牛客网Mysql题目-SQL进阶篇 SQL110-126
前言
之前在leetcode做mysql题目,发现很多都需要会员权限,只有比较少的开放题目,牛客网相对有很多,在这篇文章下记录
正文
SQL110 插入记录(一)

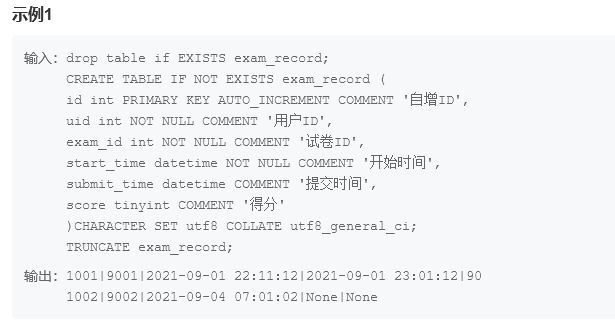
这是一道插入数据题,要求使用一条语句插入两条数据,于是尝试在values后跟两个括号代表两条数据
这里有日期时间,注意要用‘’来引起来日期数据,并且插入语句需要在values前说明字段
insert into exam_record (uid,exam_id,start_time,submit_time,score)values(1001,9001,'2021-09-01 22:11:12','2021-09-01 23:01:12',90),(1002,9002,'2021-09-04 07:01:02',Null,Null);

SQL111 插入记录(二)


题目要求是把一张表的2021年的数据导入另外一张表中,考虑先筛选出符合时间要求的数据,之后insert 嵌套这个select子句
这里遇到一个问题,比较时间的时候一直报错,经过查阅使用日期格式函数
这里还有一套格式
%a 缩写星期名
%b 缩写月名
%c 月,数值
%D 带有英文前缀的月中的天
%d 月的天,数值(00-31)
%e 月的天,数值(0-31)
%f 微秒
%H 小时 (00-23)
%h 小时 (01-12)
%I 小时 (01-12)
%i 分钟,数值(00-59)
%j 年的天 (001-366)
%k 小时 (0-23)
%l 小时 (1-12)
%M 月名
%m 月,数值(00-12)
%p AM 或 PM
%r 时间,12-小时(hh:mm:ss AM 或 PM)
%S 秒(00-59)
%s 秒(00-59)
%T 时间, 24-小时 (hh:mm:ss)
%U 周 (00-53) 星期日是一周的第一天
%u 周 (00-53) 星期一是一周的第一天
%V 周 (01-53) 星期日是一周的第一天,与 %X 使用
%v 周 (01-53) 星期一是一周的第一天,与 %x 使用
%W 星期名
%w 周的天 (0=星期日, 6=星期六)
%X 年,其中的星期日是周的第一天,4 位,与 %V 使用
%x 年,其中的星期一是周的第一天,4 位,与 %v 使用
%Y 年,4 位
%y 年,2 位
但一直执行错误,于是改用year函数,年份小于2021即可,这里注意不需要写values,直接跟着select 子句,括号也不需要
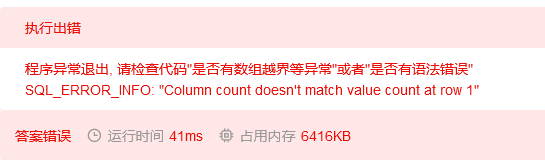
这个报错是因为查出来id,select子句需要去掉id
SQL112 插入记录(三)
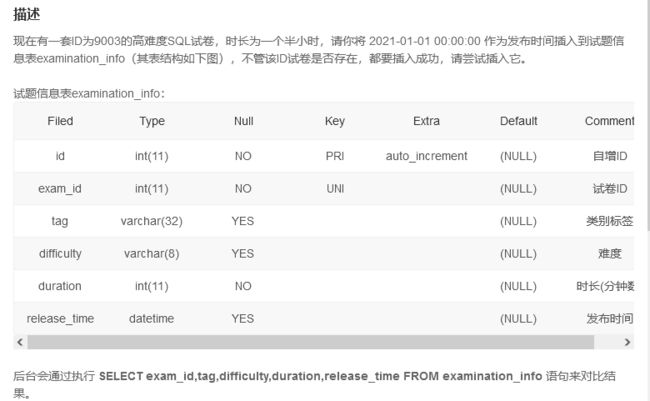

