dataframe 字符串切割
问题:
现在手中有一表格,其中一列数据长成下列格式:三个元素挤在一个单元格中,现在需要把这三个元素进行分隔开,生成新的三列,该如何办?

前面介绍了str.split()方法和re.split()方法,利用这两个方法任意一种方法,结合其他的方法,也可以完成工作,但是比较麻烦,具体的实现方式见文末。
这里我们利用pandas的Series.str.split()方法可以很方便的实现。前面文章介绍了Python的内置方法str.split()和 re库中的re.split()方法,现在来介绍一下pandas.Series.str.split(),通过该方法来实现类似于Excel中的分列动作。
在pandas.Series.str.split()方法其实调用了python的内置方法str.split()和re.spilt():
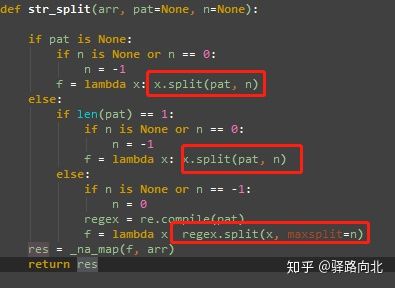
从源代码中我们可以看到,pandas的str.split()方法确实调用了Python内置方法str.split()与re.split()方法,如果掌握了前两种方法,那pandas的split()方法也就不在话下了。
pandas.Series.str.split(pat=None, n=-1, expand=False)的参数如下:
- pat:string 或者 正则表达式,若为空,则为连续的空格,包括(换行符、空格、制表符)
- n:默认值为-1,若为None, 0 都会被修改成-1(从上图中的源码也能看出来),即能分割多少次就分割多少次,与str.split()的n=-1,re.split()的maxsplit=0一致;
- expand:决定了分割后的结果是分布在多列(返回DataFrame)还是以列表的形式分布在一列中(返回Series)
参数比较简单,现在我们利用Series.stri.split()方法将下表格中的学生信息进行分割
import pandas as pd
df = pd.Series(['张三 一班 00001', '李四 二班 00002', '王五 三班 00003'])
# 若expand为False,返回Series,只不过将结果以列表的形式存储
result = df.str.split(pat=None, n=-1, expand=False)
print(result)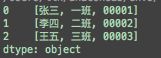
要想完成分列动作,需要设置expand(展开的意思)的值为True
df = pd.Series(['张三 一班 00001', '李四 二班 00002', '王五 三班 00003'])
# 若expand为True,返回DataFrame,将分列后的结果存储在不同的列中(完成分列动作)
result = df.str.split(pat=None, n=-1, expand=True).\
rename(columns={0:'姓名', 1:'班级', 2:'学号'})
print(result)
小结:
到目前为止,关于字符串的分割介绍了三个方法,有Python的内置方法str.split(),正则表达式re库的re.split()和pandas.Series.str.split()方法。
- 若分隔符比较简单,如为 空格、换行符、某些特定的字符等等,可以直接用str.split();
- 若分隔符比较复杂,如有多个不同的分隔符,可以利用re.split()方法会比较简单;
- 若对表格中的字符串进行处理的话,这时可以优先考虑pandas.Series.str.split()。
现在我们使用内置方法sr.split()来实现分列的动作:
df = pd.Series(['张三 一班 00001', '李四 二班 00002', '王五 三班 00003'])
result = pd.DataFrame(list(df.map(lambda x: x.split()), columns=['姓名', '班级','学号'])
print(result)
利用Python内置方法亦可以实现分列动作,但是涉及到的方法有list, map, lambda, DataFrame等等,比较麻烦,如果掌握了Series.str.split() 就可以很方便的实现了