DW-NLP-Task03:基于机器学习的文本分类
在这里插入代码片# 文本表示方法
1.One-hot
将每一个单词使用一个离散的向量表示。具体将每个字/词编码一个索引,然后根据索引进行赋值。
One-hot表示方法的例子如下:
句子1:我 爱 北 京 天 安 门
句子2:我 喜 欢 上 海
首先对所有句子的字进行索引,即将每个字确定一个编号:
{
'我': 1, '爱': 2, '北': 3, '京': 4, '天': 5,
'安': 6, '门': 7, '喜': 8, '欢': 9, '上': 10, '海': 11
}
在这里共包括11个字,因此每个字可以转换为一个11维度稀疏向量:
我:[1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
爱:[0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0]
...
海:[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1]
- 稀疏向量释义
密集向量和稀疏向量的区别: 密集向量的值就是一个普通的Double数组 而稀疏向量由两个并列的 数组indices和values组成 例如:向量(1.0,0.0,1.0,3.0)用密集格式表示为[1.0,0.0,1.0,3.0],用稀疏格式表示为(4,[0,2,3],[1.0,1.0,3.0]) 第一个4表示向量的长度(元素个数),[0,2,3]就是indices数组,[1.0,1.0,3.0]是values数组 表示向量0的位置的值是1.0,2的位置的值是1.0,而3的位置的值是3.0,其他的位置都是0。
稀疏向量通常用两部分表示:一部分是顺序向量,另一部分是值向量。例如稀疏向量(4,0,28,53,0,0,4,8)可用值向量(4,28,53,4,8)和顺序向量(1,0,1,1,0,0,1,1)表示。
2.Bag of Words¶
Bag of Words(词袋表示),也称为Count Vectors,每个文档的字/词可以使用其出现次数来进行表示。
句子1:我 爱 北 京 天 安 门
句子2:我 喜 欢 上 海
直接统计每个字出现的次数,并进行赋值:
句子1:我 爱 北 京 天 安 门
转换为 [1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0]
句子2:我 喜 欢 上 海
转换为 [1, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1]
在sklearn中可以直接CountVectorizer来实现这一步骤:
from sklearn.feature_extraction.text import CountVectorizer
corpus = [
'This is the first document.',
'This document is the second document.',
'And this is the third one.',
'Is this the first document?',
]
vectorizer = CountVectorizer()
'''
CountVectorizer(input='content', encoding='utf-8', decode_error='strict', strip_accents=None, lowercase=True, preprocessor=None, tokenizer=None, stop_words=None,
token_pattern='(?u)\b\w\w+\b', ngram_range=(1, 1), analyzer='word', max_df=1.0, min_df=1, max_features=None, vocabulary=None, binary=False, dtype=)
'''
vectorizer.fit_transform(corpus).toarray()
'''
array([[0, 1, 1, 1, 0, 0, 1, 0, 1],
[0, 2, 0, 1, 0, 1, 1, 0, 1],
[1, 0, 0, 1, 1, 0, 1, 1, 1],
[0, 1, 1, 1, 0, 0, 1, 0, 1]], dtype=int64)
结果发现四个向量中都为1的位置有3个,应为'.''is''the',由此可以推断CountVectorizer是区分大小写的
'''
- 关于CountVectorizer
CountVectorizer是属于常见的特征数值计算类,是一个文本特征提取方法。对于每一个训练文本,它只考虑每种词汇在该训练文本中出现的频率。
CountVectorizer会将文本中的词语转换为词频矩阵,它通过fit_transform函数计算各个词语出现的次数。
参数表、属性表、方法表等其他细节
3.N-gram
N-gram与Count Vectors类似,不过加入了相邻单词组合成为新的单词,并进行计数。
如果N取值为2,则句子1和句子2就变为:
句子1:我爱 爱北 北京 京天 天安 安门
句子2:我喜 喜欢 欢上 上海
4.TF-IDF
TF-IDF 分数由两部分组成:第一部分是词语频率(Term Frequency),第二部分是逆文档频率(Inverse Document Frequency)。其中计算语料库中文档总数除以含有该词语的文档数量,然后再取对数就是逆文档频率。
TF(t)= 该词语在当前文档出现的次数 / 当前文档中词语的总数
IDF(t)= log_e(文档总数 / 出现该词语的文档总数)
基于机器学习的文本分类
接下来我们将对比不同文本表示算法的精度,通过本地构建验证集计算F1得分。
- F1得分
F1分数(F1-score)是分类问题的一个衡量指标。一些多分类问题的机器学习竞赛,常常将F1-score作为最终测评的方法。它是精确率和召回率的调和平均数,最大为1,最小为0。
此外还有F2分数和F0.5分数。F1分数认为召回率和精确率同等重要,F2分数认为召回率的重要程度是精确率的2倍,而F0.5分数认为召回率的重要程度是精确率的一半。计算公式为:
G分数是另一种统一精确率和的召回率系统性能评估标准,G分数被定义为召回率和精确率的几何平均数。
-
精确率(Precision)
精确率是相对于预测结果而言的,它表示的是预测为正的样本中有多少是对的;那么预测为正的样本就有两种可能来源,一种是把正的预测为正的,这类有TruePositive个, 另外一种是把负的错判为正的,这类有FalsePositive个,因此精确率即:P=TP/(TP+FP) -
准确率 (Accuracy)
