经典目标检测论文分享---Faster R-CNN
经典目标检测论文分享---Faster R-CNN
- 一 Preface
-
- 1.2 What is RPN (brief)?
- 1.3 Faster R-CNN缘由及优点
- 1.4主要创新点
- 1.5 对比图
- 二 Faster R-CNN architecture
- 三 Details
-
- 3.1 conv layers
- 3.2 RPN
-
- 3.2.1 anchors
- 3.2.2 Cls 和 Reg
- 3.2.3 生成Proposal
- 3.3 RoI pooling
-
- 3.3.1 为什么需要RoI pooling
- 3.3.2 RoI pooling原理
- 3.4 多任务损失函数(Multi-task Loss)
- 四 训练过程
- 五 Reference

论文下载地址
一 Preface
1.1 背景:
最先进的对象检测网络依赖于区域建议算法来假设对象位置。 SPPnet 和 Fast R-CNN 等进步减少了这些检测网络的运行时间,但暴露了区域提案计算的瓶颈。(怎么解决呢,产生了本文)
+
在这项工作中,我们引入了一个区域提议网络 (RPN),它与检测网络共享全图像卷积特征,从而实现几乎无成本的区域提议。 RPN 是一种全卷积网络,可同时预测每个位置的对象边界和对象性分数。
1.2 What is RPN (brief)?
RPN 是一种全卷积网络,可同时预测每个位置的对象边界和对象性分数。详细介绍观看下文RPN。
1.3 Faster R-CNN缘由及优点
Answer:
1.我们通过共享 RPN 和 Fast R-CNN 的卷积特征进一步将 RPN 和 Fast R-CNN 合并为一个网络——使用最近流行的具有“注意力”机制的神经网络术语,RPN 组件告诉统一网络去哪里看
2.使用深度卷积神经网络计算提案——导致了一个优雅而有效的解决方案,其中提案计算几乎没有成本给检测网络的计算。
1.4主要创新点
Answer:
1:在Fast R-CNN生成的这些卷积特征之上,我们通过添加一些额外的卷积层来构建一个 RPN,这些卷积层同时回归规则网格上每个位置的区域边界和对象得分。
2:共享卷积层,省去大量计算。
1.5 对比图
Fast R-CNN vs Faster R-CNN
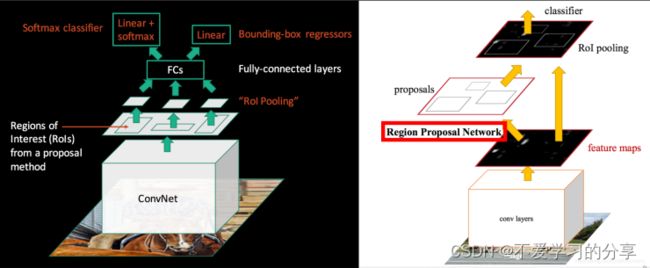
二 Faster R-CNN architecture
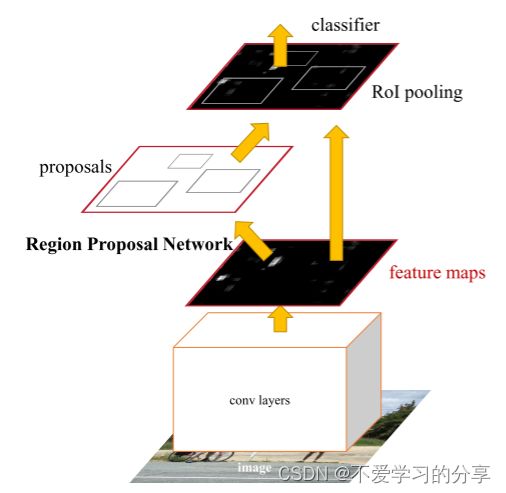
Faster RCNN检测部分主要可以分为四个模块:
一:conv layers即特征提取网络
用于提取特征。通过一组conv+relu+pooling层来提取图像的feature maps,用于后续的RPN层和取proposal。
二:RPN(Region Proposal Network)即区域候选网络
该网络替代了之前RCNN和fast Rcnn版本的Selective Search,用于生成候选框。
这里任务有两部分:
一个是分类:判断所有预设anchor是属于positive还是negative(即anchor内是否有目标,二分类);
一个bounding box regression:修正anchors得到较为准确的proposals。因此,RPN网络相当于提前做了一部分检测,即判断是否有目标(具体什么类别这里不判),以及修正anchor使框的更准一些。
三:RoI Pooling即兴趣域池化
用于收集RPN生成的proposals(每个框的坐标),并从(1)中的feature maps中提取出来(从对应位置扣出来),生成proposals feature maps送入后续全连接层继续做分类(具体是哪一类别)和回归。
四:Classification and Regression
利用proposals feature maps计算出具体类别,同时再做一次bounding box regression获得检测框最终的精确位置。
三 Details
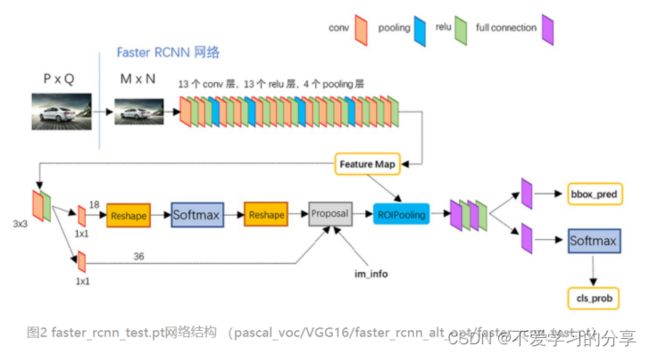
3.1 conv layers
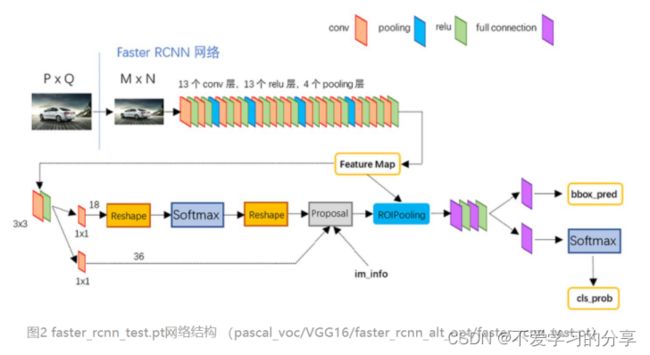
共有13个conv层,13个relu层,4个pooling层
conv:kernel_size=3,padding=1,stride=1
pooling:kernel_size=2,padding=0,stride=2
根据卷积和池化公式可得,经过每个conv层后,feature map大小都不变;经过每个pooling层后,feature map的宽高变为之前的一半。(经过relu层也不变)
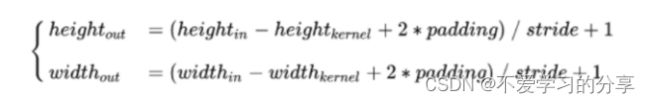 综上,一个MxN大小的图片经过Conv layers之后生成的feature map大小为(M/16)x(N/16)
综上,一个MxN大小的图片经过Conv layers之后生成的feature map大小为(M/16)x(N/16)
3.2 RPN
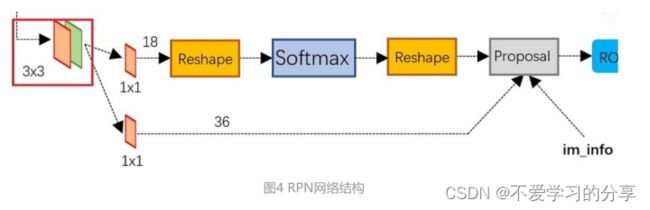
上图展示了RPN结构,有两条线:
上面一条通过softmax分类anchors获得positive和negative分类;
下面一条用于计算对于anchors的bounding box regression偏移量,以获得精确的proposal。
最后的Proposal层则负责综合positive anchors和对应bounding box regression偏移量获取修正后的proposals,同时剔除太小和超出边界的proposals。其实整个网络到了Proposal Layer这里,就完成了相当于目标定位的功能。(只差分具体类别,还有更精准的再次框回归)
3.2.1 anchors
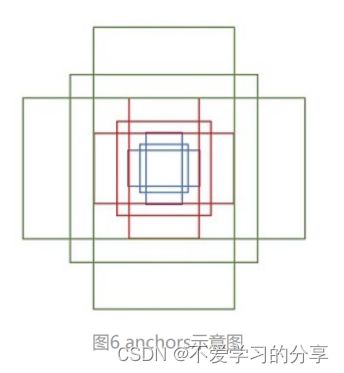
假设原始图片输入大小是MxN,则RPN的输入feature map大小为(M/16)x(N/16)。如上图所示,在这个feature map上,对于每一个像素点,设置9个预设anchor(作者设置的9个)。这9个anchor的大小按照三种长宽比ratio[1:1,1:2,2:1]设置,具体大小根据输入图像的原始目标大小灵活设置。
设置anchor是为了覆盖图像上各个位置各种大小的目标,那么原图上anchor的数量就是(M/16) x (N/16) x 9。这么多anchor,第一肯定不准确,第二肯定不能要这么多,所以后续还会淘汰一大批以及修正anchor位置,最后经过NMS选择。
3.2.2 Cls 和 Reg
Faster RCNN遍历Conv layers计算获得的feature maps,为feature map上每一个点都配备这9种anchors作为初始的检测框。这样做获得检测框很不准确,之后将会在RPN层,以及最后进行2次的bounding box regression修正检测框位置。
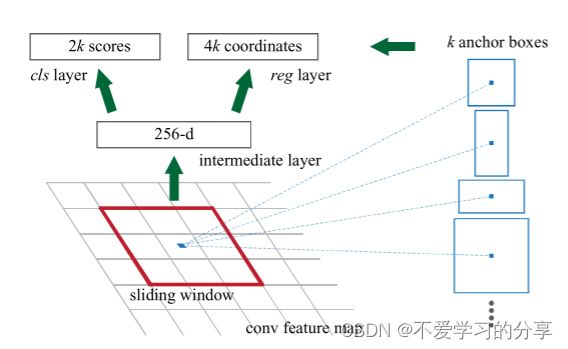
参照上面原文中的图来讲,首先,在拿到conv layers的feature map后,先经过一个3x3卷积(卷积核个数为256)红色框是一个anchor,所以通过这个卷积层后feature map的通道数也是256,k是anchor个数(文中默认是9)。
(M/16)x(N/16)x256的特征通过1x1卷积得到(M/16)x(N/16)x2k的输出,因为这里是二分类判断positive和negative,所以该feature map上每个点的每个anchor对应2个值,表示目标和背景的概率。
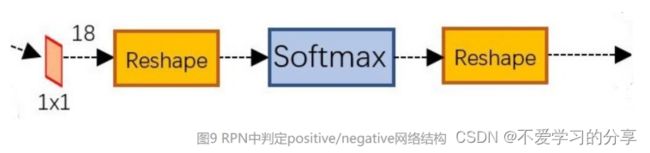
PS:
Reshape层是技术细节问题,对feature map进行维度变换,使得有一个单独的维度为2,方便在该维度上进行softmax操作,之后再Reshape恢复原状。

(M/16)x(N/16)x256的特征通过1x1卷积得到(M/16)x(N/16)x4k的输出,因为这里是生成每个anchor的坐标偏移量(用于修正anchor),[tx,ty,tw,th]共4个所以是4k。注意,这里输出的是坐标偏移量,不是坐标本身,要得到修正后的anchor还要用原坐标和这个偏移量运算一下才行。
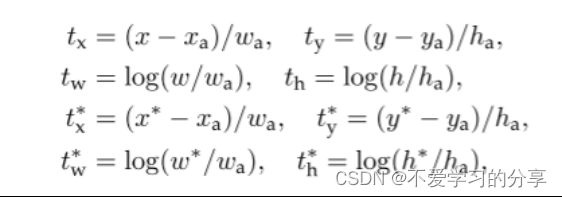
其中 x、y、w 和 h 表示框的中心坐标及其宽度和高度。变量 x、xa 和 x* 分别用于预测框、锚框和真值框(对于 y、w、h 也是如此)。
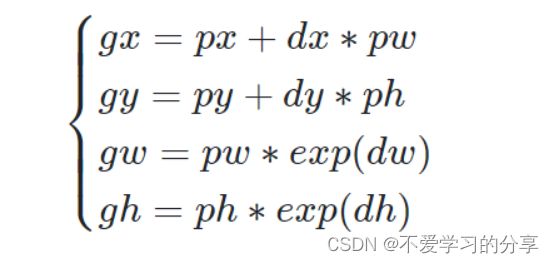
[px,py,pw,ph]表示原始anchor的坐标
[dx,dy,dw,dh]表示RPN网络预测的坐标偏移
[gx,gy,gw,gh]表示修正后的anchor坐标
