【PYTORCH >> ONNX >> TENSORRT】自定义plug-in算子解析onnx模型生成引擎详细步骤
torch onnx tensorrt自定义plug-in解析onnx模型生成引擎详细步骤
- 博客概要
-
- 为什么要写plug-in
- pytorch TensorRT环境版本
- TensorRT项目介绍
- 从torch出发自定义一个算子
-
- 在pytorch中自定义算子并且被onnx正确识别
- TensorRT自定义插件撰写
-
- 从trtexec说起
-
- 更新两个重要的库
- 撰写自定义算子
-
- 自定义的gelu算子
- 自定义算子流程步骤
- 两个trtexec依赖的重要动态库的替换
- 运行trtexec得到tensorrt引擎
- tensorrt引擎inference和python运行结果对比:
- 后期可以做的更多事情
- 结论
博客概要
网络上可以找到许多如何在TensorRT引擎中自己添加plug-in算子的博客,但是他们的共同特点都是仅仅记录了一小部分细节问题,导致读者无法全面的了解这一套流程的详细方案,甚至有一些博客可能由于TensorRT的版本问题,甚至调用了一些不支持的API,导致我在进行实践的时候走了不少弯路,在这里本博客从代码层面进行对整个流程和一些细节关键点进行了详细全面的总结,对自己是个备忘的同时也希望能帮助到阅读本博客的童鞋。
为什么要写plug-in
一般而言是因为tensorrt原生不支持一些算子,为了整个网络的其他算子仍然可以被转化为tensorrt引擎所以要进行用户自定义,对于更高阶的用户,也许想把tensorrt支持的算子替换掉,这仍是可行的,但后者不需要进行本博客一样完全的模型转换过程而仅仅是在tensorrt项目内部进行核函数的撰写和算子的手动替换(因为tensorrt算子和onnx模型节点已经建立好了内部的替换映射关系)。
pytorch TensorRT环境版本
pytorch: 1.9.0 + cu111 .
TensorRT: cuda11.4 + cudnn8.2.1.32 + tensorrt 8.4.1.5 .
安装好上述环境后,对于自定义plug-in还是不充足的,还需要在github上下载tensorrt的项目源代码,链接如下:
链接: TensorRT项目链接
由于该项目添加了一系列如protobuf等多个子模块项目链接,手动点击下载是相对麻烦的,因此需要参照该项目的readme进行git clone操作,具体命令如下:
git clone -b master https://github.com/nvidia/TensorRT TensorRT
cd TensorRT
git submodule update --init --recursive
第一行命令和第三行命令都是需要下载的,如果太慢作者的解决方案是给linux挂了一个VPN代理,其他方式都是可以的这里就不再赘述了就希望大家可以各显神通啦。下载好了该项目后,参照readme进行编译即可,蛋疼的是他会继续在内部进行protobuf依赖项目下载,所以必须必须要有VPN!!!否则完全可能出现下载卡死的情况。这里作者还发现了一个点,在NVIDIA官方下载的tensorrt deb安装包安装出的libnvinfer_plugin.so动态库为版本为8.4.1,但是在github tensorrt项目中编译出的版本为8.2.0。8.4.1库内已经自带并注册好的plugin算子约63个,而8.2.0版本仅有40多个,因为不影响后续的开发工作具体缺少了哪一些算子没有去深究了,需要知道的是这样进行下去自己写的plugin是添加在8.2.0的动态库版本上面的,因为形成的新的动态库会直接替换掉旧的动态库。
TensorRT项目介绍
从github下载下来的TensorRT项目,可以大致分为最重要的三个部分:他们分别是
- plugin 内部有一些tensorrt自带的开源plugin,有了这些文件,我们可以非常高效的依样画葫芦定义自己的plugin。
- parser 如果用户准备在tensorrt内部使用API一层一层的把网络搭建起来,则该文件夹对于上述用户而言是没用的,但当你的模型是从onnx或者caffe等模型转换过来的,tensorrt并不知道该算子应该如何关联转换,是会在build engine阶段报错的,本项目由于是torch onnx trt转换,因此是需要去修改parser内部文件内容,使得trt认识我们自定义的算子在onnx计算图内对应的到底是什么东西,在这里也被称作op_type。
- samples 学习使用,对于本博客可以忽略,但是这些代码是学习trt非常有用的开源工具,在trt项目最外层的cmakelist内,可以将对samples的编译关闭来加快编译时间

完成上述准备工作后,我们要从源头pytorch开始出发了。
从torch出发自定义一个算子
本文章用gelu激活函数举例,在torch.nn中是有gelu的实现的,但当你导出定义的gelu模型为onnx,该模型会让你感觉好乱好乱,可以认为onnx当前暂时是不支持gelu的(op version 11),但是它很聪明,他知道gelu无非就是加减乘除一顿输出就完事了,因此onnx会给你一个这样的计算图:

实际上,pytorch内部我是这么去定义这个模型的:
class MyNet(nn.Module):
def __init__(self):
super(MyNet, self).__init__()
self.gelu = nn.GELU()
def forward(self, x):
return self.gelu(self.gelu(x))
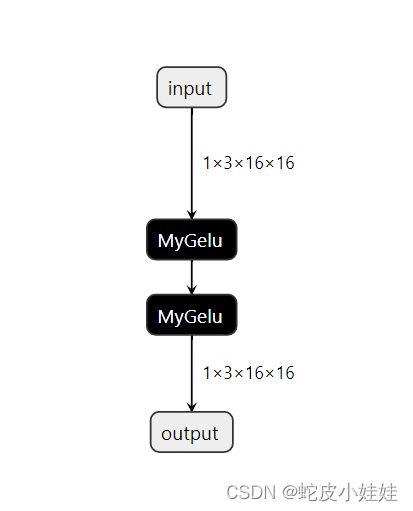
我们知道这样的onnx模型肯定是可以转换为trt模型的,因为该计算图内都是一些最基本的计算单元的组合。由于trt是一个闭源软件,作者不是特别肯定其内部会不会对这样的算子进行图融合操作(当然可以用nsight去看看trt核函数的调用堆栈去尽可能的推断一下,这与本文无关不再赘述)。如果trt内部做了而且做的还蛮好,ok那本文到此结束 XD。假设trt执行的就是上述计算图,因为gelu并不是一个计算密度很高的算子,因此该算子带来的latency主要是由访存体现的,对于global memory一读一写是耗时的最大贡献来源,所以我们希望该算子可以长成这样:
在pytorch中自定义算子并且被onnx正确识别
直接上pytorch官方自定义算子链接:extending pytorch
由于我们仅仅是需要有一个特定的算子符号,而不是需要将该模型拿来训练,因此我们是只需要对于forward和symbolic函数进行重写,而backword函数是无需重写的。
import torch
import torch.nn as nn
from torch.autograd import Function
class MyGelu(Function):
@staticmethod
def forward(ctx, input, add_num):
return nn.GELU()(input) + add_num
@staticmethod
def symbolic(g, input, add):
return g.op("MyGelu", input, add_num_f=add)
mygelu_ = MyGelu.apply
class TwoMyGelu(nn.Module):
def __init__(self):
super(TwoMyGelu, self).__init__()
def forward(self, x):
