机器学习-sklearn模型选择和最优参数选择
写在前言
当你决定调用sklearn中提供的模型去做回归或分类等操作的时候,在不考虑数据优劣的情况下,你就只能依赖sklearn中提供模型和模型对应参数来进行拟合来达到最后的最优结果,这个时候大部分人就会处在我到底选择哪个模型,选择了模型之后我模型参数我该怎么选什么的纠结之中,因为一个模型的选择和参数的选择就决定了你的结果优劣。
比如,你现在要做一个二分类预测,手里有10w左右的数据,在sklearn中你可以选择的模型就很多了,临近、支持向量机、逻辑回归、决策树、集成算法大家族等等,每一种模型我们不仅仅要考虑最后的损失,还要考虑时间等因素,需要多维度的衡量哪种模型更适合。
有些时候我们可以根据数据量、特征数量、经验等方面来缩小模型选择的范围或者直接确定模型,但是这样的情况还是较少的。还有现在集成学习现在的level也比较高,有些人会直接选择集成学习来训练。我们在不考虑这些情况下,来看看有哪些方法可以更好的帮助我们选择模型和对应的参数。
下面详细的介绍常用的方法。
1.模型和参数的选择 ->交叉验证得分cross_val_score
什么是交叉验证?
你现在有一份数据,通常情况下我们会随机将数据分成70%的训练数据和30%的测试数据,但是如果只做一次那么就可能出现以下的问题
1)过拟合或欠拟合的情况
2)没有在有限的数据中获取更多的信息,数据没有被充分利用
3)模型泛化和时间复杂度的问题。
等等。
交叉验证是如何解决上诉问题的?
1、首先,将全部样本划分成k个大小相等的样本子集;
2、依次遍历这k个子集,每次把当前子集作为验证集,其余所有样本作为训练集,进行模型的训练和评估;
3、最后把k次评估指标的平均值作为最终的评估指标。
这样会尽最大可能的利用数据,得出泛化能力强的模型和结果
cross_val_score参数解释
官网
https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.cross_val_score.html#sklearn.model_selection.cross_val_score方法
sklearn.model_selection.cross_val_score(estimator, X, y=None, *, groups=None, scoring=None, cv=None, n_jobs=None, verbose=0, fit_params=None, pre_dispatch='2*n_jobs', error_score=nan)参数解释:
estimator:用于拟合的方法对象
X:自变量数据
Y:因变量数据
groups: 将数据集分割为训练/测试集时使用的样本的组标签(一般用不到)
scoring:这个比较重要,选择验证方式。
官网:https://scikit-learn.org/stable/modules/model_evaluation.html#scoring-parameter
根据模型选择对应的验证方式,
分类问题一般选择‘roc_auc’、‘neg_log_loss’、‘f1’等,根据实际需求选择。
回归问题一般选择‘neg_mean_absolute_error、neg_mean_squared_error、‘r2’等 ,根据实际需求选择。
根据所选的验证方式的结果判断该数据用什么模型更好。
cv: 交叉验证折数或可迭代的次数,就是上面所说的我们将数据分为K份的值,默认为10。
n_jobs: 同时工作的cpu个数(-1代表全部)
verbose: 详细程度
fit_params: 传递给估计器(验证算法)的拟合方法的参数
pre_dispatch: 控制并行执行期间调度的作业数量。减少这个数量对于避免在CPU发送更多作业时CPU内存消耗的扩大是有用的。该参数可以是:
没有,在这种情况下,所有的工作立即创建并产生。将其用于轻量级和快速运行的作业,以避免由于按需产生作业而导致延迟
一个int,给出所产生的总工作的确切数量
一个字符串,给出一个表达式作为n_jobs的函数,如’2 * n_jobs
error_score: 如果在估计器拟合中发生错误,要分配给该分数的值(一般不需要指定)
cross_val_score使用方法
假设我们做一个二分类任务,(下面的代码是我做肿瘤预测的),首先我们导入可做二分类的模型有逻辑回归、ADBT、GDBT,随机森林、临近和svm,最后导入交叉验证的方法
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import AdaBoostClassifier, GradientBoostingClassifier, RandomForestClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import SVC