3.2.3 生成Proposal
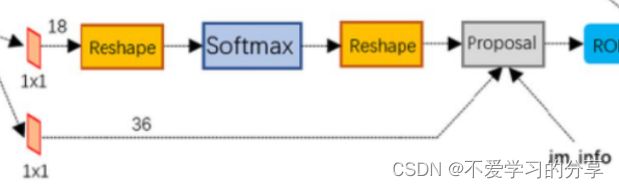
如上图Proposal层,这是RPN里最后一个步骤,输入有三个:
cls层生成的(M/16)x(N/16)x2k向量
reg层生成的(M/16)x(N/16)x4k向量
im_info=[M, N,scale_factor]
(1)利用reg层的偏移量,对所有的原始anchor进行修正
(2)利用cls层的scores,按positive socres由大到小排列所有anchors,取前top N(比如6000个)个anchors
(3)边界处理,把超出图像边界的positive anchor超出的部分收拢到图像边界处,防止后续RoI pooling时proposals超出边界。
(4)剔除尺寸非常小的positive anchor
(5)对剩余的positive anchors进行NMS(非极大抑制)
(6)最后输出一堆proposals左上角和右下角坐标值([x1,y1,x2,y2]对应原图MxN尺度)
3.3 RoI pooling
RoI Pooling层则负责收集proposal,并计算出proposal feature maps(从conv layers后的feature map中扣出对应位置),输入有两个:
(1)conv layers提出的原始特征feature map,大小(M/16)x(N/16)
(2)RPN网络生成的Proposals,大小各不相同。
3.3.1 为什么需要RoI pooling
全连接层的每次输入特征size必须是相同的,而这里得到的proposal大小各不相同。传统的有两种解决办法:
1.从图像从crop(裁剪)一部分送入网络
2.将图像wrap(resize)成需要的大小送入网络
RoI Pooling 只采用单一尺度进行池化。RoI Pooling Layer将不同尺度的feature map下采样到一个固定的尺度feature map(例如77)。
例如对于VGG16网络conv5_3有512个特征图,虽然输入图像的尺寸是任意的,但是通过RoI Pooling Layer后,均会产生一个77*512维度的特征向量作为全连接层的输入。
3.3.2 RoI pooling原理
RoI pooling会有一个预设的pooled_w和pooled_h,表明要把每个proposal特征都统一为这么大的feature map
(1)由于proposals坐标是基于MxN尺度的,先映射回(M/16)x(N/16)尺度
(2)再将每个proposal对应的feature map区域分为pooled_w x pooled_h的网格
(3)对网格的每一部分做max pooling
(4)这样处理后,即使大小不同的proposal输出结果都是pooled_w x pooled_h固定大小,实现了固定长度输出,如下图
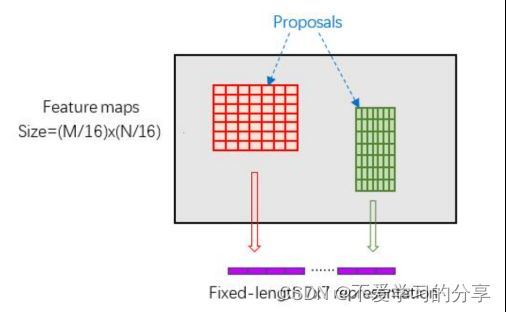
