python倾向匹配得分_手把手教你做倾向评分匹配 -PSM
原标题:手把手教你做倾向评分匹配 -PSM
本文首发于“百味科研芝士”微信公众号,转载请注明:百味科研芝士,Focus科研人的百味需求。
各位科研芝士的朋友大家好,今天和大家分享一下新的知识点—PSM,或许大家早已听过这个名词了,或许你对它还是半知半解,不过没关系,希望可以通过今天的帖子帮助你对该名词有一定的理解。
PSM
PSM英文全称为Propensity Score Matching,意思是倾向匹配得分,炸一听?多么有学术气息呀

那么如何通俗的理解PSM模型呢?
举个例子,假设一列病人样本,一组服用了药物A,我们想要知道,如果病人服用了药物A,那么他生活质量是否提高了?他的生存时间是否提高了?
但我们首先面临一个问题,究竟是因为药物A的影响,所以生活质量和生存时间均提高了,还是由于患者本身所产生的差异。
此时可以通过寻找另一列病人样本,服用的则是安慰剂对照。也就是说当我们想研究药物A是否对生活质量和生存时间产生影响时,首先需要找两列在其他各方向均差不多的病人,如果此时二者在生活质量和生存时间上依然产生了差别,那么可以认为这种差异是由是否服用药物A这个因素造成的。这样的方法有一个专业的名词,即PSM。
官方的话语则是:为了探讨某因素(暴露或干预,下面统称处理因素)与结局的关系,需要设立对照组进行比较,其目地是控制非处理因素的干扰,突显处理因素的的效应。
但是在观察性研究中(如队列研究),研究对象是非随机分配的,这就会使混杂因素在两组中分配不均匀,导致处理因素和结局的关系受到混杂因素的干扰。
近几年在国外研究中用的比较广泛的控制混杂因素的方法—倾向性评分匹配(propensity score matching, PSM)。
之前我们平台推出了基于SPSS计算PSM,那我们今天采用R语言计算PSM,测试数据在后台回复PSM提供。
今天PSM推荐的包为MatchIt,一听名字就是做匹配用的。
下面进入正题,今天我们看看如何用MatchIt,进行PSM分析:
1. 安装并加载包,关于包的安装,已经讲过多次,直接上代码:
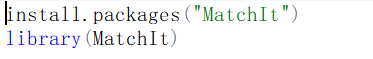
2.数据读取:

数据如下:该数据包括四列信息,分别是年龄,性别,样本类型和病人的ID
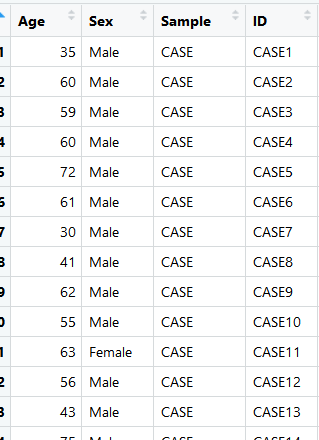
接着我们查看样本组成

我们发现该数据集中case样本包括250个,control样本包括1000个,接着我们需要对这两类样本进行匹配,匹配的协变量主要是性别因素和年龄因素。
3. 数据匹配,采用matchit函数,首先要定义一个逻辑变量,这一点非常重要:
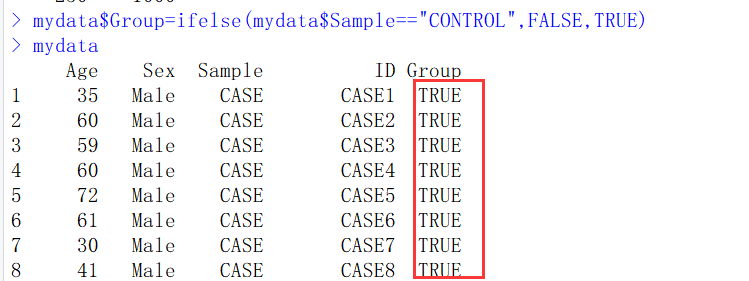
生存好逻辑变量之后,接着我们需要进行匹配
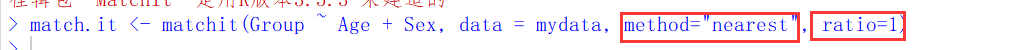
Matchit函数的第一个对象为一个表达式,因为进行了逻辑变量分组,接着把需要考虑的协变量放进去,这里主要是性别和年龄,method部分是我们要采取哪种方法进行匹配,一般默认为nearest,表示采取最近邻匹配法,该方法是PSM中最常见也最基本的方法,该方法是将处理组和对照组倾向性评分中最接近的个体进行匹配,当处理组个体全部匹配后,匹配结束,ratio代表匹配比例,当ratio=1,代表进行1:1匹配。
匹配结果展示:
![]()
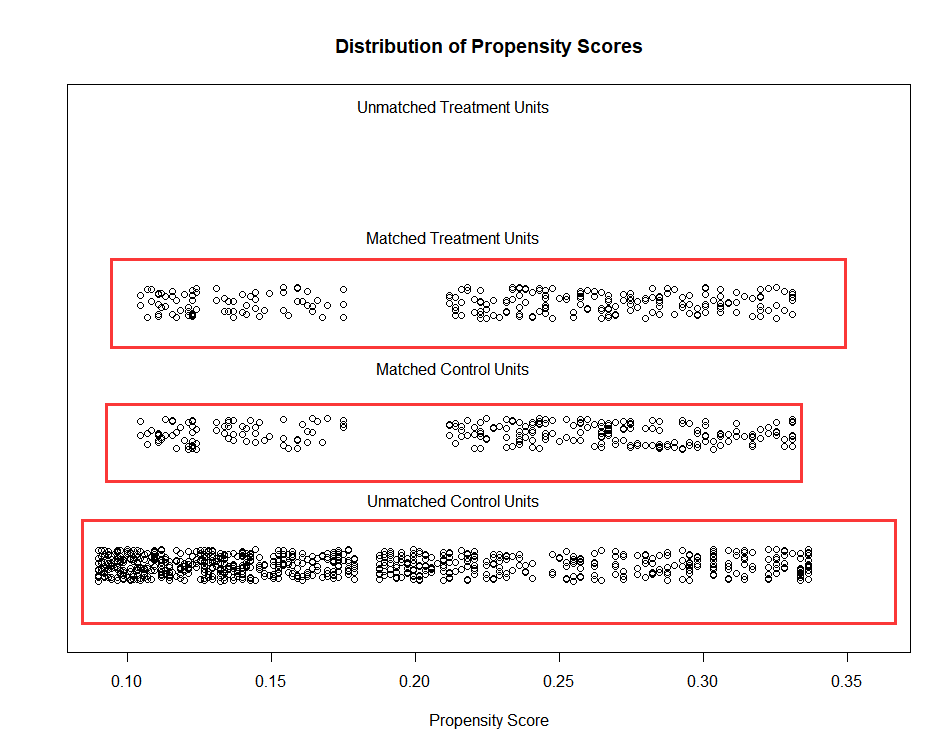
因为我们是250和1000进行匹配,可以看到在control 里面还有750个未匹配到。
5. 配对样本整理

我们按照组别排序,对配对样本整理,便看到左边三列是control组,右边三列是case组,
比如control4和case1进行了配对,则完成了样本之间的配对。
Ok,今天的推文就到这,我们分享了如何在基于R语言的PSM的计算,希望能对大家有所帮助,最后,欢迎大家多多交流。返回搜狐,查看更多
责任编辑: