NLP教程笔记:Transformer 将注意力发挥到极致
NLP教程
TF_IDF
词向量
句向量
Seq2Seq 语言生成模型
CNN的语言模型
语言模型的注意力
Transformer 将注意力发挥到极致
ELMo 一词多义
GPT 单向语言模型
BERT 双向语言模型
NLP模型的多种应用
目录
- NLP教程
- 语言多次注意力
- Transformer注意力模型
- 全都是注意
- 翻译
- 代码
- 结果讨论
- 全部代码
-
- 可视化
语言多次注意力

如果哪天有一位异性好友对你表白的回复是:“你人很好,很感谢有你的陪伴”。情场新手刚上车,第一眼看起来,好像是这个女生再夸我,激动得我眼泪要掉下来。带着这句话,让我一天都有好心情。可是当我吃完饭,再回想起她说我“人很好”,“感谢”我,这句话怎么听起来怪怪的。睡前我好像想明白了,她虽然说我好,但是这只是发好人卡的前奏,重点在后面,她在用“感谢陪伴”,委婉拒绝我!所以我使用了三次注意力,每次注意的时候都是基于上次注意后的理解。通过反复地回忆、琢磨才能研究透一句话背后的意思。
所以,如果深刻理解是通过注意力产生的,那么肯定也不只使用了一次注意力。这种思路正是目前AI技术发展的方向之一,利用注意力产生理解,而且使用的也是多次注意力的转换。
我们之前提到的模型,在通读语言后产生一个对句子全局的理解(句向量),然后再分别将 全局理解 和部分被注意的 局部理解 效应叠加,作为我后续任务的基础,比如基于全局和局部生成回复信息。但是这并不是我们刚刚提到的在注意力上再注意。所以聪明的科研人员创造了另一种方法,他们说,根本没有什么全局理解,我们用一次一次的注意力产生的局部理解就能解决这个问题。我们再来重复一遍上述发好人卡的过程,不过这一次,我们站在机器的角度,看它是怎么注意的。

模型第一次会通常会注意到一些局部的信息,在分散的地域分析有哪些有趣的词汇可以做出贡献,它觉得有趣的词可能是“好”, “感谢”, “陪伴”,如果单看这些注意到的东西,我可能以为女生在表扬我,我十分有戏。不过模型基于注意到的信息,再次注意。这次,模型开始觉得不对劲了,她说我好,还感谢我的陪伴,她到底想说啥? 经过第三次注意,模型意识到她可能只是想先扬后抑,这句话实际是一种转折,重点在后半句。所以模型也可以经过几次注意,不同层级的注意力带来的是不同层级上的理解。越是后面的注意,就是越深度的思考。如果熟悉自然语言模型的同学此刻应该也想到了,这就是 Transformer 模型。
Transformer注意力模型

如果把它可视化出来,Transformer 模型就长这样,它使用的是一个个注意力矩阵来表示在不同位置的注意力强度。通过控制强度来控制信息通道的阀门大小。即使这样,研究者还觉得不够。假如这种情况是一个人看多次,我们何不尝试让多个人一起看多次呢?这样会不会更有效率,变成三个臭皮匠赛过诸葛亮?

结果就有了这样的形态,多个人同时观察一句话,分别按自己的意见提出该注意哪里, 然后再汇总自己通过自己的注意力得到的结论,再进入下一轮注意力。 研究表明,这种注意力方案的确可以带给我们更深层的句意理解。
我们了解到注意力是一件好事,在之前RNN+Attention 架构中, 我们看到了当模型使用注意力关注被处理的输入信息时,模型的训练效果得到了很好的提升。既然注意力效果这么好,那RNN encode的信息还有那么重要吗? 我们能不能直接绕过RNN,来直接在词向量阶段就开始使用注意力?我制作的这个短片简介 很好的解释了这样一种新方式的好处。简而言之有这么两种方案:在理解一句话时
- 我们可以选择先读一遍,基于读过之后的理解上,再为后续处理分配不同的注意力.
- 我们不通读,而是跳着读关键词,直接用注意力方法找出并运用这些关键词。

研究发现,第二种方法在语言的理解上能够更上一筹,而且在同等量级的网络规模上,要比第一种方法快很多。 而且基于第二种方法再拓展一点。我理解句子的时候可以不仅仅只过目一遍,我还可以像多层RNN一样,在理解的基础上再次理解。 只是这次,不会像RNN那样,每次都对通句加深理解,而是一遍又一遍地注意到句子的不同部分,提炼对句子更深层的理解。
全都是注意
Transformer这个模型的论文题很网红,叫作Attention Is All You Need,你说这些作者都能找到这么短小精炼的话题,不去做网红真的可惜了。 不过说回来,如果一个模型里面如果全都是注意力,那么怎么设计比较好呢?

