mnist数据集训练_分类实例:MNIST数据集

01
MNIST数据集
读取数据
MNIST datasets 有70000个手写数字图片,每一个都标注了对应的数字。
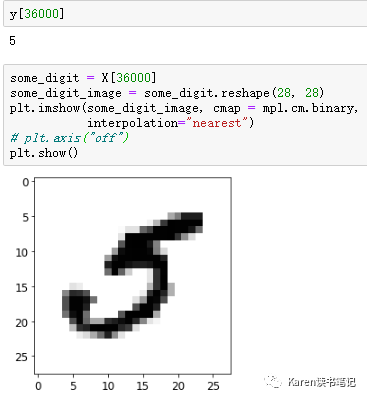
每一张图片有784个特征,因为每一张图片有(28*28)784个像素点,每一个像素点的强度用0(白色)到255(黑色)表示。
分割测试集和训练集
将训练集打乱。有些算法对于训练实例的顺序很敏感。

部分数据集

02
训练二分类器
训练目标:识别数字是不是5(5-detector)
首先使用Stochastic Gradient Descent (SGD) classifier ,处理大量数据时很快,因为SGD可以把训练数据当作独立的个体,每次只处理一个数据。

识别5正确
03
模型评估
Cross-validation

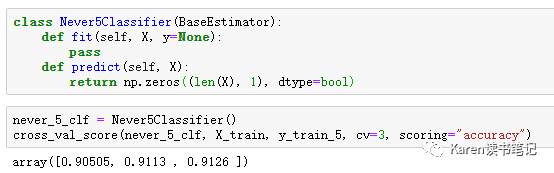
看起来准确度很高,但如果用来预测不是5的数字准确度有90%,因为不是5的数字占了整个数据集的90%,所以若一直猜测图片不是5也有90%的正确率。所以accuracy不合适用来评估分类器
混淆矩阵Confusion Matrix
需要用模型做预测,用预测结果和实际值计算confusion matrix
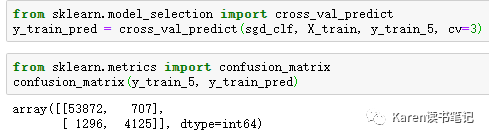
最完美的分类器希望只有TP(真正)和TN(真负),表现在Confusion Matrix上则是左对角线为数字,右对角线都为0

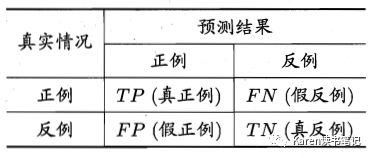
准确率(accuracy)
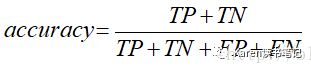
精准率(precision)查准
保持准确率,比如给用户推送邮件,不希望推送用户不感兴趣(FP)的邮件
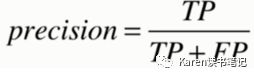
召回率(recall)查全
更敏感,比如癌症筛选,不希望漏查有癌症的(FN)患者

f1_score(平衡precision 和recall)
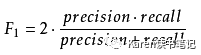
Precision/Recall Tradeoff
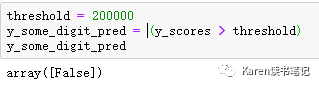
首先需要理解SGDClassifier是如何对每个实例分类的。SGDClassifier通过decision function算出score,如果score大于阈值则为正类,小于阈值则为负类。
下面几个图片从最低分到最高分排列,选择不一样的阈值,有不一样的recall和precision。降低阈值,增加recall减小precision;提高阈值,减小recall增加precision。
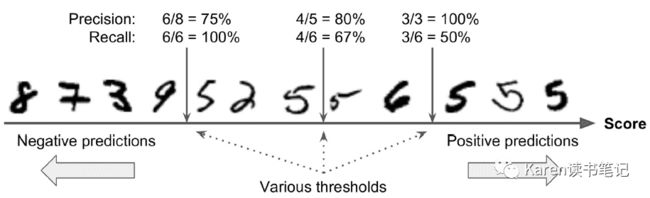

可以看到提高阈值,降低了recall(敏感度)。
选择最合适的阈值
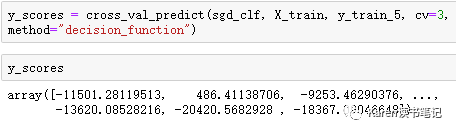
用cross_val_predict(),声明method =‘decision_function’,返回每个实例的score.
根据y score可以计算每一个score作为阈值的recall和precision。再画图可以找到最佳precision/recall tradeoff点(根据应用情况选择)
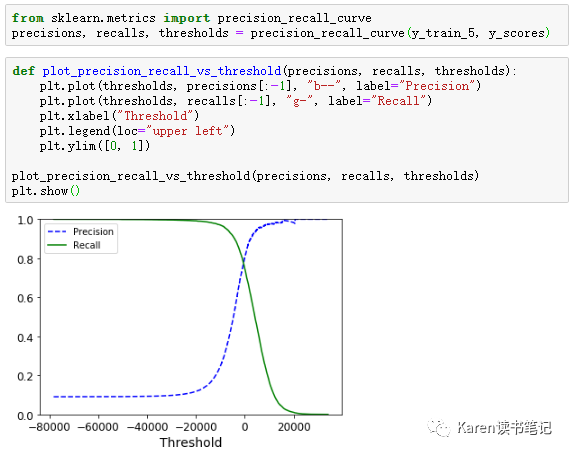
例如想要0.9 precision的分类器,可以根据上图找到对应的阈值为2700左右
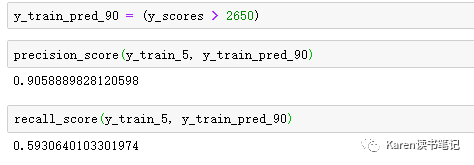
Precision Recall(PR) curve
也可以直接把recall作为横坐标,precision作为纵坐标。根据实际应用需求选择。比如recall在0.8左右开始下降非常快,那么我们希望选择precision/recall tradeoff在recall 0.8之前。PR curve越靠右越好。
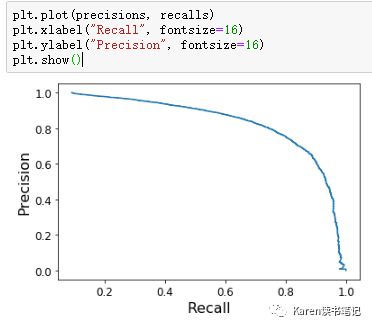
ROC(Receiver operating characteristic) curve
FPR(假正率)为横坐标,TPR(真正率)为纵坐标
虚线为完全随机的猜测,一般为正一半为负,ROC越靠近左上角分类器性能越好

AUC(Area Under the curve)
完美的分类器ROC AUC等于1,完全随机猜测的分类器 ROC AUC等于0.5
ROC curve 和 PR curve的选择
正类较少时,相对于false negative更关注false positive,则选择PR curve;
负类较少时,相对于false positive更关注false negative,则选择ROC curve。
例如在5-detector 分类器ROC AUC的值非常高,因为正类很少(10%的数据为5),如果用PR curve的话可以看到还有调整提升的空间。
RandomForestClassifier
RandomForestClassifier 没有decision function,不能返回score,但可以返回属于某类的概率,然后把属于正类的概率作为score

可以看到RandomForestClassifier 效果更好,比SGD更靠近左上角。

04
多类别分类器
OVA( one-versus-all)
识别数字0到9,每一个二分类器识别一个数字,每个分类器返回一个score,选择score最高的为实例的类。需要训练10个二分类器(1-detector、2-detector…)
OVO(one-versus-one)
识别数字0到9,每一个二分类器识别两个数字,每个分类器返回一个score,选择score最高的为实例的类。二分类器的个数为 N*(N-1)/2,MINIST数据集则需要训练45个二分类器
OVO优点是每一个分类器只需要训练属于那两个类的实例,而不是所有的数据。训练数据太多,SVM算法归一化很差且运算速度很慢。但对于大多数算法而言更倾向于使用OVA。
如果使用二分类算法用来识别多分类数据,sklearn可以自动识别,并运行OVA
SGDClassifier-OVA

查看每个类别的score
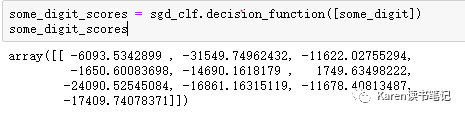
Score最高的类为5,所以预测为5

SGDClassifier-OVO
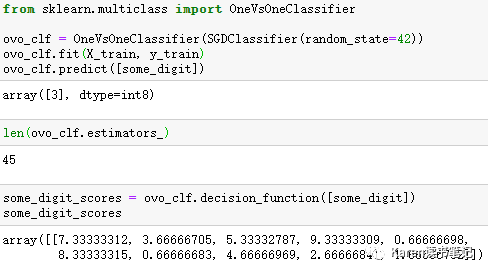
预测为3,分类错误,可以看到3的类score为9.3,5的类score为8.3,非常接近。
RandomForestClassifier
RandomForest没有ovo或者ova,因为RandomForest分类器直接计算实例属于某个类的概率。
RandomForest认为有86%的可能数字为5的类