此题目要求插入一条语句,但是已经存在id 为9003的数据,那么可以进行update
但是考虑到如果不存在这个id为9003的数据,where条件就会失效
于是查到一个replace into语法,它会把重复数据删除后再插入
REPLACE INTO examination_info(exam_id,tag,difficulty,duration,release_time) VALUES
(9003, 'SQL', 'hard', 90, '2021-01-01 00:00:00')

SQL113 更新记录(一)
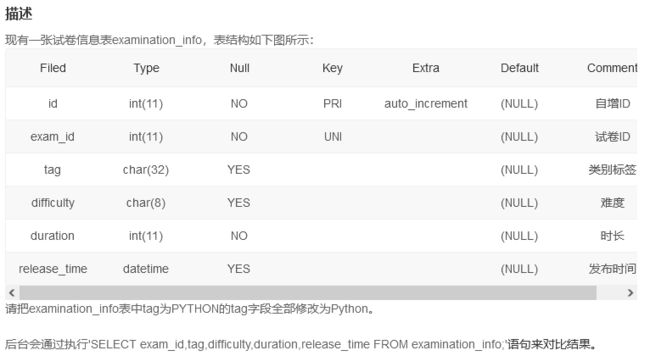

题目要求把tag为PYTHON的字段变为Python
update examination_info set tag = 'Python' where tag ='PYTHON'

SQL114 更新记录(二)
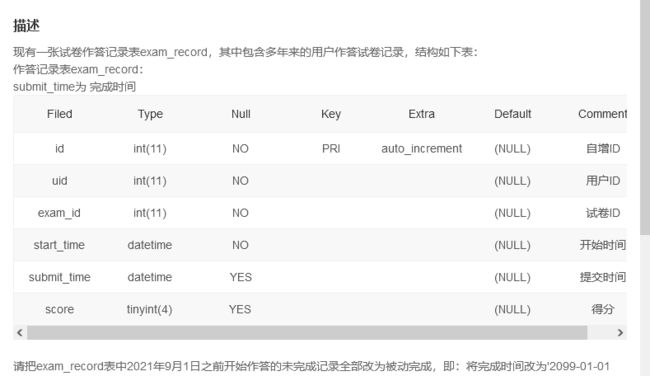
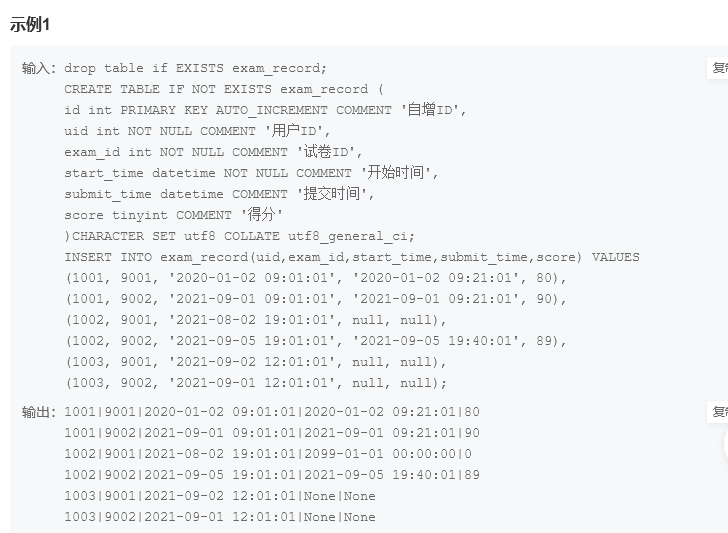
题目要求将2021-09-01前作答且submit为空的数据全部改为2099-01-01,0分
update exam_record set submit_time='2099-01-01',score = 0 where start_time <'2021-09-01' AND submit_time is null

SQL115 删除记录(一)