这是论文里面的图,如果是深度学习玩家,看到这种模型感觉起来好像也没有很复杂。但是注意到,这个图只画了一层attention,还有一个Nx,它可是要扩展成N个这种结构呀。 一般来说N的取值从个位数到十位数不等,大于20的话,一般的电脑恐怕就吃不消了,GPU的内存都不够用的。
Transformer 这种模型是一种 seq2seq 模型,是为了解决生成语言的问题。它也有一个 Encoder-Decoder 结构,只是它不像RNN中的 Encoder-Decoder。 之后我们将要介绍的 BERT 就是这个 Transformer 的Encoder部分,GPT就是它的 Decoder 部分,目前我们可以这样理解,后续我们会介绍他们之间的差别点。

主要目的都一样,为了完成语言的理解和任务的输出,使用Encoder对语言信息进行压缩和提炼,然后用Decoder产生相对的内容。 详细说明的话,Encoder 负责仔细阅读,一遍一遍地阅读,每一遍阅读都是重新使用注意力关注到上次的理解,对上次的理解进行再一次转义。 Decoder 任务同Seq2Seq 的 decoder 任务一样,同时接收Encoder的理解和之前预测的结果信息,生成下一步的预测结果.
总算到了最最最重要的地方了,这也是 Transformer 的核心点,它的 attention 是怎么做的呢?

上面是论文中的原图,它关注的有三种东西,Query, Key, Value。有的同学可能在别的论文中发现过这种结构, 我最开始看论文的时候总是弄不清这三个东西的关系。所以我给你画个图,你可能好理解一点。 其实做这件事的核心目的是快速准确地找到核心内容,换句话说:用我的搜索(Query)找到关键内容(Key),在关键内容上花时间花功夫(Value)。

想象这是一个相亲画面,我有我心中有个喜欢女孩的样子,我会按照这个心目中的形象浏览各女孩的照片,如果一个女生样貌很像我心中的样子,我就注意这个人, 并安排一段稍微长一点的时间阅读她的详细材料,反之我就安排少一点时间看她的材料。这样我就能将注意力放在我认为满足条件的候选人身上了。 我心中女神的样子就是Query,我拿着它(Query)去和所有的候选人(Key)做对比,得到一个要注意的程度(attention), 根据这个程度判断我要花多久时间仔细阅读候选人的材料(Value)。 这就是Transformer的注意力方式。
为了增强注意力的能力,Transformer还做了一件事:从 “注意力” 修改成了 “注意力注意力注意力注意力” 。哈哈哈,这叫做多头注意力(Multi-Head Attention)。 论文中的原图长这样。


其实多头注意力指的就是在同一层做注意力计算的时候,我多搞几次注意力。有点像我同时找了多个人帮我注意一下,这几个人帮我一轮一轮注意+理解之后, 我再汇总所有人的理解,统一判断。有点三个臭皮匠赛过诸葛亮的意思。
最后一个我想提到的重点是Decoder怎么样拿到Encoder对句子的理解的?或者Encoder是怎么样引起Decoder的注意的? 在理解这个问题之前,我们需要知道Encoder和Decoder都存在注意力,Encoder里的的注意力叫做自注意力(self-attention), 因为Encoder在这个时候只是自己和自己玩,自己捣鼓一句话的意思。而Decoder说:你把你捣鼓到的意思借我参考一下吧。 这时Self-attention在transformer中的意义才被凸显出来。

在Decoding时,decoder会向encoder借一下Key和Value,Decoder自己可以提供Query(已经预测出来的token)。使用我们刚刚提到的K,Q,V结合方式计算。 不过这张图里面还有些细节没有提到,比如 Decoder 先要经过Masked attention再和encoder的K,V结合,然后还有一个feed forward计算,还要计算残差。
- Masked attention: 不让decoder在训练的时候用后文的信息生成前文的信息;
- Feed forward: 这个encoder,decoder都有,做一下非线性处理;
- 残差计算:这个也是encoder和decoder都有,为了更有效的backpropagation。
翻译
在这节内容中,我还是以翻译为例。延续前几次用到日期翻译的例子, 我们知道在翻译的模型中,实际上是要构建一个Encoder,一个Decoder。这节内容我们就是让Decoder在生成语言的时候,也注意到Encoder的对应部分。
# 中文的 "年-月-日" -> "day/month/year"
"98-02-26" -> "26/Feb/1998"
对比前几期内容,Transformer的翻译任务收敛得也是很快的。
step: 0 | time: 0.55 | loss: 3.7659 | target: 17/Jun/1996 | inference: SepOctOct<EOS>Sep5<EOS>5AprJul
step: 50 | time: 7.62 | loss: 1.1756 | target: 19/May/1996 | inference: 19/1/1999<EOS>
step: 100 | time: 8.46 | loss: 0.7199 | target: 09/Mar/1995 | inference: 19/Jan/1999<EOS>
step: 150 | time: 7.54 | loss: 0.3360 | target: 17/Jul/1996 | inference: 17/Jan/1996<EOS>
step: 200 | time: 7.58 | loss: 0.0793 | target: 24/Sep/2022 | inference: 24/Sep/2022<EOS>
...
step: 500 | time: 7.80 | loss: 0.0053 | target: 31/Mar/2024 | inference: 31/Mar/2024<EOS>
step: 550 | time: 8.88 | loss: 0.0026 | target: 22/Jan/1997 | inference: 22/Jan/1997<EOS>
代码
class MultiHead:
...
def scaled_dot_product_attention(self, q, k, v, mask=None):
...
def call(self, q, k, v, mask):
# 处理一下 q k v
o = self.scaled_dot_product_attention(q, k, v, mask)
return o
class PositionWiseFFN:
# 主要为了重新定义一下结果的 shape,方便传入下一层 layer
上面两个功能是Encoder和Decoder都会用到的功能,所以我们统一写一下。下面是encoder和decoder layer怎么组装这些功能。
class EncodeLayer:
def __init__(self):
self.mh = MultiHead()
self.ffn = PositionWiseFFN()
def call(self, xz):
attn = self.mh.call(xz, xz, xz, ...) # multi head attention
o1 = attn + xz # 残差
ffn = self.ffn.call(o1) # 非线性
o = ffn + o1 # 残差
return o
class DecoderLayer:
def __init__(self):
self.mh1 = MultiHead()
self.mh2 = MultiHead()
self.ffn = PositionWiseFFN()
def call(self, yz, xz):
attn = self.mh1.call(yz, yz, yz, ...) # decoder 的 multi head attention
o1 = attn + yz # 残差
attn = self.mh2.call(o1, xz, xz, ...) # encoder + decoder 的混合 multi head attention
o2 = attn + o1 # 残差
ffn = self.ffn.call(o2) # 非线性
o = ffn + o2 # 残差
return o
上面这些步骤是用来组成Encoder和Decoder的每一层layer的。 里面包含了multi-head attention的计算、残差计算、encoder+decoder混合attention、非线性处理等计算。 接下来我们将要把layer加到 encoder和decoder当中去。
class Encoder:
def __init__(self):
self.ls = [EncodeLayer() for _ in range(n)]
def call(self, xz):
for l in self.ls:
xz = l.call(xz)
return xz
class Decoder:
def __init__(self):
self.ls = [DecodeLayer() for _ in range(n)]
def call(self, yz, xz):
for l in self.ls:
yz = l.call(yz, xz)
return yz
Encoder只管好自己就行,Decoder需要拿着Encoder给出来的xz,一起计算。最后我们把它们整进Transformer。
class Transformer:
def __init__(self):
self.embed = PositionEmbedding(max_len, model_dim, n_vocab)
self.encoder = Encoder(n_head, model_dim, drop_rate, n_layer)
self.decoder = Decoder(n_head, model_dim, drop_rate, n_layer)
self.o = keras.layers.Dense(n_vocab)
def call(self, x, y):
x_embed, y_embed = self.embed(x), self.embed(y)
encoded_z = self.encoder.call(x_embed, ...)
decoded_z = self.decoder.call(y_embed, encoded_z, ...)
o = self.o(decoded_z)
return o
这就是整个Transformer的框架啦。按照这个框架写一些训练代码,你的程序就能跑起来了。
结果讨论
最重要的,还是encoder和decoder配合的结果。我用矩阵和连线的方法分开给你展示。 可视化代码你也可以拿去随意使用。
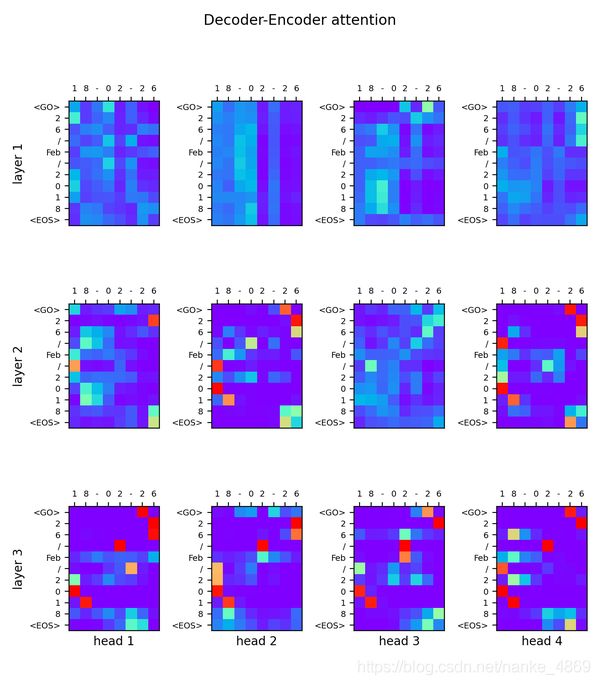
在论文里,应该经常看到上面这种图,我们看到最后一层layer3, 这个就是decoder在结合encoder信息后的attention,生成的预测结果。我们很明显可以看到中英文日期对应的点上, 注意力都非常大。
换一种角度来看,我们再用连线可以更加明显的看出来这样的关系。

下面我们再来看看decoder,encoder各自的self-attention.

Encoder 的 self-attention 看不出来太多信息,因为我们这个数据集在自注意上并不是很强调,X的语句内部没有多少相关的信息。所以训练出来的encoder self-attention 并不明显。

反而是decoder的self-attention还是有些信息的。因为decoder在做self-attention时, 实际上还是会多多少少接收到encoder attention的影响。因为encoder的attention信息被传输过来了。
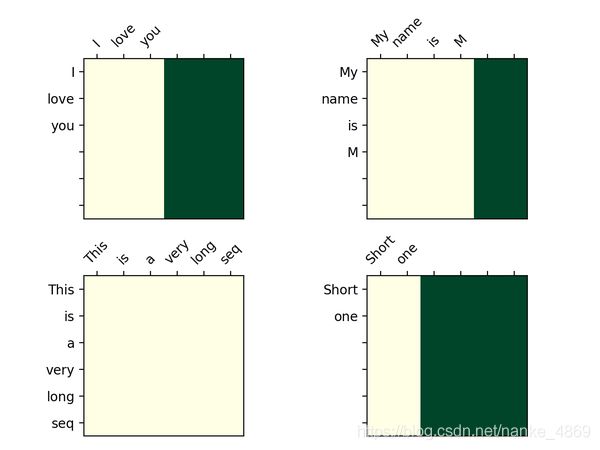
还有一个有意思的点,不知道你们发现没,decoder的attention图,为什么是一个三角形? 原因在我在上面提到的,预测时,不能让后文的信息影响到前文,就会用一个look_ahead_mask将后文的信息给遮盖住。这个mask长成这样:

那问题又来了,为什么这个mask不是一个对角的三角形呢?原因是有些句子没那么长,也可以一起mask掉,我把这种叫做 pad_mask,像下图这样。
最后,还有一个问题,transformer的attention不像RNN,它没有捕捉到文字序列上的时序信息。那我们怎么让模型知道一句话的顺序呢? 这个有多种做法,比如让模型仔细学一个position embedding,或者你给一个有规律的position embedding就好了。 下面展示的是可视化出来的Position Embedding:

全部代码
utils.py与之前的代码相同
import tensorflow as tf
from tensorflow import keras
import numpy as np
import utils
import time
import pickle
import os
MODEL_DIM = 32
MAX_LEN = 12
N_LAYER = 3
N_HEAD = 4
DROP_RATE = 0.1
class MultiHead(keras.layers.Layer):
def __init__(self, n_head, model_dim, drop_rate):
super().__init__()
self.head_dim = model_dim // n_head
self.n_head = n_head
self.model_dim = model_dim
self.wq = keras.layers.Dense(n_head * self.head_dim)
self.wk = keras.layers.Dense(n_head * self.head_dim)
self.wv = keras.layers.Dense(n_head * self.head_dim) # [n, step, h*h_dim]
self.o_dense = keras.layers.Dense(model_dim)
self.o_drop = keras.layers.Dropout(rate=drop_rate)
self.attention = None
def call(self, q, k, v, mask, training):
_q = self.wq(q) # [n, q_step, h*h_dim]
_k, _v = self.wk(k), self.wv(v) # [n, step, h*h_dim]
_q = self.split_heads(_q) # [n, h, q_step, h_dim]
_k, _v = self.split_heads(_k), self.split_heads(_v) # [n, h, step, h_dim]
context = self.scaled_dot_product_attention(_q, _k, _v, mask) # [n, q_step, h*dv]
o = self.o_dense(context) # [n, step, dim]
o = self.o_drop(o, training=training)
return o
def split_heads(self, x):
x = tf.reshape(x, (x.shape[0], x.shape[1], self.n_head, self.head_dim)) # [n, step, h, h_dim]
return tf.transpose(x, perm=[0, 2, 1, 3]) # [n, h, step, h_dim]
def scaled_dot_product_attention(self, q, k, v, mask=None):
dk = tf.cast(k.shape[-1], dtype=tf.float32)
score = tf.matmul(q, k, transpose_b=True) / (tf.math.sqrt(dk) + 1e-8) # [n, h_dim, q_step, step]
if mask is not None:
score += mask * -1e9
self.attention = tf.nn.softmax(score, axis=-1) # [n, h, q_step, step]
context = tf.matmul(self.attention, v) # [n, h, q_step, step] @ [n, h, step, dv] = [n, h, q_step, dv]
context = tf.transpose(context, perm=[0, 2, 1, 3]) # [n, q_step, h, dv]
context = tf.reshape(context, (context.shape[0], context.shape[1], -1)) # [n, q_step, h*dv]
return context
class PositionWiseFFN(keras.layers.Layer):
def __init__(self, model_dim):
super().__init__()
dff = model_dim * 4
self.l = keras.layers.Dense(dff, activation=keras.activations.relu)
self.o = keras.layers.Dense(model_dim)
def call(self, x):
o = self.l(x)
o = self.o(o)
return o # [n, step, dim]
class EncodeLayer(keras.layers.Layer):
def __init__(self, n_head, model_dim, drop_rate):
super().__init__()
self.ln = [keras.layers.LayerNormalization(axis=-1) for _ in range(2)] # only norm z-dim
self.mh = MultiHead(n_head, model_dim, drop_rate)
self.ffn = PositionWiseFFN(model_dim)
self.drop = keras.layers.Dropout(drop_rate)
def call(self, xz, training, mask):
attn = self.mh.call(xz, xz, xz, mask, training) # [n, step, dim]
o1 = self.ln[0](attn + xz)
ffn = self.drop(self.ffn.call(o1), training)
o = self.ln[1](ffn + o1) # [n, step, dim]
return o
class Encoder(keras.layers.Layer):
def __init__(self, n_head, model_dim, drop_rate, n_layer):
super().__init__()
self.ls = [EncodeLayer(n_head, model_dim, drop_rate) for _ in range(n_layer)]
def call(self, xz, training, mask):
for l in self.ls:
xz = l.call(xz, training, mask)
return xz # [n, step, dim]
class DecoderLayer(keras.layers.Layer):
def __init__(self, n_head, model_dim, drop_rate):
super().__init__()
self.ln = [keras.layers.LayerNormalization(axis=-1) for _ in range(3)] # only norm z-dim
self.drop = keras.layers.Dropout(drop_rate)
