机器学习笔记——朴素贝叶斯
朴素贝叶斯
主要思想
主要用于分类,是基于贝叶斯估计和特征向量独立性假设的生成模型
朴素贝叶斯模型根据训练集,首先学习先验概率分布 P ( Y = c k ) , k = 1 , 2 , . . . , K P(Y=c_k),k=1,2,...,K P(Y=ck),k=1,2,...,K,然后学习到条件概率分布 P ( X = x ∣ Y = c k ) = P ( X ( 1 ) = x ( 1 ) , . . . , X ( n ) = x ( n ) ∣ Y = c k ) , k = 1 , 2 , . . . , K P(X=x|Y=c_k)=P(X^{(1)}=x^{(1)},...,X^{(n)}=x^{(n)}|Y=c_k),k=1,2,...,K P(X=x∣Y=ck)=P(X(1)=x(1),...,X(n)=x(n)∣Y=ck),k=1,2,...,K,于是可以学习到联合概率分布 P ( X , Y ) P(X,Y) P(X,Y)
由于朴素贝叶斯对条件概率做了条件独立性的假设,即:
P ( X = x ∣ Y = c k ) = P ( X ( 1 ) = x ( 1 ) , . . . , X ( n ) = x ( n ) ∣ Y = c k ) = ∏ j = 1 n P ( X ( j ) = x ( j ) ∣ Y = c k ) (1) P(X=x|Y=c_k)=P(X^{(1)}=x^{(1)},...,X^{(n)}=x^{(n)}|Y=c_k)=\displaystyle\prod_{j=1}^nP(X^{(j)}=x^{(j)}|Y=c_k)\tag{1} P(X=x∣Y=ck)=P(X(1)=x(1),...,X(n)=x(n)∣Y=ck)=j=1∏nP(X(j)=x(j)∣Y=ck)(1)
朴素贝叶斯分类时,将输入变量后的最大后验概率的类作为输出。这里看不懂没关系,后面会有解释,公式为:
P ( Y = c k ∣ X = x ) = P ( X = x ∣ Y = c k ) P ( Y = c k ) ∑ k P ( X = x ∣ Y = c k ) P ( Y = c k ) (2) P(Y=c_k|X=x)=\cfrac{P(X=x|Y=c_k)P(Y=c_k)}{\displaystyle\sum_{k}P(X=x|Y=c_k)P(Y=c_k)}\tag{2} P(Y=ck∣X=x)=k∑P(X=x∣Y=ck)P(Y=ck)P(X=x∣Y=ck)P(Y=ck)(2)
将公式(1)带入公式(2)中,得到:
P ( Y = c k ∣ X = x ) = P ( X = x ∣ Y = c k ) P ( Y = c k ) ∑ k P ( Y = c k ) ∏ j P ( X ( j ) = x ( j ) ∣ Y = c k ) k = 1 , 2 , . . . , K (3) P(Y=c_k|X=x)=\cfrac{P(X=x|Y=c_k)P(Y=c_k)}{\displaystyle\sum_{k}P(Y=c_k)\displaystyle\prod_{j}P(X^{(j)}=x^{(j)}|Y=c_k)}k=1,2,...,K\tag{3} P(Y=ck∣X=x)=k∑P(Y=ck)j∏P(X(j)=x(j)∣Y=ck)P(X=x∣Y=ck)P(Y=ck)k=1,2,...,K(3)
公式(3)就是朴素贝叶斯的基本公式,那么朴素贝叶斯的分类器可表示为:
y = f ( x ) = arg max c k P ( X = x ∣ Y = c k ) P ( Y = c k ) ∑ k P ( Y = c k ) ∏ j P ( X ( j ) = x ( j ) ∣ Y = c k ) k = 1 , 2 , . . . , K (3) y=f(x)=\argmax_{c_k}\cfrac{P(X=x|Y=c_k)P(Y=c_k)}{\displaystyle\sum_{k}P(Y=c_k)\displaystyle\prod_{j}P(X^{(j)}=x^{(j)}|Y=c_k)}k=1,2,...,K\tag{3} y=f(x)=ckargmaxk∑P(Y=ck)j∏P(X(j)=x(j)∣Y=ck)P(X=x∣Y=ck)P(Y=ck)k=1,2,...,K(3)
这里根据最大后验概率(后面讲)进行变换就为:
y = arg max c k P ( Y = c k ) ∏ ( j = 1 ) n P ( X ( j ) = x ( j ) ∣ Y = c k ) (4) y=\argmax_{c_k}P(Y=c_k)\displaystyle\prod_{(j=1)}^nP(X^{(j)}=x{(j)}|Y=c_k)\tag{4} y=ckargmaxP(Y=ck)(j=1)∏nP(X(j)=x(j)∣Y=ck)(4)
在这里,对公式(2)做一下解释,公式(2)主要来源于贝叶斯公式,那么我们就从贝叶斯估计开始介绍,在统计学中,一直存有两个学派:频率派和贝叶斯派。这里的贝叶斯定理就属于贝叶斯派里的经典。
首先,我们先了解下,什么是先验概率、后验概率,我们知道 P ( A ∣ B ) P(A|B) P(A∣B)表示的是在B发生的情况下A的可能性:
首先,在事件B发生之前,我们对事件A有一个基本的判断,这就称为A的先验概率(边缘概率),记作 P ( A ) P(A) P(A)
其次,事件B发生之后,我们对事件A的发生概率要重新评估,称为A的后验概率(条件概率),记作 P ( A ∣ B ) P(A|B) P(A∣B)
我们现在了解了贝叶斯里的基本概念,再来看看贝叶斯定理的公式:
P ( B i ∣ A ) = P ( B i ) P ( A ∣ B i ) ∑ j = 1 n P ( B i ) P ( A ∣ B j ) P(B_i|A)=\cfrac{P(B_i)P(A|B_i)}{\displaystyle\sum_{j=1}^nP(B_i)P(A|B_j)} P(Bi∣A)=j=1∑nP(Bi)P(A∣Bj)P(Bi)P(A∣Bi)
那么这个定理是如何推导出来的呢?其实很简单,就是由基本的条件概率公式推导而来:
P ( A ∣ B ) = P ( A B ) P ( B ) P(A|B)=\cfrac{P(AB)}{P(B)} P(A∣B)=P(B)P(AB) 和 P ( B ∣ A ) = P ( A B ) P ( A ) P(B|A)=\cfrac{P(AB)}{P(A)} P(B∣A)=P(A)P(AB)
以上是两个条件概率公式,我们将 P ( A B ) P(AB) P(AB)替换掉,就得到这样的公式:
P ( B ∣ A ) = P ( B ) P ( A ∣ B ) P ( A ) P(B|A)=\cfrac{P(B)P(A|B)}{P(A)} P(B∣A)=P(A)P(B)P(A∣B)
我们知道全概率公式为
P ( A ) = P ( A ∣ B 1 ) + P ( A ∣ B 2 ) + . . . + P ( A ∣ B n ) P(A)=P(A|B_1)+P(A|B_2)+...+P(A|B_n) P(A)=P(A∣B1)+P(A∣B2)+...+P(A∣Bn)
因此,将全概率公式带入后就得到了贝叶斯定理啦!
上面的公式(4)的由来是根据最大化后验概率,那么最大化后验概率的思想是如何来的呢?