from sklearn.cross_validation import cross_val_score然后依次建立模型,基本都用模型的默认参数,最后建立一个数组,存入方法,方便循环调用
KnnMod = KNeighborsClassifier()
LrMod = LogisticRegression()
SvmMod = SVC(probability=True)
adaMod = AdaBoostClassifier(base_estimator=None)
gbMod = GradientBoostingClassifier(loss='deviance', learning_rate=0.1, n_estimators=200, subsample=1.0,
min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_depth=3,
init=None, random_state=None, max_features=None, verbose=0)
rfMod = RandomForestClassifier(n_estimators=100, criterion='gini', max_depth=None, min_samples_split=2,
min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features='auto',
max_leaf_nodes=None, bootstrap=True, oob_score=False, n_jobs=1, random_state=None, verbose=0)
mod_list = [KnnMod,LrMod,SvmMod,adaMod,gbMod,rfMod]创建函数,循环每个模型的交叉验证的结果。
def crossDict(funcations,train_x,train_y ,cv,verbose,scr):
valDict={}
for func in funcations:
valScore = cross_val_score(func,train_x,train_y,cv=cv,verbose=verbose,scoring=scr)
valDict[str(func).split('(')[0]] = [valScore.mean(), valScore.std()]
return valDict调用交叉验证的函数,传递参数,折叠10次 选择neg_log_loss损失
csd = crossDict(mod_list,train_x,train_y ,10,1,"neg_log_loss")
print(csd)打印结果,结果有2个输出,一个是均数 一个是标准差,因为我们选择的是neg_log_loss损失,结果越接近0,表示损失越小,模型效果越好,而标准差则是越小则越好。
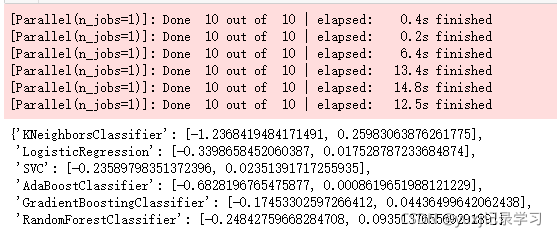
综合来看SVC、 GradientBoostingClassifier效果比较不错,这个可以多测试几次,然后换一换损失函数,比如换成auc,准确度等,多个维度来判断
准确率,均数越接近1越好,标准差越小越好。
auc。均数越接近1越好,标准差越小越好。
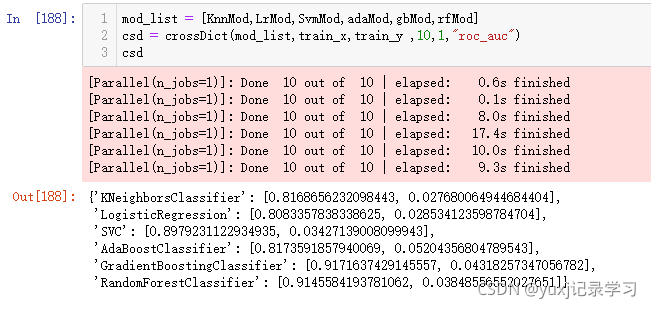
最后我们可以看一下运行速度也是我们需要着重参考维度,综上所述认为GradientBoostingClassifier最好。那么下面我们调试GradientBoostingClassifier的参数,其实cross_val_score也可以用来选择参数,但是有点麻烦不如下面介绍的两种方法更好。
2.参数的选择->RandomizedSearchCV和GridSearchCV
上面介绍了模型的选择方式,其实在选择模型的时候我们可以尝试选择一些确定的参数去交叉验证会更准一些。
我们简单介绍下 RandomizedSearchCV和GridSearchCV,在2.0版本之前,RandomizedSearchCV和GridSearchCV这两个方法的导入是
from sklearn.grid_search import GridsearchCV,RandomizedSearchCV
2.0版本之后 from sklearn.model_selection import GridsearchCV,RandomizedSearchCV,这个需要注意点,别到时候调用不明白了。
RandomizedSearchCV
直译就是随机搜索和折叠
那么RandomSearchCV是如何做到随机搜索的?
