关于语义分割中一些参数的思考
目录
1. 关于Batch_size
1.1 为什么需要Batch_size 这个参数
1.1 对学习效果的影响
1.2 Batch_size与显存的关系
1.2.1 总体目标
1.2.2 谁占用了显存?
2.2 占用了多少显存?
2. 学习率
3. 学习率与Batch_size的关系
4. Epoch、Batch和Iteration
5. Batch Normalization
6. 关于什么是端到端
1. 关于Batch_size
1.1 为什么需要Batch_size 这个参数
如果没有引入batch_size这一参数,那么在训练过程中所有的训练数据直接输入到网络,经过计算之后得到网络输出值及目标函数值,并以此来调整网络参数使目标函数取极小值。批量梯度下降算法(Batch Gradient Descent)正是这样的原理,注意这里的batch和batch_size中的batch并无直接联系,当然此时也可以理解为batch_size的值恰好等于训练集样本数量。
那么这样做的缺点是什么呢?
首先,当训练集样本非常多时,直接将这些数据输入到神经网络的话会导致计算量非常大,同时对极端集的内存要求也比较高。
其次,当所有样本同时输入到网络中时,往往很难确定一个全局最优学习率使得训练效果最佳。
另外一种极端情况是:每次只读取一个样本作为输入,这种方法称为随机梯度下降算法(Stochastic Gradient Descent, SGD)。这种情况下,可以充分考虑每一个样本的特殊性。但是其缺点同样非常明显:
在每个训练样本上得到的目标函数值差别可能较大,因此最后通过求和或者求平均值的方法而得到的目标函数值不足以代表每个样本。也就是说,这种方法得到的模型对样本的泛化能力差。
为了对两种极端情况进行折衷处理,就有了mini batches这一概念。也就是说每次只输入一定数量的训练样本对模型进行训练,这个数量就是batch_size的大小。
1.1 对学习效果的影响
① Batch_size过小,而类别又比较多的情况,会导致梯度(loss)震荡严重,容易导致不收敛,尤其是网络比较复杂的时候;
②随着Batch_size增大,处理相同数据量越快;
③随着Batch_size增大,达到相同精度所需的epoch越多;
④若Batch_size过大,则可能会出现局部最优的情况,若过小,则引入的随机性更大,难以收敛;
⑤具体Batch_size的选取和样本集的样本数目相关。
1.2 Batch_size与显存的关系
这个主要参考一篇知乎文章:机器学习推理任务 GPU 显存使用分析 - 知乎 (zhihu.com)
科普:科普帖:深度学习中GPU和显存分析 - 知乎 (zhihu.com)
1.2.1 总体目标
使用 GPU 加速机器学习任务时,程序运行时常见的错误 GPU 的显存空间不足:RuntimeError: CUDA Error: out of memory。熟练的炼丹师往往会通过减小 batch size,降低程序对 GPU 显存的需求,使程序正常执行。但是,为什么减小 batch size 可以降低显存需求,是否能够提前预测程序需要的显存大小呢?
1.2.2 谁占用了显存?
当前对机器学习通用的定义是 机器学习 = 数据 + 模型 + 算法。在训练任务中,我们通过在训练集中优化我们的算法,从而获得在验证集或者测试集上表现优异的模型。而在推理任务中,我们使用生成的模型在测试数据上进行前向计算,获得预测的结果。
在推理任务中,占用 GPU 显存的主要包括三个部分:模型权重、输入输出以及中间结果。
- 模型权重:深度学习模型往往是结构相似的 layer 堆砌而成,例如卷积层、池化层、全连接层、激活函数层。一些 layer 是有参数的,例如卷积层的参数是一个高维的卷积核,全连接层的参数是一个二维矩阵。也有一些 layer 没有参数,例如激活函数层、池化层等。
- 中间结果:前向计算中,前一层的输出对应后一层的输入,连接相邻两层的中间结果也需要 GPU 显存来保存。
- 输入输出:相较于模型权重和中间结果,输入输出占用的 GPU 显存比较小
2.2 占用了多少显存?
模型权重、中间结果和输入输出往往都是结构化的数据,在 PyTorch 和 MXNet 等深度学习框架中都是以高维数组的形式保存。因此,我们可以通过数学计算的方式直接求解显存使用情况。

2. 学习率
① 学习率是位于损失函数梯度前,更新网络权重的超参数
梯度下降:new_weight=existing_weight - lr×gradient
② 学习率变换方式