用corss_val_score多次验证

准确度不错,简单的使用StandardScaler()能提升到90%

05
误差分析
分析confusion matrix
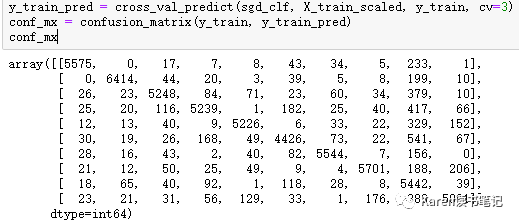
用图像看更直观
横轴代表预测值,纵轴代表真实值。
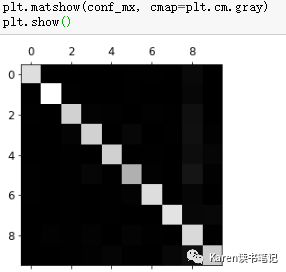
看起来不错,大多数图像在对角线上,即大多分类正确。5相较其他数字比较灰一点,说明分类器在识别5的时候没有其他数字识别的表现好。那么我们的重点可以放在识别5的分类器上。分析这个分类器为什么表现得较差。首先把confusion matrix上的每一个数值除以数值本身对应的类的个数,得到误差率

可以看到8和9都比较亮,误差率相较其他数字大,说明8和9经常和其他数字混淆;相反的0和1都很黑,误差率很低,说明0和1不容易和其他数字混淆。手写的5识别成8的概率比手写的8识别成5的概率比更高。
通过这个图,分类器需要几个提升的地方有8-detector、9-detector、3和5混淆、8和5混淆。解决的方法可以是收集更多这些手写的数字(训练数据),创建新的特征(比如说8有两个闭环,6有1一个闭环),也可以预先处理数据(Pillow、OpenCV、scikit-image)让某些特征更突出。
分析3和5 混淆的图片
X_aa: 实际为3,预测为3
X_ab:实际为3,预测为5
X_ba:实际为5,预测为3
X_bb:实际为5,预测为5
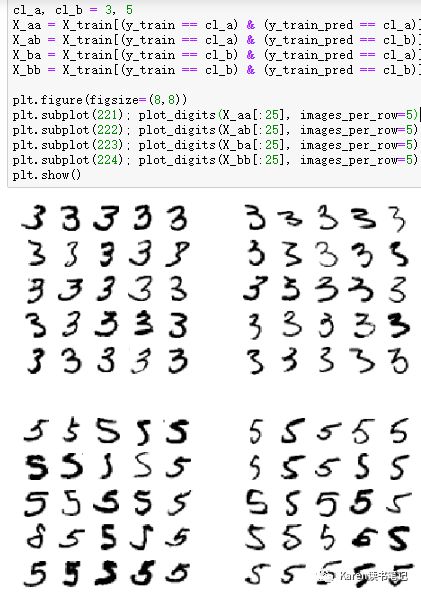
我们使用的模型是simple SGDClassifier,这是一个线性的模型,计算每个类别的权重并分配到每一个像素点,所以当有新的图片进来的时候,把新图片所分配权重后的像素点的值加在一起就得到score,依据score进行分类。所以由于3和5不一样的像素点不多,图像的上方有一点不一样,下方几乎一样,所以模型容易混淆。同时也说明了模型对于图像的偏移很敏感,所以解决3和5混淆的问题可以把图像预处理,比如把图像放在中心并无偏移。
Data Augmentation
把MINIST图像分别向上下左右移一个像素点,创建四份新的数据集,把这四份数据加入原始训练数据集中
定义移动图像的function
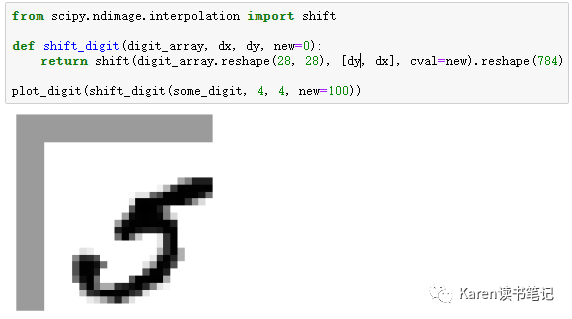
创建4份新的数据集

找KNeighborsClassifier模型最优参数


用KNeighborsClassifier训练预测并评估

06
多标签分类
分类器对一个实例分到多个类别
比如识别一张有多个人的图片,那么每个人都有一个标签
KNeighborsClassifier 支持多标签分类
每个数据标记了两个类别,一个判断是否大于等于7,一个判断是否为偶数,输出也为两个标记。

评估模型
在此模型中,是认为这两个label一样重要,但是实际应用中可能不一样。比如说在图片中某个人出现的频率较高,那么分类器对有那个人图像的权值则应该更高。通过设置参数average=’weighted’
07
多输出分类一个Label包含多个类别
分类器的输出是multilabel(每一个像素点都是一个label),每一个label是multioutput(每一个像素点的取值从0到255)
给每一个原始的图片的每一个像素点加上一个0到100的随机

左图为转换后有噪音的图像,右边为原始图片,我们训练的目标是把有噪音的图片去掉噪音

训练去掉噪音的图

Reference:《Hands-On Machine Learning with Scikit-Learn&TensorFlow》
代码:https://github.com/ageron/handson-ml/blob/master/03_classification.ipynb