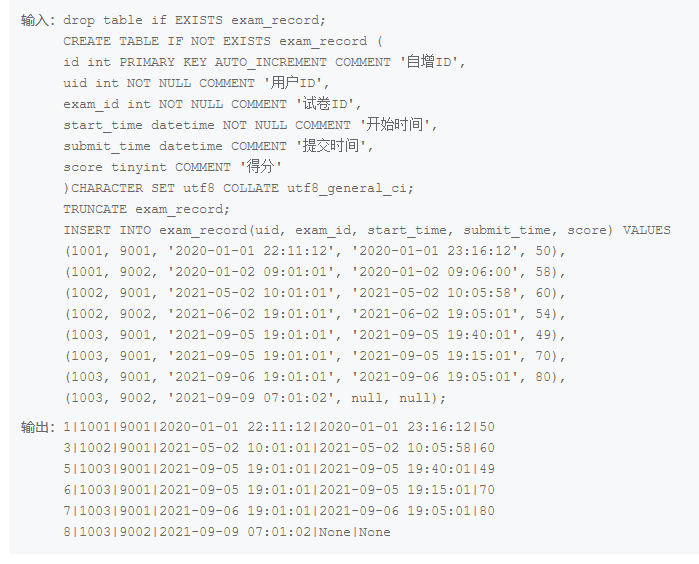
这里查到timestampdiff 函数,可以求一个时间差
delete from exam_record where score<60 AND timestampdiff (minute,start_time,submit_time)<5
SQL116 删除记录(二)

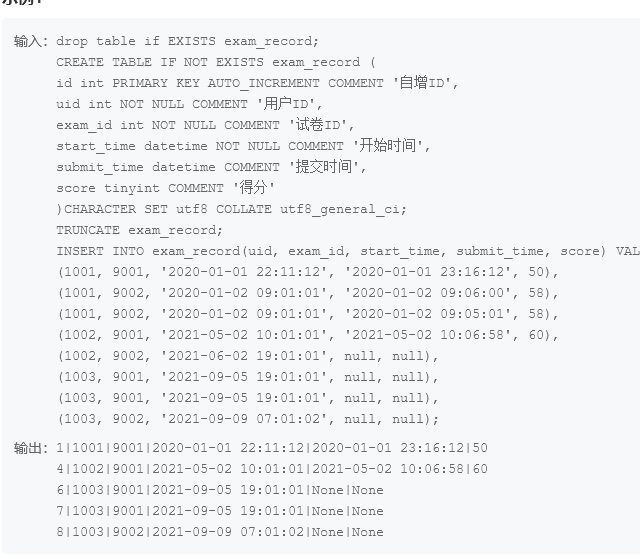
根据题意,取出这样的三条数据
delete from exam_record where id in(
select id from exam_record where timestampdiff(minute,start_time,submit_time) <5 OR submit_time is null order by start_time limit 3)
之后发现报了错,原因是limit不能用在子句里
那就去掉子句,把子句的内容放到外面
delete from exam_record where timestampdiff(minute,start_time,submit_time) <5 OR submit_time is null order by start_time limit 3

说明delete 后面可以进行排序和limit子句
SQL116 删除记录(三)


本题目主要是删除记录,并重置主键,这里之前在业务里碰到过,一些测试的场景里插入的数据之后删除掉,再插入的数据就会跳过一些id值,记得那时用的truncate关键字
truncate exam_record

