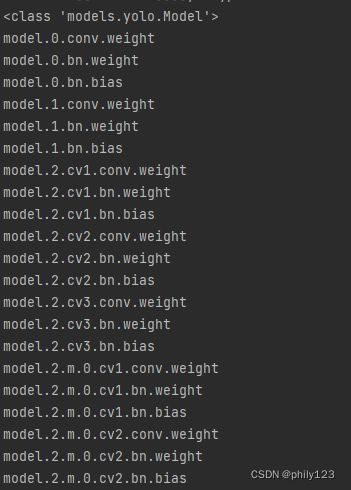
print(model.named_parameters())中的name
总结:
可以看出来YOLOV5保存的是一个字典,其中键包括epoch、best_fitness、model、optimizer等,而键model对应的值是整个模型,不是model.state_dict()。这个模型对象具有state_dict()这个成员函数,model.state_dict()是一个pytorch类型的字典对象。同时也可以发现model的前几层是conv层,是由卷积、bn、和激活函数这三层组成的,通过model.named_parameters()和model.state_dict()打印的是可以训练的参数层,如前面几层的conv.weights、bn.weights、bn.bias。
一、module.state_dict()
返回的是一个顺序字典,key为层名,值为层的权值参数或者偏置参数。
作用:1、查看每一层与它的对应关系;2、模型保存时使用。
二、module.named_parameters()
返回的是一个生成器元素是元组、元组第一个值是层名,第二个值是权重参数或者偏置参数。
yolov5s模型参数:
for k, v in model.named_parameters():
print("k:",k)
print("v:",v.shape)
k: model.0.conv.weight
v: torch.Size([32, 3, 6, 6])
k: model.0.bn.weight
v: torch.Size([32])
k: model.0.bn.bias
v: torch.Size([32])
k: model.1.conv.weight
v: torch.Size([64, 32, 3, 3])
k: model.1.bn.weight
v: torch.Size([64])
k: model.1.bn.bias
v: torch.Size([64])
k: model.2.cv1.conv.weight
v: torch.Size([32, 64, 1, 1])
k: model.2.cv1.bn.weight
v: torch.Size([32])
k: model.2.cv1.bn.bias
v: torch.Size([32])
k: model.2.cv2.conv.weight
v: torch.Size([32, 64, 1, 1])
k: model.2.cv2.bn.weight
v: torch.Size([32])
k: model.2.cv2.bn.bias
v: torch.Size([32])
k: model.2.cv3.conv.weight
v: torch.Size([64, 64, 1, 1])
k: model.2.cv3.bn.weight
v: torch.Size([64])
k: model.2.cv3.bn.bias
v: torch.Size([64])
k: model.2.m.0.cv1.conv.weight
v: torch.Size([32, 32, 1, 1])
k: model.2.m.0.cv1.bn.weight
v: torch.Size([32])
k: model.2.m.0.cv1.bn.bias
v: torch.Size([32])
k: model.2.m.0.cv2.conv.weight
v: torch.Size([32, 32, 3, 3])
k: model.2.m.0.cv2.bn.weight
v: torch.Size([32])
k: model.2.m.0.cv2.bn.bias
v: torch.Size([32])
k: model.3.conv.weight
v: torch.Size([128, 64, 3, 3])
k: model.3.bn.weight
v: torch.Size([128])
k: model.3.bn.bias
v: torch.Size([128])
k: model.4.cv1.conv.weight
v: torch.Size([64, 128, 1, 1])
k: model.4.cv1.bn.weight
v: torch.Size([64])
k: model.4.cv1.bn.bias
v: torch.Size([64])
k: model.4.cv2.conv.weight
v: torch.Size([64, 128, 1, 1])
k: model.4.cv2.bn.weight
v: torch.Size([64])
k: model.4.cv2.bn.bias
v: torch.Size([64])
k: model.4.cv3.conv.weight
v: torch.Size([128, 128, 1, 1])
k: model.4.cv3.bn.weight
v: torch.Size([128])
k: model.4.cv3.bn.bias
v: torch.Size([128])
k: model.4.m.0.cv1.conv.weight
v: torch.Size([64, 64, 1, 1])
k: model.4.m.0.cv1.bn.weight
v: torch.Size([64])
k: model.4.m.0.cv1.bn.bias
v: torch.Size([64])
k: model.4.m.0.cv2.conv.weight
v: torch.Size([64, 64, 3, 3])
k: model.4.m.0.cv2.bn.weight
v: torch.Size([64])
k: model.4.m.0.cv2.bn.bias
v: torch.Size([64])
k: model.4.m.1.cv1.conv.weight
v: torch.Size([64, 64, 1, 1])
k: model.4.m.1.cv1.bn.weight
v: torch.Size([64])
k: model.4.m.1.cv1.bn.bias
v: torch.Size([64])
k: model.4.m.1.cv2.conv.weight
v: torch.Size([64, 64, 3, 3])
k: model.4.m.1.cv2.bn.weight
v: torch.Size([64])
k: model.4.m.1.cv2.bn.bias
v: torch.Size([64])
k: model.5.conv.weight
v: torch.Size([256, 128, 3, 3])
k: model.5.bn.weight
v: torch.Size([256])
k: model.5.bn.bias
v: torch.Size([256])
k: model.6.cv1.conv.weight
v: torch.Size([128, 256, 1, 1])
k: model.6.cv1.bn.weight
v: torch.Size([128])
k: model.6.cv1.bn.bias
v: torch.Size([128])
k: model.6.cv2.conv.weight
v: torch.Size([128, 256, 1, 1])
k: model.6.cv2.bn.weight