x = mygelu_(x, 0.2)
x = mygelu_(x, 1.5)
return x
该类型撰写注意事项有:
- 首先要继承torch.autograd.Function类,重写该子类的forward和symbolic成员函数,其中forward的第一个参数是ctx,symbolic 的第一个参数是g,对于symbolic的op方法调用,第一个传入的字符串就是该算子在onnx计算图内的类型了,后续我们在tensorrt内去解析onnx计算图也是去寻找这个名字,因此该名字是关联这几套工具的标识。
- 除此之外,本实现还随意加了一个名为add_num的参数,只是为了告诉读者这些参数是可以随意添加作为参数的,由于该参数是float类型,因此在symbolic函数内,该参数的形参表示必须写为add_num_f。如果不这么写torch内会报错并给出详细的解释。
- 最最大胆并且值得注意的地方是,这个forward函数我可以什么操作也不实现,只是按照我这个算子正常的执行方式返回一堆0即可,只需要保证算子返回值的总数和算子每一个返回值的shape是正确的即可。因为我们不需要在pytorch或者onnx内去跑通整个模型,而仅仅是在onnx这个中间转换格式工具内有一个算子占用一个坑位,所以只需要告诉这个中间模型必要的信息即可,因为后期该算子真正是如何计算的是由我们后期撰写的tensorrt plugin所替换掉的,所以这里的forward实现数值上的正确与否是没有意义的。
查看onnx计算图中第一个MyGelu算子的内部细节如图:
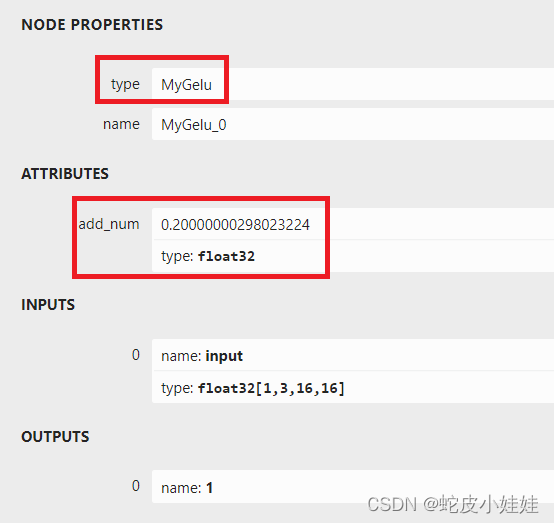
进行如上操作后该模型确实只有两个算子了满足了我们一开始的期望,且节点type,节点内含的信息,节点的输入输出个数以及shape都已经完全的被onnx格式所识别,可以进行
后面的onnx转化为tensorrt引擎的操作了。
TensorRT自定义插件撰写
从trtexec说起
熟悉模型部署的童鞋知道,trtexec可以将onnx等格式的深度学习模型转换为序列化后的tensorrt engine保存在硬盘内,首先,我们可以通过ldd命令查看该程序依赖了哪些动态库,结果有:
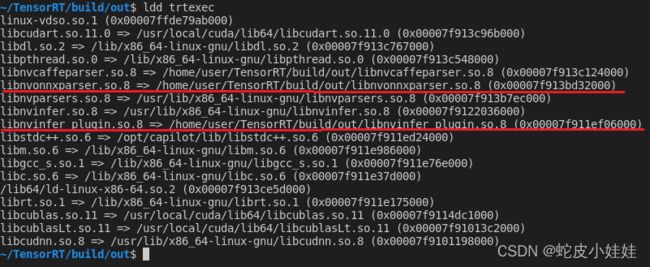
图中画出红线的两个动态库的内容正是决定trtexec能否识别自定义算子的因素,当我们使用官方的tensorrt动态库时并且build我们生成的含有MyGelu算子的onnx模型时,trt会如下报错:
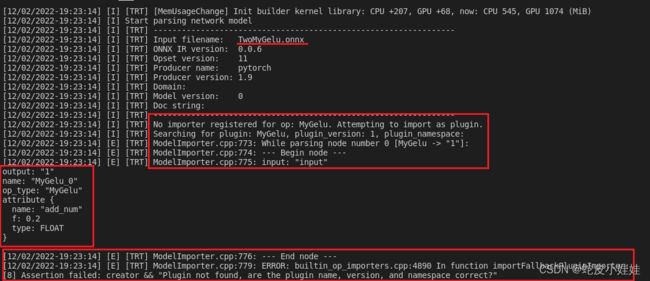
当tensorrt内置OP无法和onnx模型中的节点对应时,它会将该节点视为一个plugin算子从而在注册的plugin列表内去寻找该plugin op_type是否被注册,也就是终端内的那一句Searching for plugin:MyGelu,当然现在是无法找到的,最终build过程以失败告终。
更新两个重要的库
当我们执行trtexec时,它依赖的两个重要的库在上一节图片中已经标红出来了,分别是libnvonnxparser.so以及libnvinfer_plugin.so。在我们下载的tensorrt项目内,添加自定义算子后重新编译就是为了更新替换这两个库,使得他们记录好了我们定义的算子信息,从而在后续使用依赖它们的trtexec命令时,自然也能识别新的算子了。
撰写自定义算子
自定义的gelu算子
由于tensorrt项目中是已经包含了开源的gelu算子,本文章内就不再复述,该文件内容如下:
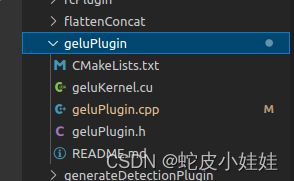
当我们写一个新的算子时,文件夹结构可以和该geluPlugin文件夹保持完全一致。
自定义算子流程步骤
自定义一个算子可以参照最简单的gelu算子的步骤,分别有:
- 继承nvinfer1::IPluginV2DynamicExt类,重写该基类的纯虚函数,要重写的纯虚函数在项目中有完整的呈现。
- 继承nvinfer1::IPluginCreator类,重写该基类的纯虚函数,要重写的纯虚函数在项目中有完整的呈现。creator类主要记录了该plugin的名字 版本 命名空间等信息,并且可以生成该plugin类型,返回继承关系内更上层的nvinfer1::IPluginV2*指针。可以认为creator类是一个工厂类。
- 在实现plugin和creator的cpp文件中对该plugin的creator进行注册,注意是对creator进行注册,代码如下:
REGISTER_TENSORRT_PLUGIN(GeluPluginDynamicCreator);
通过跳转发现该宏的定义有:
template <typename T>
class PluginRegistrar
{
public:
PluginRegistrar()
{
getPluginRegistry()->registerCreator(instance, "");
}
private:
//! Plugin instance.
T instance{};
};
} // namespace nvinfer1
#define REGISTER_TENSORRT_PLUGIN(name) \
static nvinfer1::PluginRegistrar<name> pluginRegistrar##name {}
#endif // NV_INFER_RUNTIME_H
可以知道这是一个经典的利用代理类对象的构造函数进行注册的经典套路,这是一个全局静态对象的创建,因此当编译时该对象已经生成,所以我们的creator成功被注册进入了算子库内。
-
(选用)由tensorrt官方文档或源代码可以知道,3步骤内的注册方式为静态注册,且注册的算子命名空间为默认的""空间,可能会引起一些内存占用的增加和命名的冲突,也可以采用动态注册的方式进行注册,该方法是在inferPlugin.cpp文件的initLibNvInferPlugins函数内,添加自己定义的plugin注册。由于这是一个函数的定义,因此当我们需要时再调用该函数完成注册可以潜在的减少内存的消耗,除此之外该动态注册的方法也可以给算子附加一个命名空间避免命名冲突。但是!!!在作者实际使用过程中,如果将静态注册的代码注释掉而仅仅使用动态注册时,build engine中途trt会报出算子无法序列化的错误而且通过代码搜索找不到跟报错信息有关的代码和文件,因此作者认为可能该代码已经被编译到内置的库内了从而无法进一步判断为何会报出该结点无法正常序列化的错误,可以确认的是官方的geluplugin肯定有一个正确的序列化实现,网络上找了好些博客说是因为没有调用initLibNvInferPlugins,但作者实验发现并不能解决该问题。 因此最终作者认为就进行静态注册也无可厚非,没有命名空间那就让自己的算子名字更加的详实一点,写了plugin算子就应该使用所以静态提前加载也是可以接受的。这点错误不用过于纠结,如果有童鞋也遇到同样的问题可以反馈沟通解决方案。具体的报错信息为:
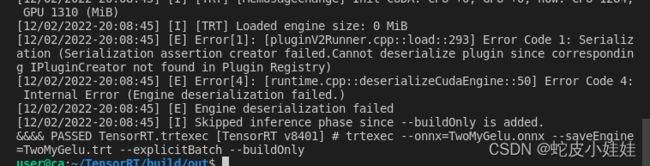
静态注册或者动态注册完成后,仅仅代表该算子已经被tensorrt所支持,当你使用API去一层一层的搭建网络时,你可以使用该算子作为网络中的一个或者多个节点,但是我们是希望trtexec可以聪明的识别onnx内同名(同op_type)的算子并且将该算子用我们实现的算法进行表达,因此接下来的一个步骤为有: -
为使得trtexec命令(底层是onnxparser)可以识别MyGelu算子,需要修改parsers/onnx/builtin_op_importers.cpp文件,该文件内已经有很多常见的算子被注册,如Conv Add Mul… 该文件内需要添加的具体的代码如下:
//这是一个宏,展开后本质是一个函数定义,该函数的形参有ctx, node, inputs
DEFINE_BUILTIN_OP_IMPORTER(MyGelu)
{
//一个简单的断言
ASSERT(inputs.at(0).is_tensor(), ErrorCode::kUNSUPPORTED_NODE);
//取出输入的tensor
nvinfer1::ITensor* tensor = &inputs.at(0).tensor();
//获得该onnx节点的属性
OnnxAttrs attrs(node, ctx);
//本博客该代码没有实际意义,只是示意如何从onnx节点中读取出定义在节点内的常数或张量权重的方法。
float add_num = attrs.get<float>("add_num");
//取得plugin注册表
auto regis = getPluginRegistry();
//取得对应的plugin
nvinfer1::IPluginCreator* gelu_creator = getPluginRegistry()->getPluginCreator("CustomGeluPluginDynamic", "1");
//一些对plugin属性的描述,用于传入creator创建出一个具体的plugin实例
//一个plugin具体有哪些属性是在定义时决定的,在这里这么写只是为了符合nvidia定义的gelu的属性,对于读者自己写的plugin
//自身肯定知道应该传入什么PluginFieldCollection字段信息。
nvinfer1::PluginFieldCollection plugInFC;
nvinfer1::PluginField* pf = new nvinfer1::PluginField();
int* p_int = new int(0); //原谅我懒得delete了
pf->name = "type_id";
pf->length = 1;
pf->type = nvinfer1::PluginFieldType::kINT32;
pf->data = p_int;
plugInFC.nbFields = 1;
plugInFC.fields = pf;
//创建一个具体的tensorrt plugin节点
nvinfer1::IPluginV2* gelu_plugin_obj = gelu_creator->createPlugin("gelu1", &plugInFC);
//将该结点加入到已有的网络当中
nvinfer1::IPluginV2Layer* gelu_layer = ctx->network()->addPluginV2(&tensor, 1, *gelu_plugin_obj);
//获得该层的输出,因为已经知道只有一个输出,直接取0号索引即可
nvinfer1::ITensor* output = gelu_layer->getOutput(0);
//本函数输出的结构体为NodeImportResult,对输出的tensor进行一些简单的结构体包装即可。
std::vector<TensorOrWeights> vec_out;
vec_out.push_back(TensorOrWeights(output));
NodeImportResult res(vec_out);
return res;
}
对DEFINE_BUILTIN_OP_IMPORTER定义理解可参考链接:DEFINE_BUILTIN_OP_IMPORTER
完成上述所有工作后,tensorrt项目进行整体编译,编译通过后就基本可以宣布成功啦!