self.mh = [MultiHead(n_head, model_dim, drop_rate) for _ in range(2)]
self.ffn = PositionWiseFFN(model_dim)
def call(self, yz, xz, training, yz_look_ahead_mask, xz_pad_mask):
attn = self.mh[0].call(yz, yz, yz, yz_look_ahead_mask, training) # decoder self attention
o1 = self.ln[0](attn + yz)
attn = self.mh[1].call(o1, xz, xz, xz_pad_mask, training) # decoder + encoder attention
o2 = self.ln[1](attn + o1)
ffn = self.drop(self.ffn.call(o2), training)
o = self.ln[2](ffn + o2)
return o
class Decoder(keras.layers.Layer):
def __init__(self, n_head, model_dim, drop_rate, n_layer):
super().__init__()
self.ls = [DecoderLayer(n_head, model_dim, drop_rate) for _ in range(n_layer)]
def call(self, yz, xz, training, yz_look_ahead_mask, xz_pad_mask):
for l in self.ls:
yz = l.call(yz, xz, training, yz_look_ahead_mask, xz_pad_mask)
return yz
class PositionEmbedding(keras.layers.Layer):
def __init__(self, max_len, model_dim, n_vocab):
super().__init__()
pos = np.arange(max_len)[:, None]
pe = pos / np.power(10000, 2. * np.arange(model_dim)[None, :] / model_dim) # [max_len, dim]
pe[:, 0::2] = np.sin(pe[:, 0::2])
pe[:, 1::2] = np.cos(pe[:, 1::2])
pe = pe[None, :, :] # [1, max_len, model_dim] for batch adding
self.pe = tf.constant(pe, dtype=tf.float32)
self.embeddings = keras.layers.Embedding(
input_dim=n_vocab, output_dim=model_dim, # [n_vocab, dim]
embeddings_initializer=tf.initializers.RandomNormal(0., 0.01),
)
def call(self, x):
x_embed = self.embeddings(x) + self.pe # [n, step, dim]
return x_embed
class Transformer(keras.Model):
def __init__(self, model_dim, max_len, n_layer, n_head, n_vocab, drop_rate=0.1, padding_idx=0):
super().__init__()
self.max_len = max_len
self.padding_idx = padding_idx
self.embed = PositionEmbedding(max_len, model_dim, n_vocab)
self.encoder = Encoder(n_head, model_dim, drop_rate, n_layer)
self.decoder = Decoder(n_head, model_dim, drop_rate, n_layer)
self.o = keras.layers.Dense(n_vocab)
self.cross_entropy = keras.losses.SparseCategoricalCrossentropy(from_logits=True, reduction="none")
self.opt = keras.optimizers.Adam(0.002)
def call(self, x, y, training=None):
x_embed, y_embed = self.embed(x), self.embed(y)
pad_mask = self._pad_mask(x)
encoded_z = self.encoder.call(x_embed, training, mask=pad_mask)
decoded_z = self.decoder.call(
y_embed, encoded_z, training, yz_look_ahead_mask=self._look_ahead_mask(y), xz_pad_mask=pad_mask)
o = self.o(decoded_z)
return o
def step(self, x, y):
with tf.GradientTape() as tape:
logits = self.call(x, y[:, :-1], training=True)
pad_mask = tf.math.not_equal(y[:, 1:], self.padding_idx)
loss = tf.reduce_mean(tf.boolean_mask(self.cross_entropy(y[:, 1:], logits), pad_mask))
grads = tape.gradient(loss, self.trainable_variables)
self.opt.apply_gradients(zip(grads, self.trainable_variables))
return loss, logits
def _pad_bool(self, seqs):
return tf.math.equal(seqs, self.padding_idx)
def _pad_mask(self, seqs):
mask = tf.cast(self._pad_bool(seqs), tf.float32)
return mask[:, tf.newaxis, tf.newaxis, :] # (n, 1, 1, step)
def _look_ahead_mask(self, seqs):
mask = 1 - tf.linalg.band_part(tf.ones((self.max_len, self.max_len)), -1, 0)
mask = tf.where(self._pad_bool(seqs)[:, tf.newaxis, tf.newaxis, :], 1, mask[tf.newaxis, tf.newaxis, :, :])
return mask # (step, step)
def translate(self, src, v2i, i2v):
src_pad = utils.pad_zero(src, self.max_len)