v: torch.Size([128])
k: model.6.cv2.bn.bias
v: torch.Size([128])
k: model.6.cv3.conv.weight
v: torch.Size([256, 256, 1, 1])
k: model.6.cv3.bn.weight
v: torch.Size([256])
k: model.6.cv3.bn.bias
v: torch.Size([256])
k: model.6.m.0.cv1.conv.weight
v: torch.Size([128, 128, 1, 1])
k: model.6.m.0.cv1.bn.weight
v: torch.Size([128])
k: model.6.m.0.cv1.bn.bias
v: torch.Size([128])
k: model.6.m.0.cv2.conv.weight
v: torch.Size([128, 128, 3, 3])
k: model.6.m.0.cv2.bn.weight
v: torch.Size([128])
k: model.6.m.0.cv2.bn.bias
v: torch.Size([128])
k: model.6.m.1.cv1.conv.weight
v: torch.Size([128, 128, 1, 1])
k: model.6.m.1.cv1.bn.weight
v: torch.Size([128])
k: model.6.m.1.cv1.bn.bias
v: torch.Size([128])
k: model.6.m.1.cv2.conv.weight
v: torch.Size([128, 128, 3, 3])
k: model.6.m.1.cv2.bn.weight
v: torch.Size([128])
k: model.6.m.1.cv2.bn.bias
v: torch.Size([128])
k: model.6.m.2.cv1.conv.weight
v: torch.Size([128, 128, 1, 1])
k: model.6.m.2.cv1.bn.weight
v: torch.Size([128])
k: model.6.m.2.cv1.bn.bias
v: torch.Size([128])
k: model.6.m.2.cv2.conv.weight
v: torch.Size([128, 128, 3, 3])
k: model.6.m.2.cv2.bn.weight
v: torch.Size([128])
k: model.6.m.2.cv2.bn.bias
v: torch.Size([128])
k: model.7.conv.weight
v: torch.Size([512, 256, 3, 3])
k: model.7.bn.weight
v: torch.Size([512])
k: model.7.bn.bias
v: torch.Size([512])
k: model.8.cv1.conv.weight
v: torch.Size([256, 512, 1, 1])
k: model.8.cv1.bn.weight
v: torch.Size([256])
k: model.8.cv1.bn.bias
v: torch.Size([256])
k: model.8.cv2.conv.weight
v: torch.Size([256, 512, 1, 1])
k: model.8.cv2.bn.weight
v: torch.Size([256])
k: model.8.cv2.bn.bias
v: torch.Size([256])
k: model.8.cv3.conv.weight
v: torch.Size([512, 512, 1, 1])
k: model.8.cv3.bn.weight
v: torch.Size([512])
k: model.8.cv3.bn.bias
v: torch.Size([512])
k: model.8.m.0.cv1.conv.weight
v: torch.Size([256, 256, 1, 1])
k: model.8.m.0.cv1.bn.weight
v: torch.Size([256])
k: model.8.m.0.cv1.bn.bias
v: torch.Size([256])
k: model.8.m.0.cv2.conv.weight
v: torch.Size([256, 256, 3, 3])
k: model.8.m.0.cv2.bn.weight
v: torch.Size([256])
k: model.8.m.0.cv2.bn.bias
v: torch.Size([256])
k: model.9.cv1.conv.weight
v: torch.Size([256, 512, 1, 1])
k: model.9.cv1.bn.weight
v: torch.Size([256])
k: model.9.cv1.bn.bias
v: torch.Size([256])
k: model.9.cv2.conv.weight
v: torch.Size([512, 1024, 1, 1])
k: model.9.cv2.bn.weight
v: torch.Size([512])
k: model.9.cv2.bn.bias
v: torch.Size([512])
k: model.10.conv.weight
v: torch.Size([256, 512, 1, 1])
k: model.10.bn.weight
v: torch.Size([256])
k: model.10.bn.bias
v: torch.Size([256])
k: model.13.cv1.conv.weight
v: torch.Size([128, 512, 1, 1])
k: model.13.cv1.bn.weight
v: torch.Size([128])
k: model.13.cv1.bn.bias
v: torch.Size([128])
k: model.13.cv2.conv.weight
v: torch.Size([128, 512, 1, 1])
k: model.13.cv2.bn.weight
v: torch.Size([128])
k: model.13.cv2.bn.bias
v: torch.Size([128])
k: model.13.cv3.conv.weight
v: torch.Size([256, 256, 1, 1])
k: model.13.cv3.bn.weight
v: torch.Size([256])
k: model.13.cv3.bn.bias
v: torch.Size([256])
k: model.13.m.0.cv1.conv.weight
v: torch.Size([128, 128, 1, 1])
k: model.13.m.0.cv1.bn.weight
v: torch.Size([128])
k: model.13.m.0.cv1.bn.bias
v: torch.Size([128])
k: model.13.m.0.cv2.conv.weight
v: torch.Size([128, 128, 3, 3])
k: model.13.m.0.cv2.bn.weight
v: torch.Size([128])
k: model.13.m.0.cv2.bn.bias
v: torch.Size([128])
k: model.14.conv.weight
v: torch.Size([128, 256, 1, 1])
k: model.14.bn.weight
v: torch.Size([128])
k: model.14.bn.bias
v: torch.Size([128])
k: model.17.cv1.conv.weight
v: torch.Size([64, 256, 1, 1])
k: model.17.cv1.bn.weight
v: torch.Size([64])
k: model.17.cv1.bn.bias
v: torch.Size([64])
k: model.17.cv2.conv.weight
v: torch.Size([64, 256, 1, 1])
k: model.17.cv2.bn.weight
v: torch.Size([64])
k: model.17.cv2.bn.bias
v: torch.Size([64])
k: model.17.cv3.conv.weight
v: torch.Size([128, 128, 1, 1])
k: model.17.cv3.bn.weight
v: torch.Size([128])
k: model.17.cv3.bn.bias
v: torch.Size([128])
k: model.17.m.0.cv1.conv.weight
v: torch.Size([64, 64, 1, 1])
k: model.17.m.0.cv1.bn.weight
v: torch.Size([64])
k: model.17.m.0.cv1.bn.bias
v: torch.Size([64])
k: model.17.m.0.cv2.conv.weight
v: torch.Size([64, 64, 3, 3])
k: model.17.m.0.cv2.bn.weight
v: torch.Size([64])
k: model.17.m.0.cv2.bn.bias
v: torch.Size([64])
k: model.18.conv.weight
v: torch.Size([128, 128, 3, 3])
k: model.18.bn.weight
v: torch.Size([128])
k: model.18.bn.bias
v: torch.Size([128])
k: model.20.cv1.conv.weight
v: torch.Size([128, 256, 1, 1])
k: model.20.cv1.bn.weight
v: torch.Size([128])
k: model.20.cv1.bn.bias
v: torch.Size([128])
k: model.20.cv2.conv.weight
v: torch.Size([128, 256, 1, 1])
k: model.20.cv2.bn.weight
v: torch.Size([128])
k: model.20.cv2.bn.bias
v: torch.Size([128])
k: model.20.cv3.conv.weight
v: torch.Size([256, 256, 1, 1])
k: model.20.cv3.bn.weight
v: torch.Size([256])
k: model.20.cv3.bn.bias
v: torch.Size([256])
k: model.20.m.0.cv1.conv.weight
v: torch.Size([128, 128, 1, 1])
k: model.20.m.0.cv1.bn.weight
v: torch.Size([128])
k: model.20.m.0.cv1.bn.bias
v: torch.Size([128])
k: model.20.m.0.cv2.conv.weight
v: torch.Size([128, 128, 3, 3])
k: model.20.m.0.cv2.bn.weight
v: torch.Size([128])
k: model.20.m.0.cv2.bn.bias
v: torch.Size([128])
k: model.21.conv.weight
v: torch.Size([256, 256, 3, 3])
k: model.21.bn.weight
v: torch.Size([256])
k: model.21.bn.bias
v: torch.Size([256])
k: model.23.cv1.conv.weight
v: torch.Size([256, 512, 1, 1])
k: model.23.cv1.bn.weight
v: torch.Size([256])
k: model.23.cv1.bn.bias
v: torch.Size([256])
k: model.23.cv2.conv.weight
v: torch.Size([256, 512, 1, 1])
k: model.23.cv2.bn.weight
v: torch.Size([256])
k: model.23.cv2.bn.bias
v: torch.Size([256])
k: model.23.cv3.conv.weight
v: torch.Size([512, 512, 1, 1])
k: model.23.cv3.bn.weight
v: torch.Size([512])
k: model.23.cv3.bn.bias
v: torch.Size([512])
k: model.23.m.0.cv1.conv.weight
v: torch.Size([256, 256, 1, 1])
k: model.23.m.0.cv1.bn.weight
v: torch.Size([256])
k: model.23.m.0.cv1.bn.bias
v: torch.Size([256])
k: model.23.m.0.cv2.conv.weight
v: torch.Size([256, 256, 3, 3])
k: model.23.m.0.cv2.bn.weight
v: torch.Size([256])
k: model.23.m.0.cv2.bn.bias
v: torch.Size([256])
k: model.24.m.0.weight
v: torch.Size([255, 128, 1, 1])
k: model.24.m.0.bias
v: torch.Size([255])
k: model.24.m.1.weight
v: torch.Size([255, 256, 1, 1])
k: model.24.m.1.bias
v: torch.Size([255])
k: model.24.m.2.weight
v: torch.Size([255, 512, 1, 1])
k: model.24.m.2.bias
v: torch.Size([255])
三、model.parameters()
返回一个生成器,元素是参数,也就是module.named_parameters()没有参数名。