SQL117 删除记录(三)
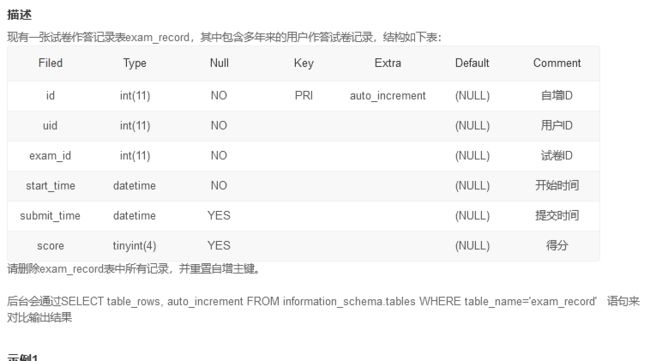
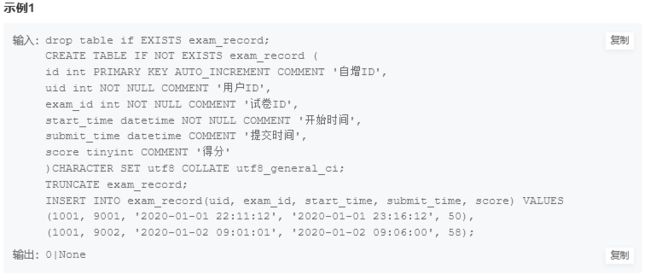
这个在实际做项目时遇到过,使用truncate 可以把id记录也删除,否则新插入的数据id不会从1开始
truncate exam_record
SQL118 创建一张新表
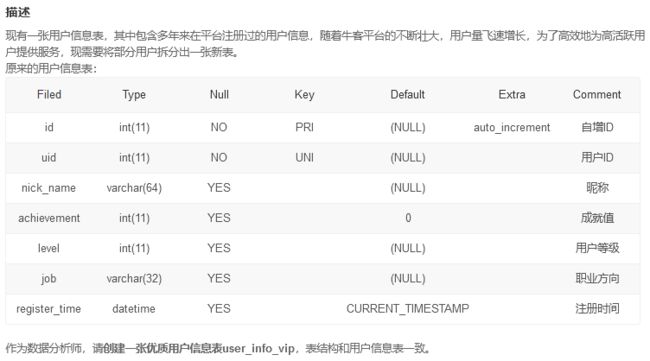
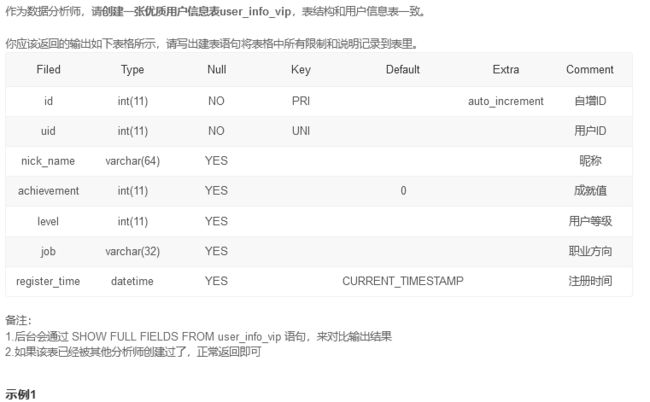
这里使用like复制表一直有问题,对不上default的约束,但是like的说明里讲会完整复制表约束
于是只能用create table手写
CREATE TABLE if not exists user_info_vip
(
id int(11) not null primary key auto_increment Comment '自增ID',
uid int(11) not null unique Comment '用户ID',
nick_name varchar(64) Comment '昵称',
achievement int(11) Default 0 Comment '成就值',
level int(11) Comment '用户等级',
job varchar(32) Comment '职业方向',
register_time datetime Default CURRENT_TIMESTAMP Comment '注册时间'
) CHARACTER SET utf8 COLLATE utf8_general_ci;

SQL119 修改表

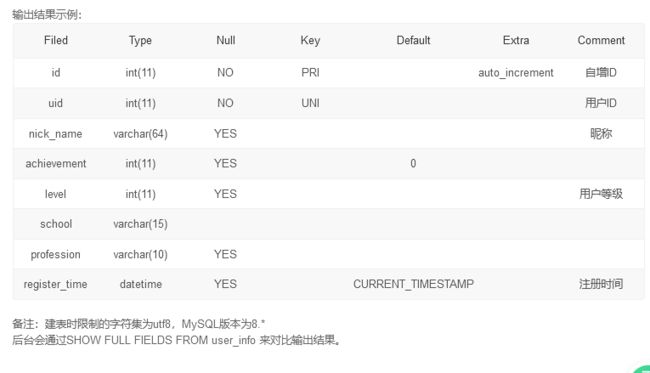
这道题目要求是修改表结构,使用alter
alter table user_info add column school varchar(15) after level;
alter table user_info change job profession varchar(10);
alter table user_info modify achievement int(11) default 0 ;
这里modify报错,改为change,字段的位置写after level ,否则会排到最后

alter的语法主要有几种

SQL120 删除表

本题目要求删掉名字里有2011-2014的表
drop table if exists table_name regexp 'exam_record_201[1234]'
但是好像不能识别,那么就只能穷举了
```sql
drop table if exists exam_record_2011,exam_record_2012,exam_record_2013,exam_record_2014
SQL121 创建索引

本题目是创建三个索引,使用alter table add index 或create index on table都可以
使用索引主要有普通,主键,全文,唯一四种
```sql
create index idx_duration on examination_info (duration );
create unique index uniq_idx_exam_id on examination_info (exam_id );
create fulltext index full_idx_tag on examination_info (tag );
SQL122 删除索引