准确率是指有在所有的判断中有多少判断正确的,即把正的判断为正的,还有把负的判断为负的;总共有 TP + FN + FP + TN 个,所以准确率:(TP+TN) / (TP+TN+FN+FP) -
召回率 (Recall)
召回率是相对于样本而言的,即样本中有多少正样本被预测正确了,这样的有TP个,所有的正样本有两个去向,一个是被判为正的,另一个是错判为负的,因此总共有TP+FN个,所以,召回率 R= TP / (TP+FN)
F1得分计算过程:
1.计算每个类别下的precision和recall
2.通过第1步计算结果计算每个类别下的f1-score,计算方式如下:
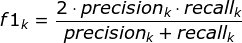
3.通过对第2步求得的各个类别下的F1-score求均值,得到最后的评测结果,计算方式如下:
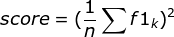
# Count Vectors + RidgeClassifier
import pandas as pd
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.linear_model import RidgeClassifier#岭回归分类器
from sklearn.metrics import f1_score
'''
函数原型:
sklearn.metrics.f1_score(y_true, y_pred, labels=None, pos_label=1, average=’binary’, sample_weight=None)
参数:
y_true : 1d array-like, or label indicator array / sparse matrix.
目标的真实类别。
y_pred : 1d array-like, or label indicator array / sparse matrix.
分类器预测得到的类别。
average : string,[None, ‘binary’(default), ‘micro’, ‘macro’, ‘samples’, ‘weighted’]
这里需要注意,如果是二分类问题则选择参数‘binary’;如果考虑类别的不平衡性,需要计算类别的加权平均,则使用‘weighted’;如果不考虑类别的不平衡性,计算宏平均,则使用‘macro’。
'''
train_df = pd.read_csv('../data/train_set.csv', sep='\t', nrows=15000)
vectorizer = CountVectorizer(max_features=3000)
'''
max_features:默认为None,可设为int,对所有关键词的term frequency进行降序排序,只取前max_features个作为关键词集
此处只提取频率最高的前3000个词
关于CountVectorizer的更多细节参考2.word bag中的链接
'''
train_test = vectorizer.fit_transform(train_df['text'])
'''
fit_transform(raw_documents, y=None):学习词汇词典并返回术语 - 文档矩阵(稀疏矩阵)。
fit和transform没有任何关系,仅仅是数据处理的两个不同环节,之所以出来fit_transform这个函数名,仅仅是为了写代码方便,会高效一点。
fit(): Method calculates the parameters μ and σ and saves them as internal objects.
解释:简单来说,就是求得训练集X的均值,方差,最大值,最小值,这些训练集X固有的属性。
transform(): Method using these calculated parameters apply the transformation to a particular dataset.
解释:在fit的基础上,进行标准化,降维,归一化等操作(看具体用的是哪个工具,如PCA,StandardScaler等)。
fit_transform(): joins the fit() and transform() method for transformation of dataset.
解释:fit_transform是fit和transform的组合,既包括了训练又包含了转换。
transform()和fit_transform()二者的功能都是对数据进行某种统一处理(比如标准化~N(0,1),将数据缩放(映射)到某个固定区间,归一化,正则化等)(归一化,正则化,标准化的解释见后文)
fit_transform(trainData)对部分数据先拟合fit,找到该part的整体指标,如均值、方差、最大值最小值等等(根据具体转换的目的),然后对该trainData进行转换transform,从而实现数据的标准化、归一化等等。
'''
clf = RidgeClassifier()
'''
class sklearn.linear_model.RidgeClassifier(alpha=1.0, *, fit_intercept=True, normalize=False, copy_X=True, max_iter=None, tol=0.001, class_weight=None, solver='auto', random_state=None)
Classifier using Ridge regression.
This classifier first converts the target values into {-1, 1} and then treats the problem as a regression task (multi-output regression in the multiclass case).
详见官方文档:https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.RidgeClassifier.html#sklearn.linear_model.RidgeClassifier
'''
clf.fit(train_test[:10000], train_df['label'].values[:10000])
'''
fit(self, raw_documents, y=None)
Parameters:raw_documents:iterable
An iterable which yields either str, unicode or file objects.