我们知道,如果想让一个模型的性能达到最好,需要使风险函数最小。这里我们使用的是期望风险函数,因为朴素贝叶斯模型可以求出联合概率分布,所以直接使用期望风险函数即可。
由于贝叶斯模型是解决分类问题,因此损失函数使用的是0-1损失函数:
L ( Y , f ( X ) ) = { 1 , Y ≠ f ( X ) 0 , Y = f ( X ) L(Y,f(X))=\begin{cases}1 ,\quad Y \neq f(X) \\0 ,\quad Y=f(X)\end{cases} L(Y,f(X))={1,Y=f(X)0,Y=f(X)
期望风险函数为:
R e x p ( f ) = E [ L ( Y , f ( X ) ) ] R_{exp}(f)=E[L(Y,f(X))] Rexp(f)=E[L(Y,f(X))]
这里的推导过程根据“深度之眼”统计学习方法的老师的思路进行推导的~具体的推导过程看图片:


根据图片,我们最终推导出了朴素贝叶斯模型的公式:
y = arg max c k P ( Y = c k ) ∏ ( j = 1 ) n P ( X ( j ) = x ( j ) ∣ Y = c k ) (4) y=\argmax_{c_k}P(Y=c_k)\displaystyle\prod_{(j=1)}^nP(X^{(j)}=x^{(j)}|Y=c_k)\tag{4} y=ckargmaxP(Y=ck)(j=1)∏nP(X(j)=x(j)∣Y=ck)(4)
算法过程
朴素贝叶斯的具体算法过程分为两种:极大似然估计和贝叶斯估计
首先,先来看算法的输入输出:
-
输入:训练数据集 T = ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x N , y N ) T={(x_1,y_1),(x_2,y_2),...,(x_N,y_N)} T=(x1,y1),(x2,y2),...,(xN,yN),其中 x i = ( x i ( 1 ) , x i ( 2 ) , . . . , x i ( j ) ) T x_i=(x_i^{(1)},x_i^{(2)},...,x_i^{(j)})^T xi=(xi(1),xi(2),...,xi(j))T, x i ( j ) x_i^{(j)} xi(j)是第 i i i个特征, x i ( j ) ∈ { a j 1 , a j 2 , . . , a j S j } x_i^{(j)} \in \{a_{j1},a_{j2},..,a_{jS_j}\} xi(j)∈{aj1,aj2,..,ajSj}, a j l a_{jl} ajl是第 j j j个特征可能取的第 l l l个值, j = 1 , 2 , . . . , n , l = 1 , 2 , . . , S j , y i ∈ { c 1 , c 2 , . . . , c K } j=1,2,...,n,l=1,2,..,S_j,y_i \in \{c_1,c_2,...,c_K\} j=1,2,...,n,l=1,2,..,Sj,yi∈{c1,c2,...,cK};实例 x x x
-
输出:实例 x x x的分类
我们先来看一下这个样本里的参数都是啥,我画了一个图,来帮助自己记住:
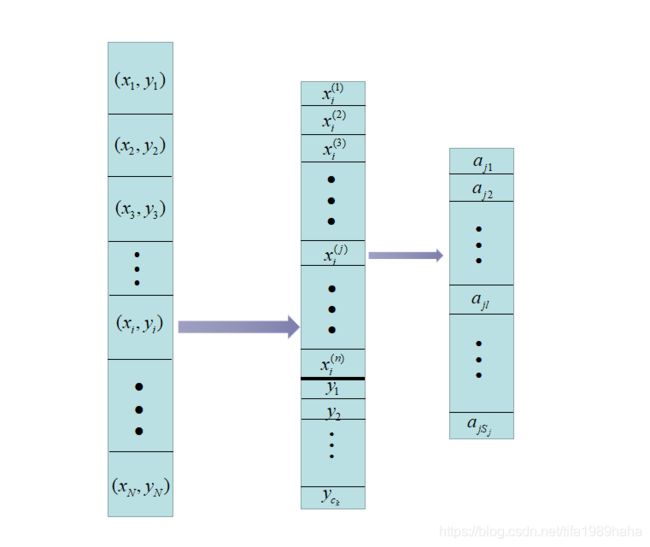
看完这个图,用文字来描述下,就是呢,训练集一共有 N N N个样本,每个样本都有一个 x x x和一个 y y y, y y y的取值共有 c k c_k ck个,每个样本中的 x x x又有 n n n个特征,每个特征又有 S j S_j Sj个取值。
接下来就是具体的概率估计方法啦!