考察其源代码,其搜索策略如下:
(a)对于搜索范围是distribution的超参数,根据给定的distribution随机采样;
(b)对于搜索范围是list的超参数,在给定的list中等概率采样;
(c)对a、b两步中得到的n_iter组采样结果,进行遍历。
(补充)如果给定的搜索范围均为list,则不放回抽样n_iter次。
官方代码如下
import numpy as np
from scipy.stats import randint as sp_randint
from sklearn.model_selection import RandomizedSearchCV
from sklearn.datasets import load_digits
from sklearn.ensemble import RandomForestClassifier
# 载入数据
digits = load_digits()
X, y = digits.data, digits.target
# 建立一个分类器或者回归器
clf = RandomForestClassifier(n_estimators=20)
# 给定参数搜索范围:list or distribution
param_dist = {"max_depth": [3, None], #给定list
"max_features": sp_randint(1, 11), #给定distribution
"min_samples_split": sp_randint(2, 11), #给定distribution
"bootstrap": [True, False], #给定list
"criterion": ["gini", "entropy"]} #给定list
# 用RandomSearch+CV选取超参数
n_iter_search = 20
random_search = RandomizedSearchCV(clf, param_distributions=param_dist,
n_iter=n_iter_search, cv=5, iid=False)
random_search.fit(X, y)
RandomizedSearchCV 参数说明
estimator:我们要传入的模型,如KNN,LogisticRegression,RandomForestRegression等。
params_distributions:参数分布,字典格式。将我们所传入模型当中的参数组合为一个字典
n_iter:随机寻找参数组合的数量,默认值为10,我们可以把提供的参数想象成一个M*N的矩阵,在该矩阵中选择n_iter个组合来遍历哪种参数是最优的,如果参数过多,n_iter过少就会有遗漏。
scoring:模型的评估方法。在分类模型中有accuracy,precision,recall_score,roc_auc_score等,在回归模型中有MSE,RMSE等、
cv:交叉验证的折数,最新的sklearn库默认为5
RandomizedSearchCV 的输出
random_search.best_score_,random_search.best_params_
这两个方法一个是打印选取的损失函数分数,一个是最优参数组合GridSearchCV
直译就是网格搜索和折叠
GridSearchCV和RandomizedSearchCV 最大的区别是,GridSearchCV是全部遍历,每个参数每种组合都遍历到,当超参调优的时候,提供的参数过多,那就意味着GridSearchCV需要很长的时间来处理,当然如果参数较少,GridSearchCV也是没问题的。
GridSearchCV参数
estimator:所使用的分类器,或者pipeline
param_grid:值为字典或者列表,即需要最优化的参数的取值
scoring:准确度评价标准,默认None,这时需要使用score函数;或者如scoring='roc_auc',根据所选模型不同,评价准则不同。字符串(函数名),或是可调用对象,需要其函数签名形如:scorer(estimator, X, y);如果是None,则使用estimator的误差估计函数。
n_jobs:并行数,int:个数,-1:跟CPU核数一致, 1:默认值。
pre_dispatch:指定总共分发的并行任务数。当n_jobs大于1时,数据将在每个运行点进行复制,这可能导致OOM,而设置pre_dispatch参数,则可以预先划分总共的job数量,使数据最多被复制pre_dispatch次
iid:默认True,为True时,默认为各个样本fold概率分布一致,误差估计为所有样本之和,而非各个fold的平均。
cv:交叉验证参数,默认None,使用三折交叉验证。指定fold数量,默认为3,也可以是yield训练/测试数据的生成器。
refit:默认为True,程序将会以交叉验证训练集得到的最佳参数,重新对所有可用的训练集与开发集进行,作为最终用于性能评估的最佳模型参数。即在搜索参数结束后,用最佳参数结果再次fit一遍全部数据集。
verbose:日志冗长度,int:冗长度,0:不输出训练过程,1:偶尔输出,>1:对每个子模型都输出。
Attributes:
best_estimator_:效果最好的分类器
best_score_:成员提供优化过程期间观察到的最好的评分
best_params_:描述了已取得最佳结果的参数的组合
best_index_:对应于最佳候选参数设置的索引(cv_results_数组的索引)。
Methods:
decision_function:使用找到的参数最好的分类器调用decision_function。
fit(X, y=None, groups=None, **fit_params):训练
get_params(deep=True):获取这个估计器的参数。
predict(X):用找到的最佳参数调用预估器。(直接预测每个样本属于哪一个类别)
predict_log_proda(X):用找到的最佳参数调用预估器。(得到每个测试集样本在每一个类别的得分取log情况)
predict_proba(X):用找到的最佳参数调用预估器。(得到每个测试集样本在每一个类别的得分情况)
score(X, y=None):返回给定数据上的得分,如果预估器已经选出最优的分类器。
transform(X):调用最优分类器进行对X的转换。
结语:当参数组合少的时候可以考虑GridSearchCV 但是如果多 还是选择RandomizedSearchCV ,打多数情况下 还是得用RandomizedSearchCV