tgt = utils.pad_zero(np.array([[v2i["" ], ] for _ in range(len(src))]), self.max_len+1)
tgti = 0
x_embed = self.embed(src_pad)
encoded_z = self.encoder.call(x_embed, False, mask=self._pad_mask(src_pad))
while True:
y = tgt[:, :-1]
y_embed = self.embed(y)
decoded_z = self.decoder.call(
y_embed, encoded_z, False, yz_look_ahead_mask=self._look_ahead_mask(y), xz_pad_mask=self._pad_mask(src_pad))
logits = self.o(decoded_z)[:, tgti, :].numpy()
idx = np.argmax(logits, axis=1)
tgti += 1
tgt[:, tgti] = idx
if tgti >= self.max_len:
break
return ["".join([i2v[i] for i in tgt[j, 1:tgti]]) for j in range(len(src))]
@property
def attentions(self):
attentions = {
"encoder": [l.mh.attention.numpy() for l in self.encoder.ls],
"decoder": {
"mh1": [l.mh[0].attention.numpy() for l in self.decoder.ls],
"mh2": [l.mh[1].attention.numpy() for l in self.decoder.ls],
}}
return attentions
def train(model, data, step):
# training
t0 = time.time()
for t in range(step):
bx, by, seq_len = data.sample(64)
bx, by = utils.pad_zero(bx, max_len=MAX_LEN), utils.pad_zero(by, max_len=MAX_LEN + 1)
loss, logits = model.step(bx, by)
if t % 50 == 0:
logits = logits[0].numpy()
t1 = time.time()
print(
"step: ", t,
"| time: %.2f" % (t1 - t0),
"| loss: %.4f" % loss.numpy(),
"| target: ", "".join([data.i2v[i] for i in by[0, 1:10]]),
"| inference: ", "".join([data.i2v[i] for i in np.argmax(logits, axis=1)[:10]]),
)
t0 = t1
os.makedirs("./visual/models/transformer", exist_ok=True)
model.save_weights("./visual/models/transformer/model.ckpt")
os.makedirs("./visual/tmp", exist_ok=True)
with open("./visual/tmp/transformer_v2i_i2v.pkl", "wb") as f:
pickle.dump({"v2i": data.v2i, "i2v": data.i2v}, f)
def export_attention(model, data, name="transformer"):
with open("./visual/tmp/transformer_v2i_i2v.pkl", "rb") as f:
dic = pickle.load(f)
model.load_weights("./visual/models/transformer/model.ckpt")
bx, by, seq_len = data.sample(32)
model.translate(bx, dic["v2i"], dic["i2v"])
attn_data = {
"src": [[data.i2v[i] for i in bx[j]] for j in range(len(bx))],
"tgt": [[data.i2v[i] for i in by[j]] for j in range(len(by))],
"attentions": model.attentions}
path = "./visual/tmp/%s_attention_matrix.pkl" % name
os.makedirs(os.path.dirname(path), exist_ok=True)
with open(path, "wb") as f:
pickle.dump(attn_data, f)
if __name__ == "__main__":
utils.set_soft_gpu(True)
d = utils.DateData(4000)
print("Chinese time order: yy/mm/dd ", d.date_cn[:3], "\nEnglish time order: dd/M/yyyy ", d.date_en[:3])
print("vocabularies: ", d.vocab)
print("x index sample: \n{}\n{}".format(d.idx2str(d.x[0]), d.x[0]),
"\ny index sample: \n{}\n{}".format(d.idx2str(d.y[0]), d.y[0]))
m = Transformer(MODEL_DIM, MAX_LEN, N_LAYER, N_HEAD, d.num_word, DROP_RATE)
train(m, d, step=800)
export_attention(m, d)
可视化
def transformer_attention_matrix(case=0):
with open("./visual/tmp/transformer_attention_matrix.pkl", "rb") as f:
data = pickle.load(f)
src = data["src"][case]
tgt = data["tgt"][case]
attentions = data["attentions"]
encoder_atten = attentions["encoder"]
decoder_tgt_atten = attentions["decoder"]["mh1"]
decoder_src_atten = attentions["decoder"]["mh2"]
plt.rcParams['xtick.bottom'] = plt.rcParams['xtick.labelbottom'] = False
plt.rcParams['xtick.top'] = plt.rcParams['xtick.labeltop'] = True
plt.figure(0, (7, 7))
plt.suptitle("Encoder self-attention")
for i in range(3):
for j in range(4):
plt.subplot(3, 4, i * 4 + j + 1)
plt.imshow(encoder_atten[i][case, j][:len(src), :len(src)], vmax=1, vmin=0, cmap="rainbow")
plt.xticks(range(len(src)), src)
plt.yticks(range(len(src)), src)
if j == 0:
plt.ylabel("layer %i" % (i+1))
if i == 2:
plt.xlabel("head %i" % (j+1))
plt.tight_layout()
plt.subplots_adjust(top=0.9)
plt.savefig("./visual/results/transformer%d_encoder_self_attention.png" % case, dpi=200)
plt.show()
plt.figure(1, (7, 7))
plt.suptitle("Decoder self-attention")
for i in range(3):
for j in range(4):
plt.subplot(3, 4, i * 4 + j + 1)
plt.imshow(decoder_tgt_atten[i][case, j][:len(tgt), :len(tgt)], vmax=1, vmin=0, cmap="rainbow")
plt.xticks(range(len(tgt)), tgt, rotation=90, fontsize=7)
plt.yticks(range(len(tgt)), tgt, fontsize=7)
if j == 0:
plt.ylabel("layer %i" % (i+1))
if i == 2:
plt.xlabel("head %i" % (j+1))
plt.tight_layout()
plt.subplots_adjust(top=0.9)
plt.savefig("./visual/results/transformer%d_decoder_self_attention.png" % case, dpi=200)
plt.show()
plt.figure(2, (7, 8))
plt.suptitle("Decoder-Encoder attention")
for i in range(3):
for j in range(4):
plt.subplot(3, 4, i*4+j+1)
plt.imshow(decoder_src_atten[i][case, j][:len(tgt), :len(src)], vmax=1, vmin=0, cmap="rainbow")
plt.xticks(range(len(src)), src, fontsize=7)
plt.yticks(range(len(tgt)), tgt, fontsize=7)
if j == 0:
plt.ylabel("layer %i" % (i+1))
if i == 2:
plt.xlabel("head %i" % (j+1))
plt.tight_layout()
plt.subplots_adjust(top=0.9)
plt.savefig("./visual/results/transformer%d_decoder_encoder_attention.png" % case, dpi=200)
plt.show()
def transformer_attention_line(case=0):
with open("./visual/tmp/transformer_attention_matrix.pkl", "rb") as f:
data = pickle.load(f)
src = data["src"][case]
tgt = data["tgt"][case]
attentions = data["attentions"]
decoder_src_atten = attentions["decoder"]["mh2"]
tgt_label = tgt[1:11][::-1]
src_label = ["" for _ in range(2)] + src[::-1]
fig, ax = plt.subplots(nrows=2, ncols=2, sharex=True, figsize=(7, 14))
for i in range(2):
for j in range(2):
ax[i, j].set_yticks(np.arange(len(src_label)))
ax[i, j].set_yticklabels(src_label, fontsize=9) # src
ax[i, j].set_ylim(0, len(src_label)-1)
ax_ = ax[i, j].twinx()
ax_.set_yticks(np.linspace(ax_.get_yticks()[0], ax_.get_yticks()[-1], len(ax[i, j].get_yticks())))
ax_.set_yticklabels(tgt_label, fontsize=9) # tgt
img = decoder_src_atten[-1][case, i + j][:10, :8]
color = cm.rainbow(np.linspace(0, 1, img.shape[0]))
left_top, right_top = img.shape[1], img.shape[0]
for ri, c in zip(range(right_top), color): # tgt
for li in range(left_top): # src
alpha = (img[ri, li] / img[ri].max()) ** 8
ax[i, j].plot([0, 1], [left_top - li + 1, right_top - 1 - ri], alpha=alpha, c=c)
ax[i, j].set_xticks(())
ax[i, j].set_xlabel("head %i" % (j + 1 + i * 2))
ax[i, j].set_xlim(0, 1)
plt.subplots_adjust(top=0.9)
plt.tight_layout()
plt.savefig("./visual/results/transformer%d_encoder_decoder_attention_line.png" % case, dpi=100)
def position_embedding():
max_len = 500
model_dim = 512
pos = np.arange(max_len)[:, None]
pe = pos / np.power(10000, 2. * np.arange(model_dim)[None, :] / model_dim) # [max_len, model_dim]
pe[:, 0::2] = np.sin(pe[:, 0::2])
pe[:, 1::2] = np.cos(pe[:, 1::2])
plt.imshow(pe, vmax=1, vmin=-1, cmap="rainbow")
plt.ylabel("word position")
plt.xlabel("embedding dim")
plt.savefig("./visual/results/transformer_position_embedding.png", dpi=200)
plt.show()