要求删除两个索引,删除索引是drop index on表名
这里用逗号并列两个索引不行,所以还是两条语句
drop index uniq_idx_exam_id on examination_info;
drop index full_idx_tag on examination_info;
SQL123 SQL类别高难度试卷得分的截断平均值 
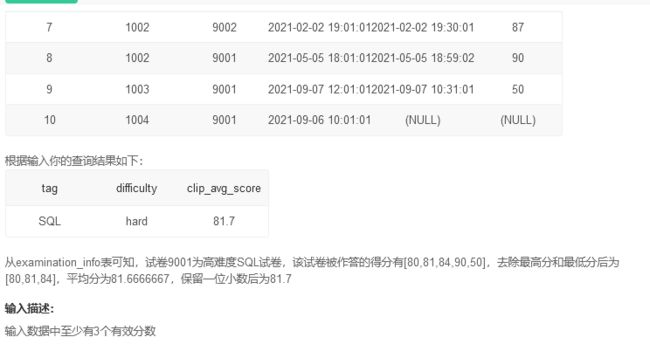
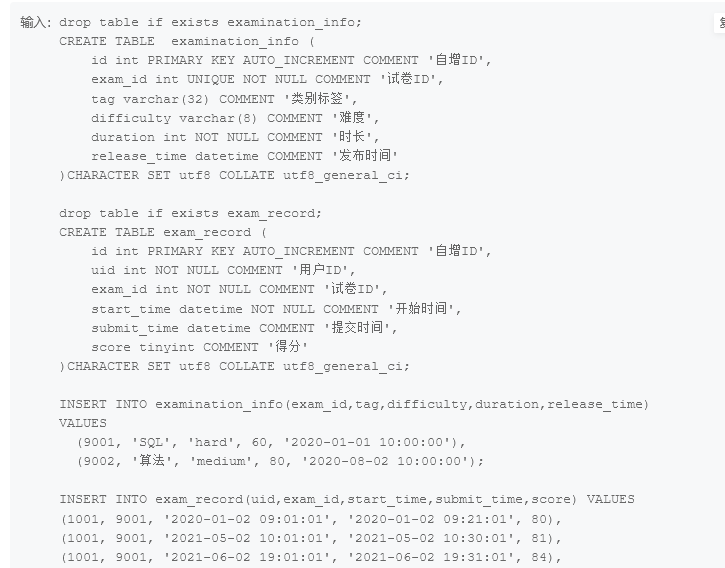
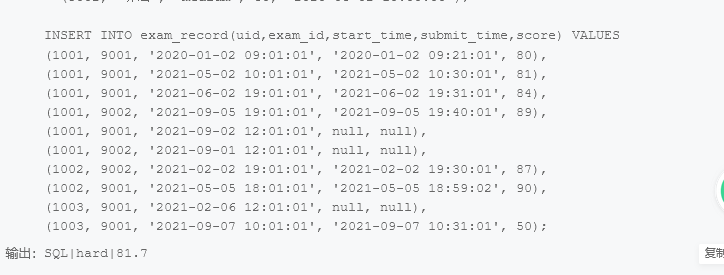
题目要求算出diffculty为hard的数据的score,去掉最高最低分的平均值
打算使用limit去掉首尾,然后group by 计算,首先使用嵌套,发现取不出字段名,于是使用inner join取两表交集
select tag,difficulty ,score from examination_info as ei inner join exam_record as er
on er.exam_id=ei.exam_id
where difficulty='hard' AND tag ='SQL' AND score is not null
这样取出这些数据

之后需要取平均值,就用group by tag
select tag,difficulty ,round((sum(score)-min(score)-MAX(score))/(count(score)-2),1) as clip_avg_score from examination_info as ei inner join exam_record as er
on er.exam_id=ei.exam_id
where tag ='SQL' AND difficulty='hard' AND score is not null
group by tag
这里需要注意的点很多
1.inner join 需要用on限制条件
2. avg函数不能用于行数变化的情况下,直接用除法计算即可
3. round就是保留小数,第二个参数是保留小数点后位数
SQL124 统计作答次数