3.4 多任务损失函数(Multi-task Loss)
Faster R-CNN统一了类别输出任务和候选框回归任务,有两个损失函数:分类损失和回归损失。
我们在每个标记的RoI上使用多任务损失L来联合训练分类和边界框回归:公式如下:
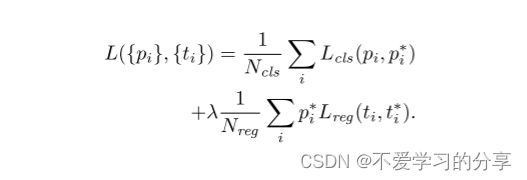

分类损失 Lcls 是两个类的对数损失(对象与非对象)。
对于边界框回归,我们使用如下损失函数:
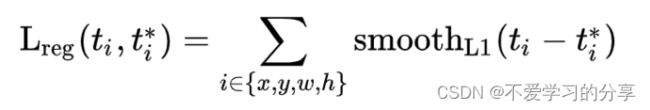
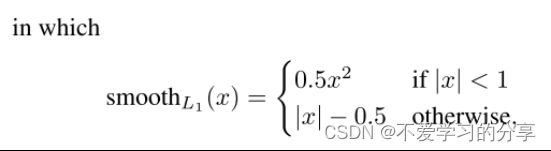
是一种鲁棒的L1损失,它对异常值的敏感度低于r-cnn和SPPnet中使用的L2损失
(
好处:
当回归目标是无界的时,具有L2损失的训练可能需要仔细调整学习率,以防止梯度爆炸。等式smoothL1(x)消除了这种灵敏度。
)
PS:在本文文章实验中,使用lamada=10进行实验。
四 训练过程
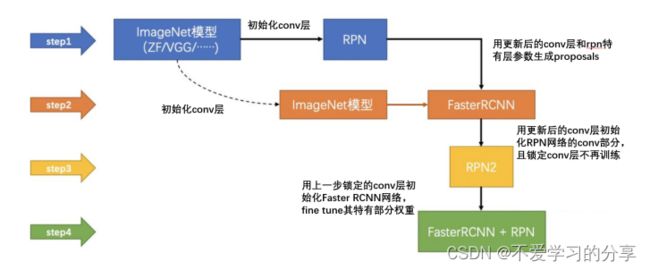
Faster RCNN由于是two-stage检测器,训练要分为两个部分进行,一个是训练RPN网络,一个是训练后面的分类网络。为了清晰描述整个训练过程,首先明确如下两个事实:
RPN网络 = 特征提取conv层(下面简称共享conv层) + RPN特有层(3x3卷积、1x1卷积等)
Faster RCNN网络 = 共享conv层 + Faster RCNN特有层(全连接层)
详细的训练过程如下:
**第一步:**先使用ImageNet的预训练权重初始化RPN网络的共享conv层(RPN特有层可随机初始化),然后训练RPN网络。训练完后,共享conv层和RPN特有层的权重都更新了。
**第二步:**根据训练好的RPN网络拿到proposals(和测试过程一样)
**第三步:**再次使用ImageNet的预训练权重初始化Faster RCNN网络的贡献conv层(Faster RCNN特有层随机初始化),然后训练Faster RCNN网络。训练完后,共享conv层和Faster RCNN特有层的权重都更新了。
**第四步:**使用第三步训练好的共享conv层和第一步训练好的RPN特有层来初始化RPN网络,第二次训练RPN网络。但这次要把共享conv层的权重固定,训练过程中保持不变,只训练RPN特有层的权重。
**第五步:**根据训练好的RPN网络拿到proposals(和测试过程一样)
**第六步:**依然使用第三步训练好的共享conv层和第三步训练好的Faster RCNN特有层来初始化Faster RCNN网络,第二次训练Faster RCNN网络。同样,固定conv层,只fine tune特有部分。
至此核心内容就讲完了
后续的小的细节和实验结果自行看论文,性能和mAP提升了些(但是无非就是性能提升了,精度准确度提高了等等)。
五 Reference
Faster RCNN 论文
参考1
参考2