两个trtexec依赖的重要动态库的替换
由上面的描述可以知道,当libnvonnxparser.so与libnvinfer_plugin.so内已经可以正确识别自定义的算子后,依赖这两个库的可执行程序trtexec自然也就有了解析含有MyGelu节点的onnx模型的能力,这里有一个细节的地方是,编译parser和plugin会分别生成的对应的两个软链接xxx.so xxx.so.8和真正的静动态库xxx.so.8.2.0,ldd查看到的trtexec是需要去找到xxx.so.8这个符号的,所以LD_LIBRARY_PATH环境变量要找得到xxx.so.8的路径且保证其要正确的链接到xxx.so.8.2.0即可,至于最开始安装tensorrt deb包得到的so.8.4.1这个库,我们就没有将其删除或者移动了,因为后续我们还是想保留这个库的。
运行trtexec得到tensorrt引擎
命令行以及tensorrt输出信息如下图所示:
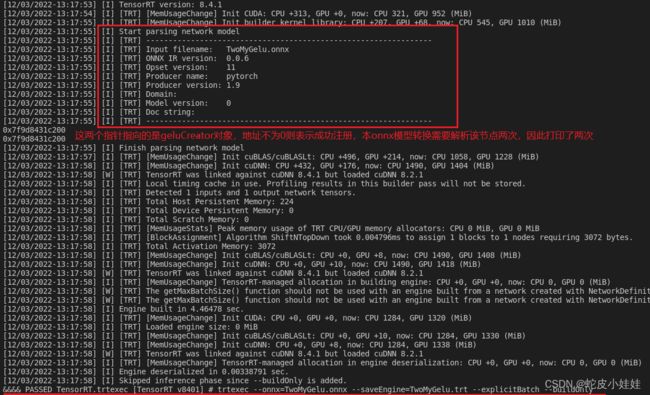
得到引擎后,需要最终做一个python端与部署端的对比验证。
tensorrt引擎inference和python运行结果对比:
python端验证结果:
model = TwoMyGelu().cuda()
t = torch.tensor([2.0], dtype=torch.float32).cuda()
print(model(t))
#result
tensor([1.9050], device='cuda:0')
tensorrt端推理结果:
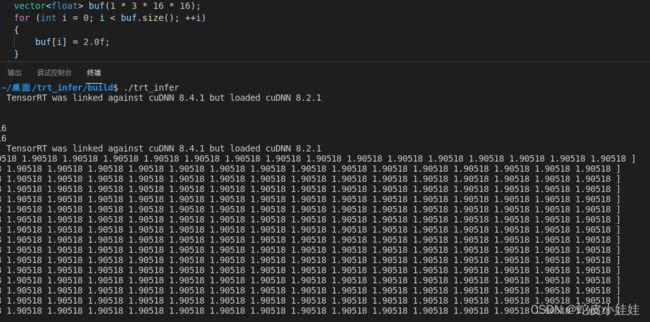
tensorrt推理过程即为标准的加载引擎反序列化,完成上下文设置、绑定输入输出推理得到结果,此处不再赘述。
这两个平台内得到的推理结果看起来是有一定差异的,完全可能是gelu算子在两个平台内的一些常数的截断、精度不同造成的影响,如果对精度要求较高,则需要用户进行更细致查看源代码的实现进行对比甚至修改源代码实现,在这里可以认为两个平台的结果是一致的。
后期可以做的更多事情
- 创建一个多输入或者多输出的自定义节点
- 创建一个内部参数不仅有常量而且还有tensor weights的节点
- 真正从头开始在tensorrt plugin内部构造一个自定义节点(本博客是直接利用了一个已经有的gelu节点,主要是因为onnx不支持gelu,而torch和tensorrt内部其实是有gelu的单个算子是实现的,当然tensorrt只是实现了也没注册进入onnxparser的builtin op库内)
- 参照tensorrt plugin实现,探索如何创建支持 fp16 和 int8 的自定义节点
- 对比未优化的被拆成多个算子的gelu节点和本博客优化后的gelu节点是否会有性能上的差异以及差异的来源是否是访存引起(需要搭配nsys ncu等工具)
这些工作都是在本博客的基础上更加深入的理解nvidia tensorrt的工作了,本博客也就不再详细深入的去探索了,但有了本博客系统性从一个最简单的例子介绍从pytorch >> onnx >> tensorrt 模型转换的介绍基础后,后续的工作也有了参考的起点。
结论
这个博客没有太多高深的技术内容,但博主在寻找相关技术资料时,发现每一个资料都仅仅描述了本技术路线的某一些小点,且有一些代码的实现甚至都有一些错误存在,为了让自己系统的总结回顾该技术并且分享给大家,因此总结了这一篇博客,有一些理解上的错误和未尽的工作,欢迎回复讨论。