要求统计三个数量,starttime不为空的记录数 ,submittime不为空的记录数,submittime不为空的记录里试卷编号去重有几种
主要是用count函数统计,但是count需要加上条件,尝试了一下直接在count里加条件就可以
select count(start_time is not null) AS total_pv,count(submit_time is not null ) AS complete_pv , count(distinct(exam_id) AND submit_time is not null) AS complete_exam_cnt from exam_record
这里报错,因为count 其实会过滤掉空行,所以不需要加is not null,修改后
select count(start_time) AS total_pv,count(submit_time ) AS complete_pv , count(distinct(exam_id) AND submit_time is not null ) AS complete_exam_cnt from exam_record

SQL125 得分不小于平均分的最低分
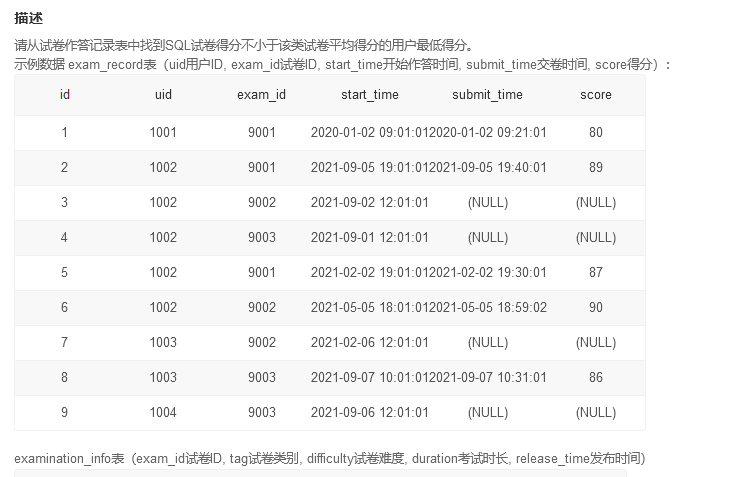
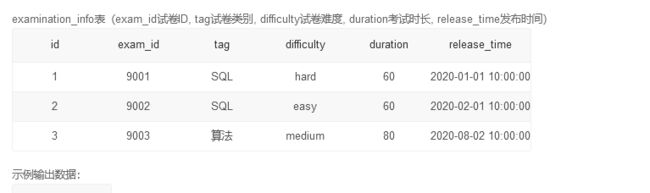
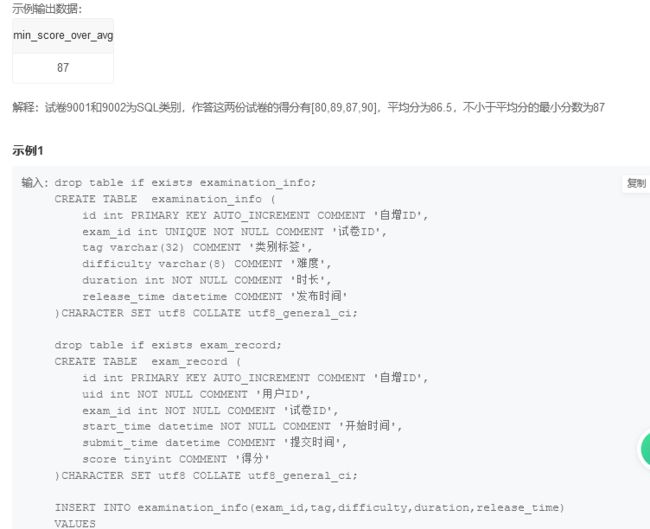
这道题目需要求tag为sql的试卷的得分的平均值,然后找到分数大于这个平均分的分数,然后取最小值
select min(score> =(sum(score)/count(score))) AS min_score_over_avg from
exam_record er inner join examination_info ei on er.exam_id=ei.exam_id
where tag = 'SQL'
起初这样写,发现无法通过,就只能把score作为子查询放在where里
select min(score) AS min_score_over_avg from
exam_record er inner join examination_info ei on er.exam_id=ei.exam_id
where tag = 'SQL' AND score >= (SELECT AVG(score)
FROM exam_record
JOIN examination_info USING(exam_id)
WHERE tag = 'SQL')
这里直接使用avg无论在前还是后都不行,只能放子句里
SQL126 平均活跃天数和月活人数



首先看到是统计多个行,就要用groupby
具体需要统计exam_record去重取出月份 ,每个月份的
后记
后续题目仍然在这篇文章更新