- 极大似然估计方法
(1) 计算先验概率和条件概率
P ( Y = c k ) = ∑ i = 1 N I ( y i = c k ) N , k = 1 , 2 , . . . , K P(Y=c_k)=\cfrac{\displaystyle\sum_{i=1}^NI(y_i=c_k)}{N},\quad k=1,2,...,K P(Y=ck)=Ni=1∑NI(yi=ck),k=1,2,...,K
P ( X j = a j l ∣ Y = c k ) = ∑ i = 1 N I ( x i ( j ) = a j l , y i = c k ) ∑ i = 1 N I ( y i = c k ) j = 1 , 2 , . . . , n ; l = 1 , 2 , . . . , S j ; k = 1 , 2 , . . . , K P(X^{j}=a_{jl}|Y=c_k)=\cfrac{\displaystyle\sum_{i=1}^NI(x_i^{(j)}=a_{jl},y_i=c_k)}{\displaystyle\sum_{i=1}^NI(y_i=c_k)} \quad \quad j=1,2,...,n;\quad l=1,2,...,S_j;\quad k=1,2,...,K P(Xj=ajl∣Y=ck)=i=1∑NI(yi=ck)i=1∑NI(xi(j)=ajl,yi=ck)j=1,2,...,n;l=1,2,...,Sj;k=1,2,...,K
(2) 对于给定的实例 x = ( x ( 1 ) , x ( 2 ) , . . . , x ( n ) ) T x=(x^{(1)},x^{(2)},...,x^{(n)})^T x=(x(1),x(2),...,x(n))T,计算
P ( Y = c k ) ∏ j = 1 n P ( X ( j ) = x ( n ) ∣ Y = c k ) , k = 1 , 2 , . . . , K P(Y=c_k)\displaystyle\prod_{j=1}^nP(X^{(j)}=x^{(n)}|Y=c_k),\quad k=1,2,...,K P(Y=ck)j=1∏nP(X(j)=x(n)∣Y=ck),k=1,2,...,K
(3) 确定实例 x x x的类
y = arg max c k P ( Y = c k ) ∏ j = 1 n P ( X ( j ) = x ( j ) ∣ Y = c k ) y=\argmax_{c_k}P(Y=c_k)\displaystyle\prod_{j=1}^nP(X^{(j)}=x^{(j)}|Y=c_k) y=ckargmaxP(Y=ck)j=1∏nP(X(j)=x(j)∣Y=ck)
- 贝叶斯估计方法
由于极大似然估计会出现所要顾及的概率值为0的情况,这时候计算结果就会影响到后验概率,时分类产生偏差,采用贝叶斯估计可以解决这个问题。
我们只要在极大似然估计的基础上加个常数 λ \lambda λ,具体为:
(1) 先验概率为:
P λ ( Y = c k ) = ∑ i = 1 N I ( y i = c k ) + λ N + K λ P_\lambda(Y=c_k)=\cfrac{\displaystyle\sum_{i=1}^NI(y_i=c_k)+\lambda}{N+K\lambda} Pλ(Y=ck)=N+Kλi=1∑NI(yi=ck)+λ
(2) 条件概率为:
P λ ( X ( j ) = a j l ∣ Y = c k ) = ∑ i = 1 N I ( x i ( j ) = a j l , y i = c k ) + λ ∑ i = 1 N I ( y i = c k ) + S j λ P_\lambda(X^{(j)}=a_{jl}|Y=c_k)=\cfrac{\displaystyle\sum_{i=1}^NI(x_i^{(j)}=a_{jl},y_i=c_k)+\lambda}{\displaystyle\sum_{i=1}^NI(y_i=c_k)+S_j\lambda} Pλ(X(j)=ajl∣Y=ck)=i=1∑NI(yi=ck)+Sjλi=1∑NI(xi(j)=ajl,yi=ck)+λ
在以上公式中, λ ≥ 0 \lambda\geq0 λ≥0 。 λ = 1 \lambda=1 λ=1时,称为拉普拉斯平滑; λ = 0 \lambda=0 λ=0 时,此时就是极大似然估计。
总 结
-
朴素贝叶斯是通过求联合概率分布进而求得后验概率的,因此它是典型的生成模型。其中概率估计有两种方法:极大似然估计和贝叶斯估计。
-
“朴素”主要体现在此模型的一个假设:输入变量之间条件独立,由于这个假设,使得模型的学习和预测大为简化,也易于实现,但是分类的性能不一定很好。
-
朴素贝叶斯的损失函数是0-1损失函数,学习的核心思想是最大化后验概率。