3. 学习率与Batch_size的关系
PS:这是自己百度的,感觉一百度就能看到这些
① 当Batch_size增加为原来的N倍,要保证同样的样本更新后的权重相等,则学习率也增加为原来的N倍;
② 衰减学习率可以通过增加Batch_size实现类似效果;
③ 一个固定的学习率存在一个最优的Batch_size可以最大化测试精度;
④ 一个大的学习率有助于提高模型泛化能力;
⑤ 学习率对模型收敛影响较大,慎重调整!!!
4. Epoch、Batch和Iteration
Epoch:使用训练集的全部数据对模型进行一次完整的训练
Batch:样本集总个数 / Batch_size
Iteration: 1个iteration等于使用batch size个样本训练一次。一个迭代=一个正向通过+一个反向通过。训练一个Batch就是一次Iteration。
5. Batch Normalization
别人搞的很好,参考一下:神经网络学习小记录56——Batch Normalization层的原理与作用_Bubbliiiing的博客-CSDN博客_batchnormalization层的作用
Batch Normalization详解以及pytorch实验_太阳花的小绿豆的博客-CSDN博客_batch normalization pytorch核心思想用下面两张图就能看懂。
BN层的计算公式参考下图:

图1 计算公式
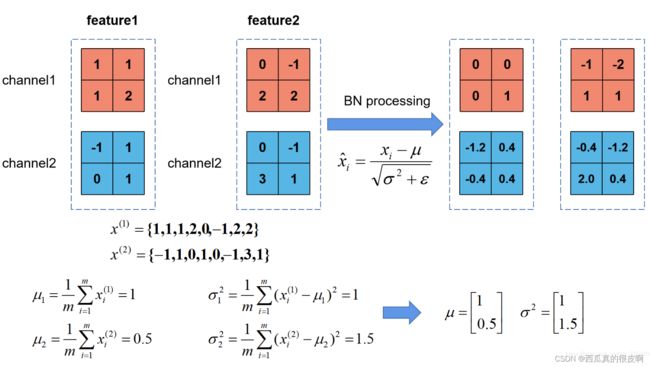
上图展示了一个batch size为2(两张图片)的Batch Normalization的计算过程,假设feature1、feature2分别是由image1、image2经过一系列卷积池化后得到的特征矩阵,feature的channel为2,那么 代表该batch的所有feature的channel1的数据,同理
代表该batch的所有feature的channel1的数据,同理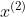 代表该batch的所有feature的channel2的数据。然后分别计算和的均值与方差,得到我们的
代表该batch的所有feature的channel2的数据。然后分别计算和的均值与方差,得到我们的![]() 和
和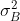 两个向量。然后在根据标准差计算公式分别计算每个channel的值(公式中的
两个向量。然后在根据标准差计算公式分别计算每个channel的值(公式中的 是一个很小的常量,防止分母为零的情况)。在我们训练网络的过程中,我们是通过一个batch一个batch的数据进行训练的,但是我们在预测过程中通常都是输入一张图片进行预测,此时batch size为1,如果在通过上述方法计算均值和方差就没有意义了。所以我们在训练过程中要去不断的计算每个batch的均值和方差,并使用移动平均(moving average)的方法记录统计的均值和方差,在训练完后我们可以近似认为所统计的均值和方差就等于整个训练集的均值和方差。然后在我们验证以及预测过程中,就使用统计得到的均值和方差进行标准化处理。
是一个很小的常量,防止分母为零的情况)。在我们训练网络的过程中,我们是通过一个batch一个batch的数据进行训练的,但是我们在预测过程中通常都是输入一张图片进行预测,此时batch size为1,如果在通过上述方法计算均值和方差就没有意义了。所以我们在训练过程中要去不断的计算每个batch的均值和方差,并使用移动平均(moving average)的方法记录统计的均值和方差,在训练完后我们可以近似认为所统计的均值和方差就等于整个训练集的均值和方差。然后在我们验证以及预测过程中,就使用统计得到的均值和方差进行标准化处理。
细心的同学会发现,在原论文公式中不是还有 ,
, 两个参数吗?是的,是用来调整数值分布的方差大小,是用来调节数值均值的位置。这两个参数是在反向传播过程中学习得到的,的默认值是1,的默认值是0
两个参数吗?是的,是用来调整数值分布的方差大小,是用来调节数值均值的位置。这两个参数是在反向传播过程中学习得到的,的默认值是1,的默认值是0
6. 关于什么是端到端
相比于深度学习,机器学习的流程往往由多个独立模块组成,中间分为多个步骤,每个步骤是一个独立任务,其结果的好坏会影响下一个步骤,从而影响整个训练结果,这是非端到端的。
所谓端到端的学习,就是忽略所有这些不同阶段,用单个神经网络替代它,深度学习在模型训练过程中,从输入端到输出端会得到一个预测结果,与真值相比得到一个误差,误差在模型中每一层传递,每一层再根据误差调整,直到最终收敛,这才是端到端。