图神经网络(10)- knowledge graph(知识图谱)
目录
knowledge graph(知识图谱)
Trans 系列
TransE Learning 算法
Connectivity Patterns in KG(知识图谱中的连接模式-关系种类)
TransR Learning 算法
Bilinear Modeling
Bilinear Modeling——DistMult
Bilinear Modeling——ComplEx
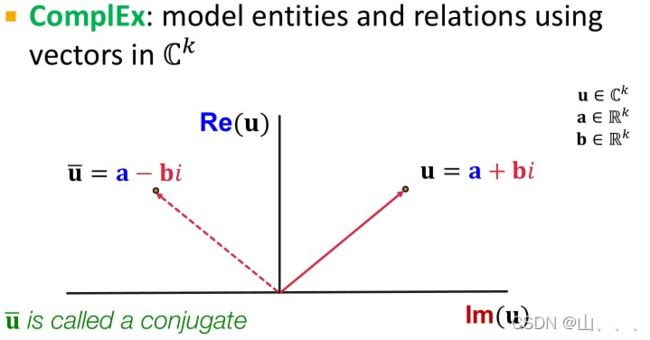
各个模型表达能力总结
在实践中求知识图谱的嵌入
摘要:主要是介绍知识图谱以及一些解决知识图谱问题的经典算法,与GNN关系不大。GNN是现在解决知识图谱问题的一种新方法。
knowledge graph(知识图谱)
知识图谱的介绍,见下面这篇知乎文章。
知识图谱简介 - 知乎知识图谱是什么? 学术一点的定义:知识图谱(Knowledge Graph)本质上是一种叫做语义网络(semantic network)的知识库,即具有有向图结构的一个知识库。通俗一点说:知识图谱是由实体、关系和属性组成的一种数据… https://zhuanlan.zhihu.com/p/441108118知识图可以看作是数据库2.0,是一种异质图,也可以用GNN来处理!
https://zhuanlan.zhihu.com/p/441108118知识图可以看作是数据库2.0,是一种异质图,也可以用GNN来处理!
一般来讲,知识图谱都非常的巨大,并且很难完善(数据太多了,人工很麻烦),所以很自然就演变出一个任务——给你一个不完整的知识图谱,你能把它补全吗?
实际中,知识图谱的节点基本上是完备的,但是会缺少很多不同节点之间的关系,所以补全知识图谱的任务也可以说是边连接预测任务。
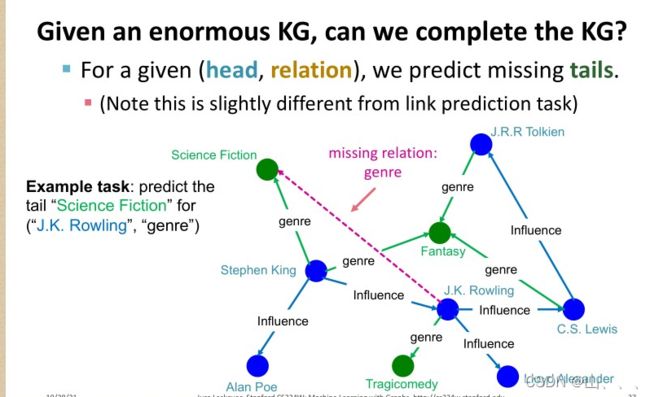
Trans 系列
详细的过程可以参考这篇文章。
基于知识图谱的表示学习——Trans系列算法介绍(一) - 尚码园
主要逻辑就是希望 头向量h与关系r结合起来,要与尾向量r,非常相似(接近)。 trans系列算法的特点就是 利用距离来衡量相似性!
TransE Learning 算法
思路:将知识图谱构建成一个(头实体h,关系r,尾实体t)的三元组形式,经过目标函数将实体和关系分别以低维的向量来表示。TransE的知识图谱表示方法采用函数思想,即|h + r| ≈ t,其中h, t分别表示知识图谱中的头实体和尾实体的向量表示,r表示为关系的向量表示。这个思路可以参考词向量的思路,词向量就是在语料文档的词向量空间寻找相同性质的词,即C(king) – C(queen) ≈ C(man) – C(woman)。词向量空间中的传递是存在不变性。
|h + r| ≈ t,即若是三元组是正确的,则尾实体向量应该与头实体向量和关系向量的加和更为接近;反之,若是三元组是错误的,则尾实体向量应该与头实体向量和关系向量的加和更为远离。
TransE算法的目标函数设计为:
![]()
d(·)表示一种衡量三元组向量表示的距离函数,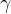 表示的是三元组正例和负例的间隔,为超参,类似于于SVM分类算法中的“间隔”。
表示的是三元组正例和负例的间隔,为超参,类似于于SVM分类算法中的“间隔”。
算法的过程如下:
 算法的过程比较简单:
算法的过程比较简单:
第一步:随机初始化头实体、尾实体和关系向量,对随机初始化的向量作归一化处理;第二步:对数据集中的三元组抽样,并对抽样的三元组进行实体替换,造成负例(生成错误的三元组);第三步:优化目标函数,获得实体和关系的向量表示。
这个算法提出较早,有开创性,但是也有很多问题。具体不深究。
Connectivity Patterns in KG(知识图谱中的连接模式-关系种类)
刚刚以及提过了,不同的实体(节点)之间有很多种类的关系。如下图的对称和逆关系

下面是一些关系的种类——连接方式:

上面的这些概念与离散数学中的 对称 反对称与传递性是相同的。所以按照离散数学的概念去理解这些概念就很容易。其中,逆关系和一对多关系,离散数学没提及。
TransE算法满足反对称性,逆关系,传递性;不满足对称性、一对多关系
TransR Learning 算法
核心:把实体和关系映射到不同的空间。再通过一个投影矩阵转换到同一个空间。(一个关系对应一个投影矩阵)
之前的TransE是把实体和关系映射到同一个空间。
TransR示意图:

TransR满足对称性、反对称性、逆关系、传递性、一对多关系。
Bilinear Modeling
主要逻辑与trans系列算法类似,也就是希望头向量h与关系r结合起来,要与尾向量r,非常相似(接近)。Bilinear Modeling系列算法的特点就是使用cosine相似性——也就是向量相乘!(省略了向量的模)。
Bilinear Modeling——DistMult

Bilinear Modeling——ComplEx
ComplEx 算法就是把实体和关系映射到复数空间,其他的与DistMult差不多。
ComplEx 就是在DistMult的基础上把尾向量t变成共轭。

各个模型表达能力总结
在实践中求知识图谱的嵌入
1.不同的KGs可能有截然不同的关系模式!
2. 没有适用于所有KG的一般嵌入,使用上面的表达能力表来选择模型
3.如果目标KG没有太多的对称关系,试着用TransE快速跑一下。然后使用更具表现力的模型,例如,ComplEx, RotatE(在ComplEx空间中的TransE)