Returns:self
'''
val_pred = clf.predict(train_test[10000:])
print(f1_score(train_df['label'].values[10000:], val_pred, average='macro'))
'''
sklearn.metrics.f1_score(y_true, y_pred, *, labels=None, pos_label=1, average='binary', sample_weight=None, zero_division='warn')
详见官方文档
'''
# 0.74
- 归一化 Normalization
归一化一般是将数据映射到指定的范围,用于去除不同维度数据的量纲以及量纲单位。
常见的映射范围有 [0, 1] 和 [-1, 1] ,最常见的归一化方法就是 Min-Max 归一化:

- 标准化 Normalization
最常见的标准化方法: Z-Score 标准化。

其中μ是样本数据的均值(mean),δ是样本数据的标准差(std)。
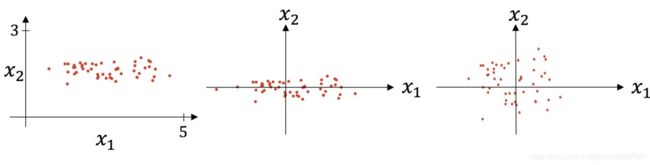
上图则是一个散点序列的标准化过程:原图->减去均值->除以标准差。
显而易见,变成了一个均值为 0 ,方差为 1 的分布,下图通过 Cost 函数让我们更好的理解标准化的作用。
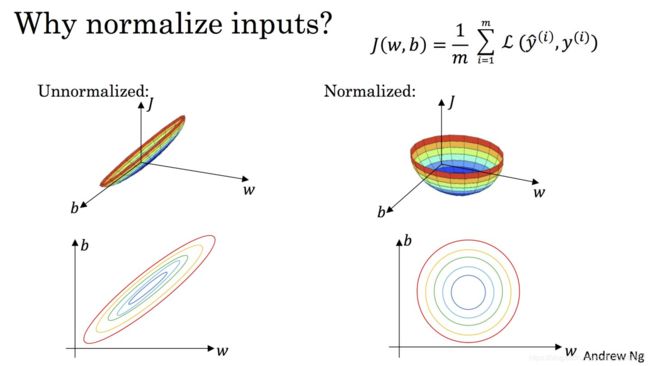
机器学习的目标无非就是不断优化损失函数,使其值最小。在上图中,J(w,b)就是我们要优化的目标函数
损失函数(loss function)或代价函数(cost function)是将随机事件或其有关随机变量的取值映射为非负实数以表示该随机事件的“风险”或“损失”的函数。在应用中,损失函数通常作为学习准则与优化问题相联系,即通过最小化损失函数求解和评估模型。例如在统计学和机器学习中被用于模型的参数估计(parameteric estimation)
我们不难看出,标准化后可以更加容易地得出最优参数w和b以及计算出J(w,b)的最小值,从而达到加速收敛的效果。
正则化 Regularization
正则化主要用于避免过拟合的产生和减少网络误差。
正则化一般具有如下形式:
![[公式]](http://img.e-com-net.com/image/info8/06d93ab197cc4be095b1730af343e5a9.jpg)
其中,第 1 项是经验风险,第 2 项是正则项, [公式] 为调整两者之间关系的系数。
第 1 项的经验风险较小的模型可能较复杂(有多个非零参数),这时第 2 项的模型复杂度会较大。
常见的有正则项有 L1 正则 和 L2 正则 ,其中 L2 正则 的控制过拟合的效果比 L1 正则 的好。
正则化的作用是选择经验风险与模型复杂度同时较小的模型。
# TF-IDF + RidgeClassifier
import pandas as pd
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import RidgeClassifier
from sklearn.metrics import f1_score
train_df = pd.read_csv('../data/train_set.csv', sep='\t', nrows=15000)
tfidf = TfidfVectorizer(ngram_range=(1,3), max_features=3000)
'''
class sklearn.feature_extraction.text.TfidfVectorizer(*, input='content', encoding='utf-8', decode_error='strict', strip_accents=None, lowercase=True, preprocessor=None, tokenizer=None, analyzer='word', stop_words=None, token_pattern='(?u)\b\w\w+\b', ngram_range=(1, 1), max_df=1.0, min_df=1, max_features=None, vocabulary=None, binary=False, dtype=, norm='l2', use_idf=True, smooth_idf=True, sublinear_tf=False)
ngram_range:tuple (min_n, max_n), default=(1, 1)
The lower and upper boundary of the range of n-values for different n-grams to be extracted. All values of n such that min_n <= n <= max_n will be used. For example an ngram_range of (1, 1) means only unigrams, (1, 2) means unigrams and bigrams, and (2, 2) means only bigrams. Only applies if analyzer is not callable.
详见官方文档
'''
train_test = tfidf.fit_transform(train_df['text'])
clf = RidgeClassifier()
clf.fit(train_test[:10000], train_df['label'].values[:10000])
val_pred = clf.predict(train_test[10000:])
print(f1_score(train_df['label'].values[10000:], val_pred, average='macro'))
# 0.87