决策树(python)
目录
一、分类决策树
1.决策树的划分依据
2.剪枝(对付"过拟合"的主要⼿段)
3.案例(泰坦尼克号乘客⽣存预测)
4.利弊
二、回归决策树
决策树思想的来源⾮常朴素,程序设计中的条件分⽀结构就是if-else结构。
一、分类决策树
1.决策树的划分依据
信息增益
信息增益率
基尼值和基尼指数
2.剪枝(对付"过拟合"的主要⼿段)
在决策树学习中,为了尽可能正确分类训练样本,结点划分过程将不断重复,有时会造成决策树分⽀过多,这时就可能 因训练样本学得"太好"了,以致于把训练集⾃身的⼀些特点当作所有数据都具有的⼀般性质⽽导致过拟合。因此,可通 过主动去掉⼀些分⽀来降低过拟合的⻛险。
可以通过限制内部节点再划分所需最⼩样本数和决策树最⼤深度来达到剪枝的目的
3.案例(泰坦尼克号乘客⽣存预测)
import pandas as pd
import numpy as np
from sklearn.feature_extraction import DictVectorizer
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier, export_graphviz
#1.获取数据
data = pd.read_csv("F:/数学建模/机器学习/数据/data.csv")
# print(data)
# print(data.describe())
#2.数据基本处理
#2.1确定的特征值和目标值
data_x=data[["Pclass","Age","Sex"]]
data_y=data["Survived"]
# print(data_x)
# print(data_y)
# 2.2确实值得处理
data_x['Age'].fillna(data_x['Age'].mean(), inplace=True) #取平均值处理
# 2.3 数据集划分
x_train,x_test,y_train,y_test=train_test_split(data_x,data_y,random_state=22)
# 3.特征⼯程(字典特征抽取)特征中出现类别符号,需要进⾏one-hot编码处理(DictVectorizer)
transfer=DictVectorizer(sparse=False)
print(x_train.to_dict(orient="records"))
x_train = transfer.fit_transform(x_train.to_dict(orient="records")) #转化为字典类型x_train.to_dict(orient="records")
x_test = transfer.fit_transform(x_test.to_dict(orient="records"))
# 4.决策树模型训练和模型评估
estimator=DecisionTreeClassifier()
estimator.fit(x_train, y_train)
# 4.2评估
print(estimator.score(x_test, y_test))
print(estimator.predict(x_test))
export_graphviz(estimator, out_file="D:/迅雷下载/demo/machineLearnCode/decisionTreeTest/tree.dot", feature_names=['Age', 'Pclass', '⼥性', '男性'])
决策树的图:
打开cmd到
first.dot目录下,运行:dot -Tpng first.dot -o first.png
可以得到画好的图形。
解释:dot表示使用的是dot布局,其他布局相应的修改即可,-T表示格式,即画成png格式,-o表示重命名为first.png。
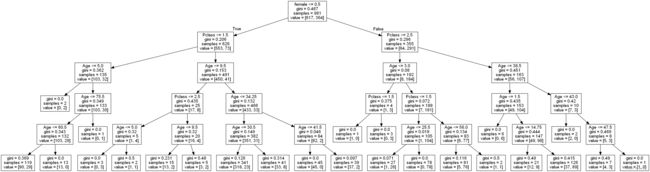
samples属性统计出它应用于多少个训练样本实例
value属性告诉你这个节点对于每一个类别的样例有多少个
4.利弊
优点:简单的理解和解释,树⽊可视化。
缺点 决策树学习者可以创建不能很好地推⼴数据的过于复杂的树,容易发⽣过拟合。
改进: 减枝cart算法
随机森林(集成学习的⼀种)
二、回归决策树
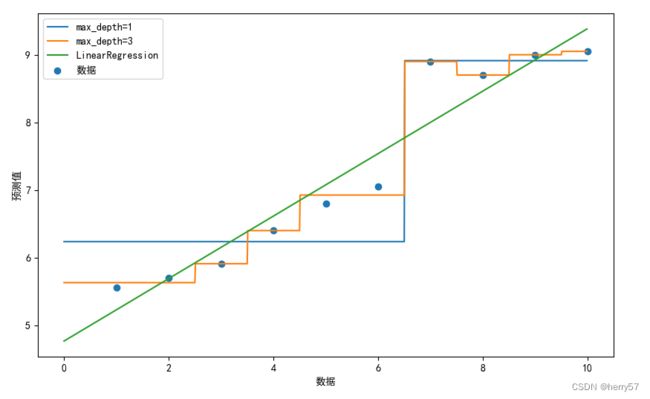
案例

from cProfile import label
import numpy as np
import matplotlib.pyplot as plt
from sklearn.tree import DecisionTreeRegressor
from sklearn.linear_model import LinearRegression
from sympy import plot
# ⽣成数据
x=np.array(list(range(1,11))).reshape(-1,1) #列表转换为矩阵
# print(x)
y = np.array([5.56, 5.70, 5.91, 6.40, 6.80, 7.05, 8.90, 8.70, 9.00, 9.05])
# 训练模型
m1=DecisionTreeRegressor(max_depth=1)
m2=DecisionTreeRegressor(max_depth=3)
m3=LinearRegression()
m1.fit(x,y)
m2.fit(x,y)
m3.fit(x,y)
# 模型预测
x_test=np.arange(0,10,0.01).reshape(-1,1)
# print(x_test)
y1=m1.predict(x_test)
y2=m2.predict(x_test)
y3=m3.predict(x_test)
#显示
# matplotlib.rcParams['font.sans-serif'] = ['SimHei'] # 显示中文
# # 为了坐标轴负号正常显示。matplotlib默认不支持中文,设置中文字体后,负号会显示异常。需要手动将坐标轴负号设为False才能正常显示负号。
# matplotlib.rcParams['axes.unicode_minus'] = False
plt.rcParams['font.sans-serif'] = ['SimHei'] # 显示中文
plt.rcParams['axes.unicode_minus'] = False
plt.figure(figsize=(10,6),dpi=100)
plt.scatter(x,y,label="数据")
plt.plot(x_test,y1,label="max_depth=1")
plt.plot(x_test,y2,label="max_depth=3")
plt.plot(x_test,y3,label="LinearRegression")
plt.xlabel("数据")
plt.ylabel("预测值")
plt.legend()
plt.show()